 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSnowflake: Scaling GNNs to High-Dimensional Continuous Control via Parameter Freezing
Mar 01, 2021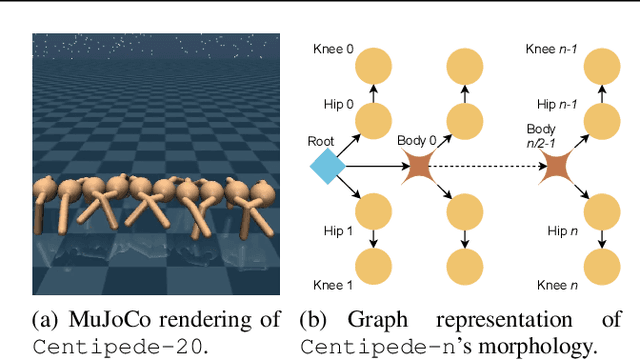
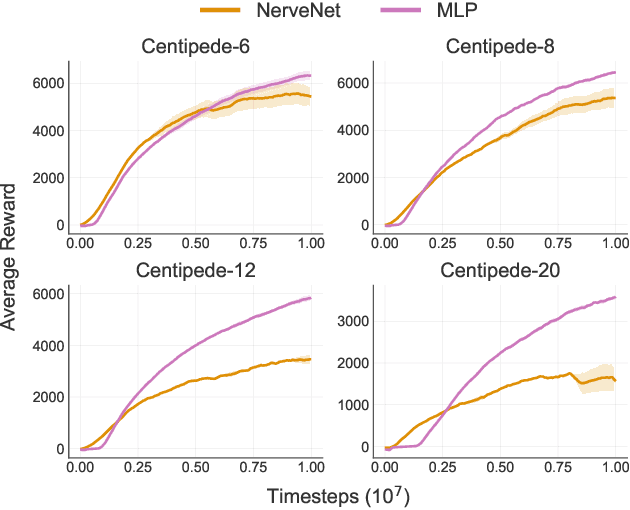
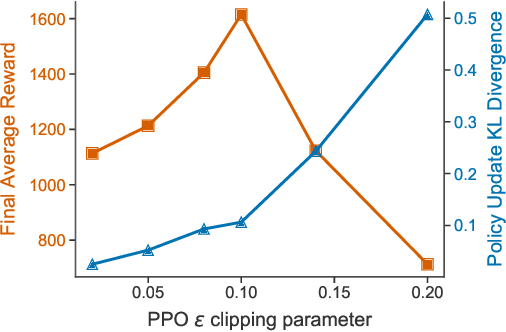
Recent research has shown that Graph Neural Networks (GNNs) can learn policies for locomotion control that are as effective as a typical multi-layer perceptron (MLP), with superior transfer and multi-task performance (Wang et al., 2018; Huang et al., 2020). Results have so far been limited to training on small agents, with the performance of GNNs deteriorating rapidly as the number of sensors and actuators grows. A key motivation for the use of GNNs in the supervised learning setting is their applicability to large graphs, but this benefit has not yet been realised for locomotion control. We identify the weakness with a common GNN architecture that causes this poor scaling: overfitting in the MLPs within the network that encode, decode, and propagate messages. To combat this, we introduce Snowflake, a GNN training method for high-dimensional continuous control that freezes parameters in parts of the network that suffer from overfitting. Snowflake significantly boosts the performance of GNNs for locomotion control on large agents, now matching the performance of MLPs, and with superior transfer properties.
Breaking the Deadly Triad with a Target Network
Feb 09, 2021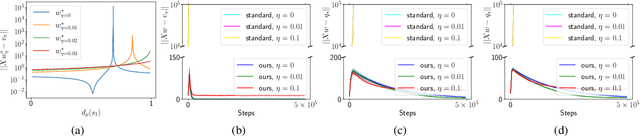


The deadly triad refers to the instability of a reinforcement learning algorithm when it employs off-policy learning, function approximation, and bootstrapping simultaneously. In this paper, we investigate the target network as a tool for breaking the deadly triad, providing theoretical support for the conventional wisdom that a target network stabilizes training. We first propose and analyze a novel target network update rule which augments the commonly used Polyak-averaging style update with two projections. We then apply the target network and ridge regularization in several divergent algorithms and show their convergence to regularized TD fixed points. Those algorithms are off-policy with linear function approximation and bootstrapping, spanning both policy evaluation and control, as well as both discounted and average-reward settings. In particular, we provide the first convergent linear $Q$-learning algorithms under nonrestrictive and changing behavior policies without bi-level optimization.
Deep Interactive Bayesian Reinforcement Learning via Meta-Learning
Jan 11, 2021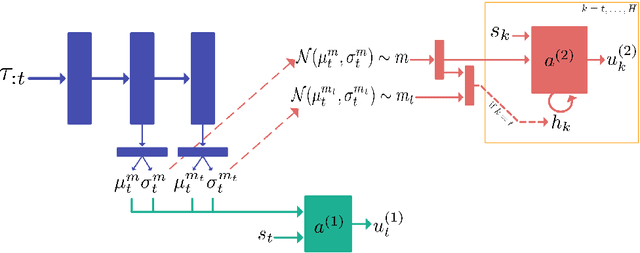
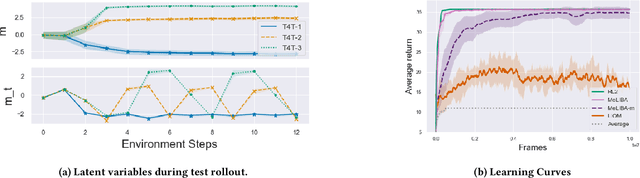
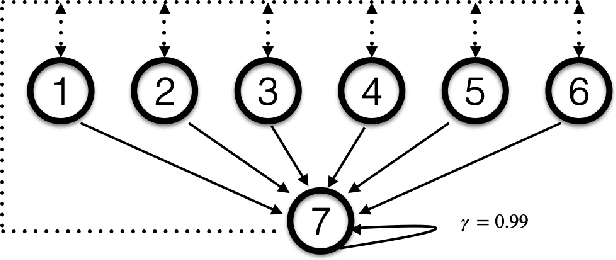
Agents that interact with other agents often do not know a priori what the other agents' strategies are, but have to maximise their own online return while interacting with and learning about others. The optimal adaptive behaviour under uncertainty over the other agents' strategies w.r.t. some prior can in principle be computed using the Interactive Bayesian Reinforcement Learning framework. Unfortunately, doing so is intractable in most settings, and existing approximation methods are restricted to small tasks. To overcome this, we propose to meta-learn approximate belief inference and Bayes-optimal behaviour for a given prior. To model beliefs over other agents, we combine sequential and hierarchical Variational Auto-Encoders, and meta-train this inference model alongside the policy. We show empirically that our approach outperforms existing methods that use a model-free approach, sample from the approximate posterior, maintain memory-free models of others, or do not fully utilise the known structure of the environment.
Average-Reward Off-Policy Policy Evaluation with Function Approximation
Jan 08, 2021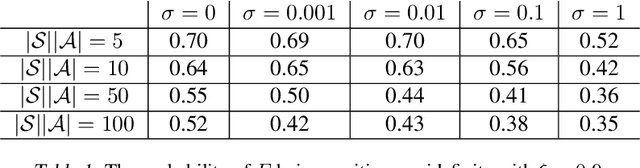
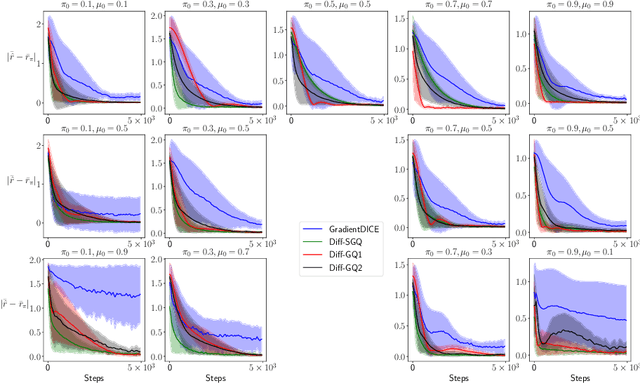
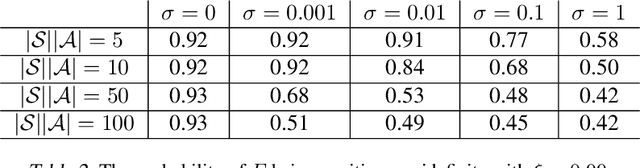
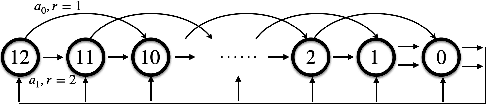
We consider off-policy policy evaluation with function approximation (FA) in average-reward MDPs, where the goal is to estimate both the reward rate and the differential value function. For this problem, bootstrapping is necessary and, along with off-policy learning and FA, results in the deadly triad (Sutton & Barto, 2018). To address the deadly triad, we propose two novel algorithms, reproducing the celebrated success of Gradient TD algorithms in the average-reward setting. In terms of estimating the differential value function, the algorithms are the first convergent off-policy linear function approximation algorithms. In terms of estimating the reward rate, the algorithms are the first convergent off-policy linear function approximation algorithms that do not require estimating the density ratio. We demonstrate empirically the advantage of the proposed algorithms, as well as their nonlinear variants, over a competitive density-ratio-based approach, in a simple domain as well as challenging robot simulation tasks.
Is Independent Learning All You Need in the StarCraft Multi-Agent Challenge?
Nov 18, 2020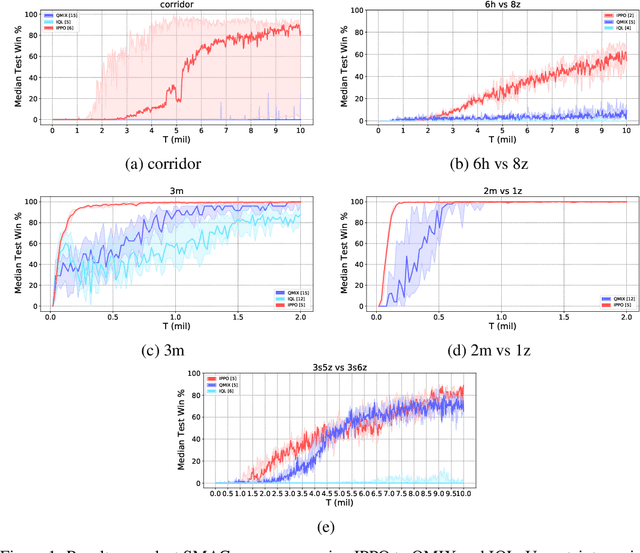
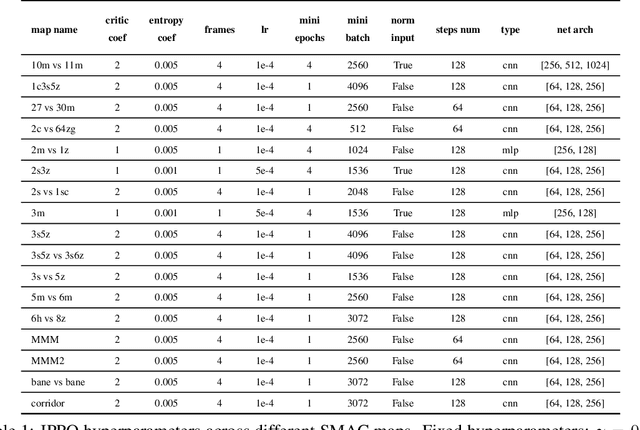

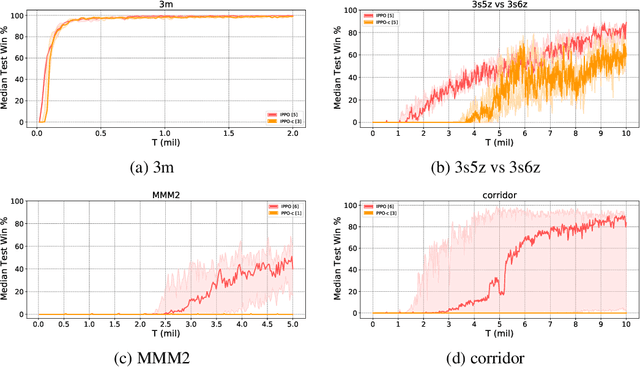
Most recently developed approaches to cooperative multi-agent reinforcement learning in the \emph{centralized training with decentralized execution} setting involve estimating a centralized, joint value function. In this paper, we demonstrate that, despite its various theoretical shortcomings, Independent PPO (IPPO), a form of independent learning in which each agent simply estimates its local value function, can perform just as well as or better than state-of-the-art joint learning approaches on popular multi-agent benchmark suite SMAC with little hyperparameter tuning. We also compare IPPO to several variants; the results suggest that IPPO's strong performance may be due to its robustness to some forms of environment non-stationarity.
UneVEn: Universal Value Exploration for Multi-Agent Reinforcement Learning
Oct 06, 2020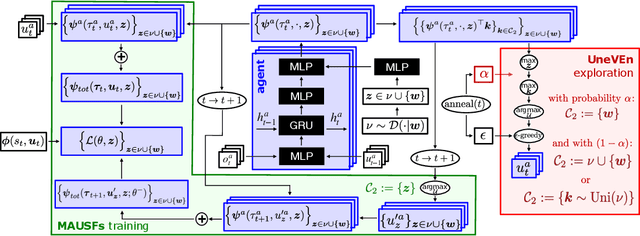
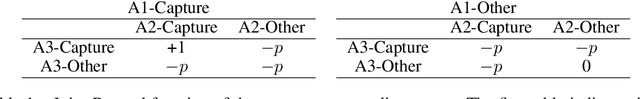
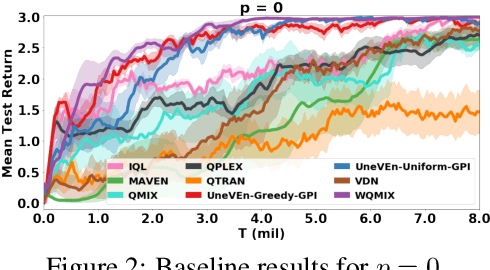
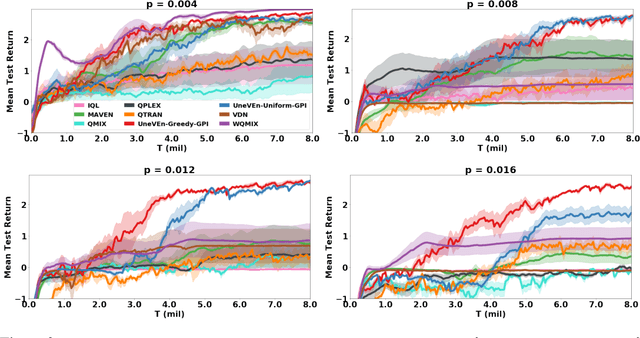
This paper focuses on cooperative value-based multi-agent reinforcement learning (MARL) in the paradigm of centralized training with decentralized execution (CTDE). Current state-of-the-art value-based MARL methods leverage CTDE to learn a centralized joint-action value function as a monotonic mixing of each agent's utility function, which enables easy decentralization. However, this monotonic restriction leads to inefficient exploration in tasks with nonmonotonic returns due to suboptimal approximations of the values of joint actions. To address this, we present a novel MARL approach called Universal Value Exploration (UneVEn), which uses universal successor features (USFs) to learn policies of tasks related to the target task, but with simpler reward functions in a sample efficient manner. UneVEn uses novel action-selection schemes between randomly sampled related tasks during exploration, which enables the monotonic joint-action value function of the target task to place more importance on useful joint actions. Empirical results on a challenging cooperative predator-prey task requiring significant coordination amongst agents show that UneVEn significantly outperforms state-of-the-art baselines.
My Body is a Cage: the Role of Morphology in Graph-Based Incompatible Control
Oct 05, 2020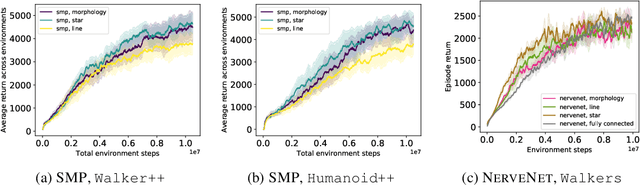

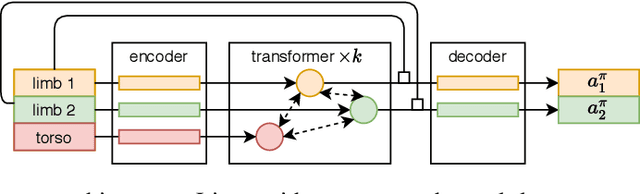
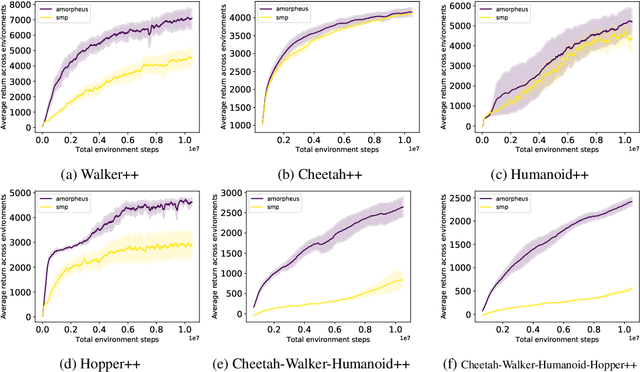
Multitask Reinforcement Learning is a promising way to obtain models with better performance, generalisation, data efficiency, and robustness. Most existing work is limited to compatible settings, where the state and action space dimensions are the same across tasks. Graph Neural Networks (GNN) are one way to address incompatible environments, because they can process graphs of arbitrary size. They also allow practitioners to inject biases encoded in the structure of the input graph. Existing work in graph-based continuous control uses the physical morphology of the agent to construct the input graph, i.e., encoding limb features as node labels and using edges to connect the nodes if their corresponded limbs are physically connected. In this work, we present a series of ablations on existing methods that show that morphological information encoded in the graph does not improve their performance. Motivated by the hypothesis that any benefits GNNs extract from the graph structure are outweighed by difficulties they create for message passing, we also propose Amorpheus, a transformer-based approach. Further results show that, while Amorpheus ignores the morphological information that GNNs encode, it nonetheless substantially outperforms GNN-based methods.
RODE: Learning Roles to Decompose Multi-Agent Tasks
Oct 04, 2020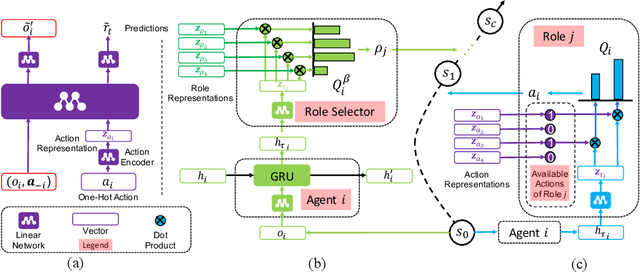

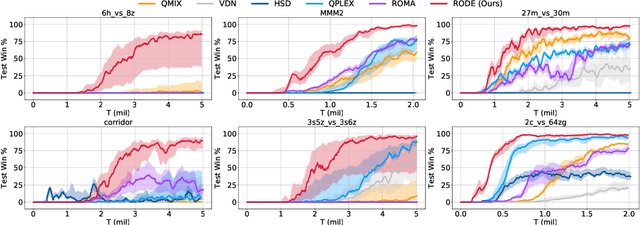
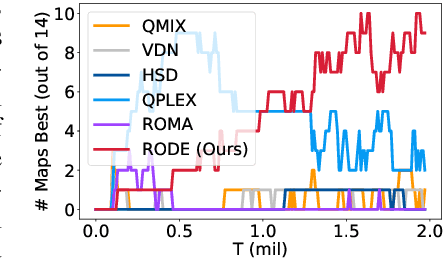
Role-based learning holds the promise of achieving scalable multi-agent learning by decomposing complex tasks using roles. However, it is largely unclear how to efficiently discover such a set of roles. To solve this problem, we propose to first decompose joint action spaces into restricted role action spaces by clustering actions according to their effects on the environment and other agents. Learning a role selector based on action effects makes role discovery much easier because it forms a bi-level learning hierarchy -- the role selector searches in a smaller role space and at a lower temporal resolution, while role policies learn in significantly reduced primitive action-observation spaces. We further integrate information about action effects into the role policies to boost learning efficiency and policy generalization. By virtue of these advances, our method (1) outperforms the current state-of-the-art MARL algorithms on 10 of the 14 scenarios that comprise the challenging StarCraft II micromanagement benchmark and (2) achieves rapid transfer to new environments with three times the number of agents. Demonstrative videos are available at https://sites.google.com/view/rode-marl .
A Deeper Look at Discounting Mismatch in Actor-Critic Algorithms
Oct 02, 2020
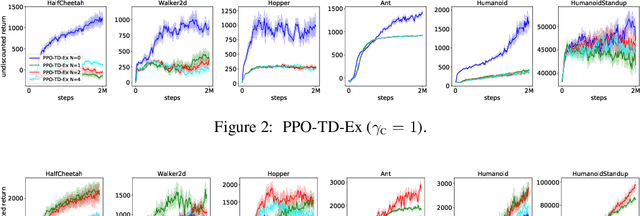
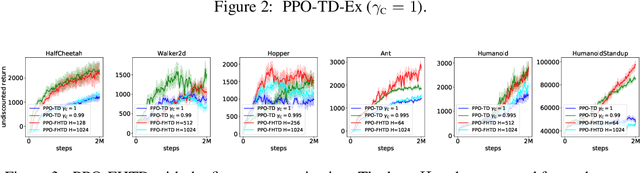

We investigate the discounting mismatch in actor-critic algorithm implementations from a representation learning perspective. Theoretically, actor-critic algorithms usually have discounting for both actor and critic, i.e., there is a $\gamma^t$ term in the actor update for the transition observed at time $t$ in a trajectory and the critic is a discounted value function. Practitioners, however, usually ignore the discounting ($\gamma^t$) for the actor while using a discounted critic. We investigate this mismatch in two scenarios. In the first scenario, we consider optimizing an undiscounted objective $(\gamma = 1)$ where $\gamma^t$ disappears naturally $(1^t = 1)$. We then propose to interpret the discounting in critic in terms of a bias-variance-representation trade-off and provide supporting empirical results. In the second scenario, we consider optimizing a discounted objective ($\gamma < 1$) and propose to interpret the omission of the discounting in the actor update from an auxiliary task perspective and provide supporting empirical results.
Exploration in Approximate Hyper-State Space for Meta Reinforcement Learning
Oct 02, 2020
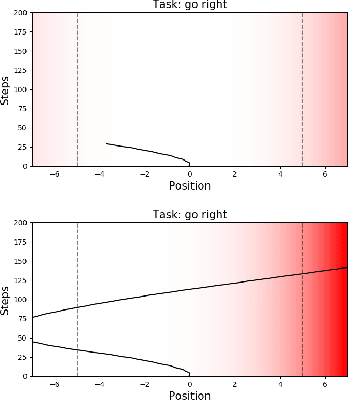

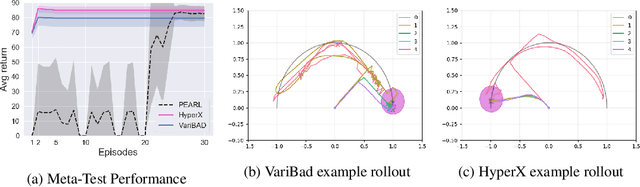
Meta-learning is a powerful tool for learning policies that can adapt efficiently when deployed in new tasks. If however the meta-training tasks have sparse rewards, the need for exploration during meta-training is exacerbated given that the agent has to explore and learn across many tasks. We show that current meta-learning methods can fail catastrophically in such environments. To address this problem, we propose HyperX, a novel method for meta-learning in sparse reward tasks. Using novel reward bonuses for meta-training, we incentivise the agent to explore in approximate hyper-state space, i.e., the joint state and approximate belief space, where the beliefs are over tasks. We show empirically that these bonuses allow an agent to successfully learn to solve sparse reward tasks where existing meta-learning methods fail.