 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSRPO: A Cross-Domain Implementation of Large-Scale Reinforcement Learning on LLM
Apr 22, 2025



Recent advances of reasoning models, exemplified by OpenAI's o1 and DeepSeek's R1, highlight the significant potential of Reinforcement Learning (RL) to enhance the reasoning capabilities of Large Language Models (LLMs). However, replicating these advancements across diverse domains remains challenging due to limited methodological transparency. In this work, we present two-Staged history-Resampling Policy Optimization (SRPO), which surpasses the performance of DeepSeek-R1-Zero-32B on the AIME24 and LiveCodeBench benchmarks. SRPO achieves this using the same base model as DeepSeek (i.e. Qwen2.5-32B), using only about 1/10 of the training steps required by DeepSeek-R1-Zero-32B, demonstrating superior efficiency. Building upon Group Relative Policy Optimization (GRPO), we introduce two key methodological innovations: (1) a two-stage cross-domain training paradigm designed to balance the development of mathematical reasoning and coding proficiency, and (2) History Resampling (HR), a technique to address ineffective samples. Our comprehensive experiments validate the effectiveness of our approach, offering valuable insights into scaling LLM reasoning capabilities across diverse tasks.
Directed-Weighting Group Lasso for Eltwise Blocked CNN Pruning
Oct 21, 2019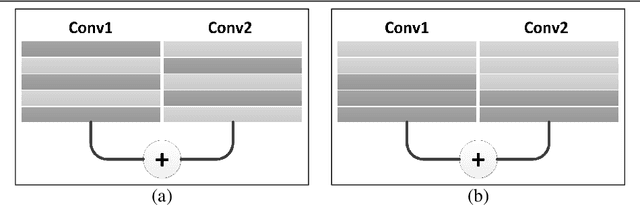
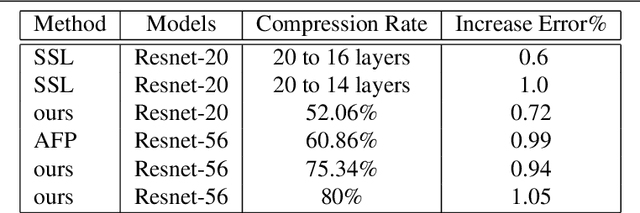
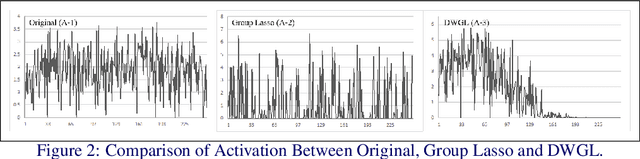
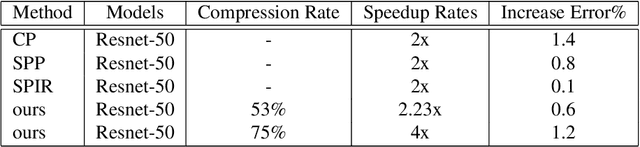
Eltwise layer is a commonly used structure in the multi-branch deep learning network. In a filter-wise pruning procedure, due to the specific operation of the eltwise layer, all its previous convolutional layers should vote for which filters by index should be pruned. Since only an intersection of the voted filters is pruned, the compression rate is limited. This work proposes a method called Directed-Weighting Group Lasso (DWGL), which enforces an index-wise incremental (directed) coefficient on the filterlevel group lasso items, so that the low index filters getting high activation tend to be kept while the high index ones tend to be pruned. When using DWGL, much fewer filters are retained during the voting process and the compression rate can be boosted. The paper test the proposed method on the ResNet series networks. On CIFAR-10, it achieved a 75.34% compression rate on ResNet-56 with a 0.94% error increment, and a 52.06% compression rate on ResNet-20 with a 0.72% error increment. On ImageNet, it achieved a 53% compression rate with ResNet-50 with a 0.6% error increment, speeding up the network by 2.23 times. Furthermore, it achieved a 75% compression rate on ResNet-50 with a 1.2% error increment, speeding up the network by 4 times.