 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Cross Residual Learning for Multitask Visual Recognition
Jul 20, 2016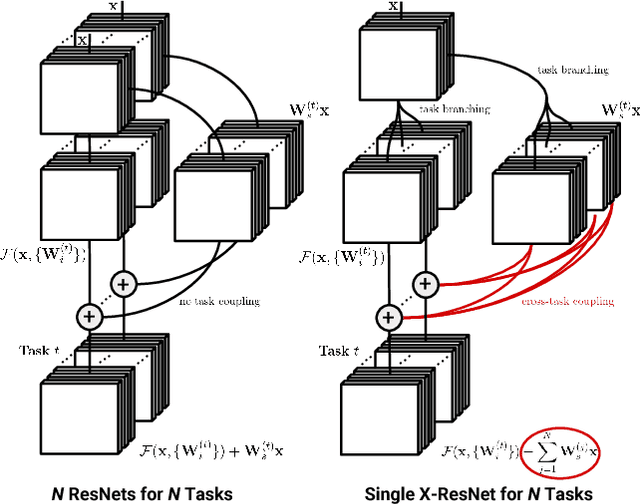
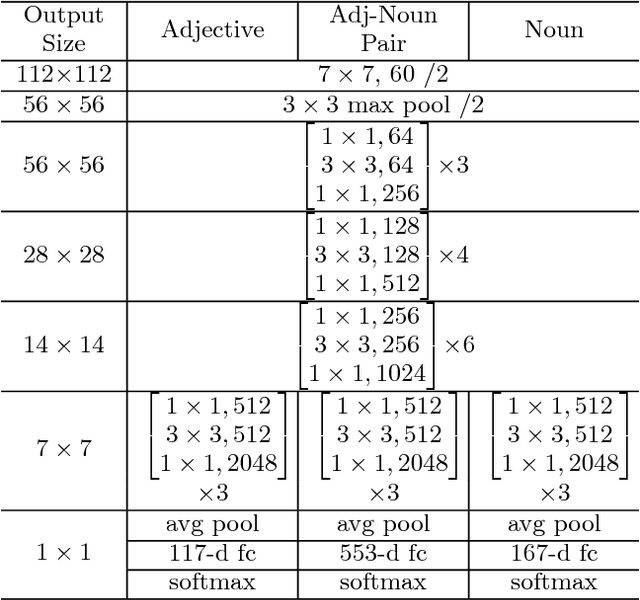
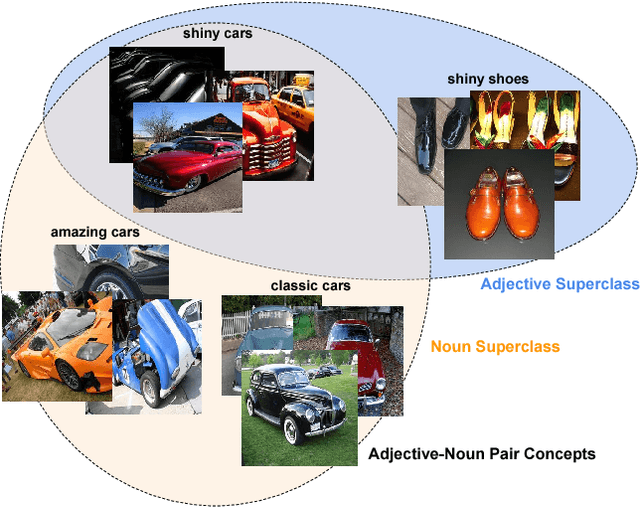
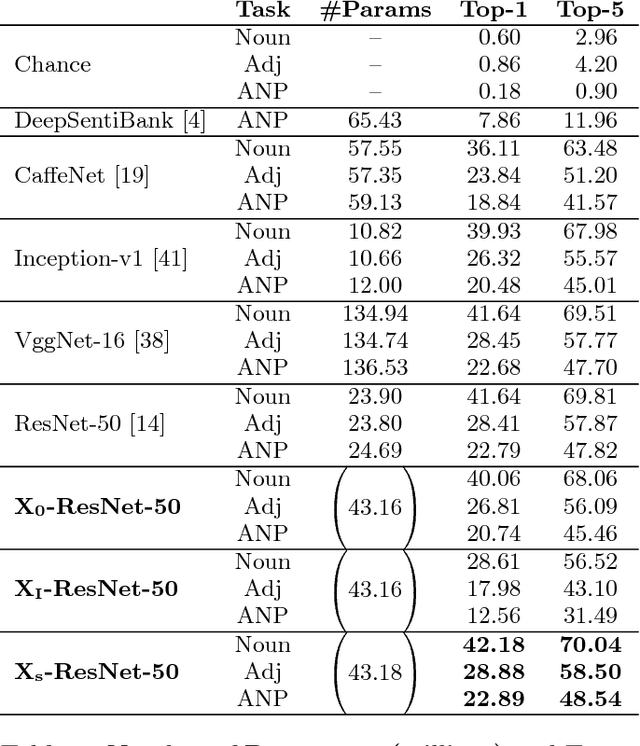
Residual learning has recently surfaced as an effective means of constructing very deep neural networks for object recognition. However, current incarnations of residual networks do not allow for the modeling and integration of complex relations between closely coupled recognition tasks or across domains. Such problems are often encountered in multimedia applications involving large-scale content recognition. We propose a novel extension of residual learning for deep networks that enables intuitive learning across multiple related tasks using cross-connections called cross-residuals. These cross-residuals connections can be viewed as a form of in-network regularization and enables greater network generalization. We show how cross-residual learning (CRL) can be integrated in multitask networks to jointly train and detect visual concepts across several tasks. We present a single multitask cross-residual network with >40% less parameters that is able to achieve competitive, or even better, detection performance on a visual sentiment concept detection problem normally requiring multiple specialized single-task networks. The resulting multitask cross-residual network also achieves better detection performance by about 10.4% over a standard multitask residual network without cross-residuals with even a small amount of cross-task weighting.
Model-Driven Feed-Forward Prediction for Manipulation of Deformable Objects
Jul 15, 2016

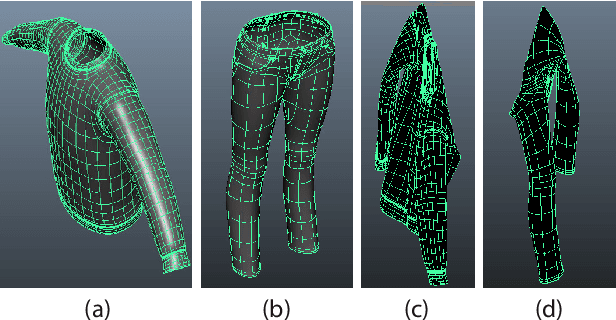
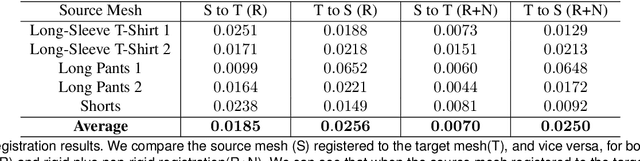
Robotic manipulation of deformable objects is a difficult problem especially because of the complexity of the many different ways an object can deform. Searching such a high dimensional state space makes it difficult to recognize, track, and manipulate deformable objects. In this paper, we introduce a predictive, model-driven approach to address this challenge, using a pre-computed, simulated database of deformable object models. Mesh models of common deformable garments are simulated with the garments picked up in multiple different poses under gravity, and stored in a database for fast and efficient retrieval. To validate this approach, we developed a comprehensive pipeline for manipulating clothing as in a typical laundry task. First, the database is used for category and pose estimation for a garment in an arbitrary position. A fully featured 3D model of the garment is constructed in real-time and volumetric features are then used to obtain the most similar model in the database to predict the object category and pose. Second, the database can significantly benefit the manipulation of deformable objects via non-rigid registration, providing accurate correspondences between the reconstructed object model and the database models. Third, the accurate model simulation can also be used to optimize the trajectories for manipulation of deformable objects, such as the folding of garments. Extensive experimental results are shown for the tasks above using a variety of different clothing.
Multilingual Visual Sentiment Concept Matching
Jun 07, 2016
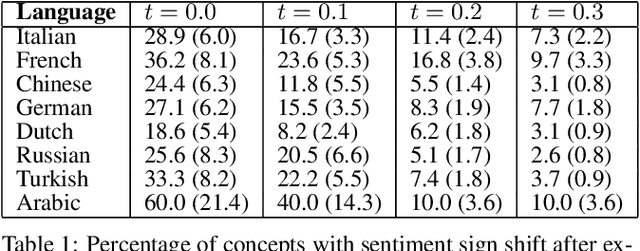
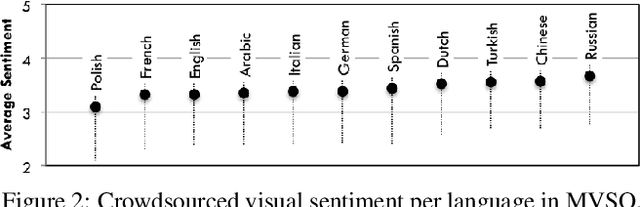
The impact of culture in visual emotion perception has recently captured the attention of multimedia research. In this study, we pro- vide powerful computational linguistics tools to explore, retrieve and browse a dataset of 16K multilingual affective visual concepts and 7.3M Flickr images. First, we design an effective crowdsourc- ing experiment to collect human judgements of sentiment connected to the visual concepts. We then use word embeddings to repre- sent these concepts in a low dimensional vector space, allowing us to expand the meaning around concepts, and thus enabling insight about commonalities and differences among different languages. We compare a variety of concept representations through a novel evaluation task based on the notion of visual semantic relatedness. Based on these representations, we design clustering schemes to group multilingual visual concepts, and evaluate them with novel metrics based on the crowdsourced sentiment annotations as well as visual semantic relatedness. The proposed clustering framework enables us to analyze the full multilingual dataset in-depth and also show an application on a facial data subset, exploring cultural in- sights of portrait-related affective visual concepts.
Going Deeper for Multilingual Visual Sentiment Detection
May 30, 2016
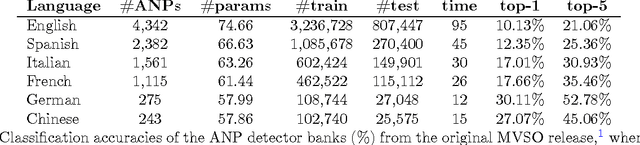
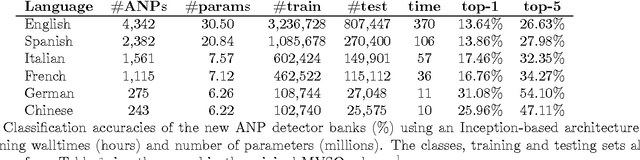
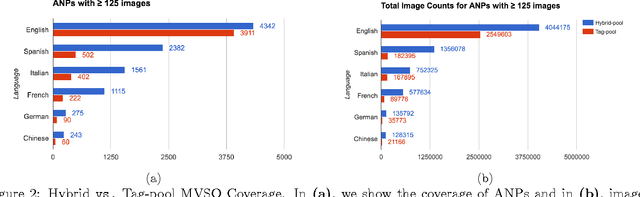
This technical report details several improvements to the visual concept detector banks built on images from the Multilingual Visual Sentiment Ontology (MVSO). The detector banks are trained to detect a total of 9,918 sentiment-biased visual concepts from six major languages: English, Spanish, Italian, French, German and Chinese. In the original MVSO release, adjective-noun pair (ANP) detectors were trained for the six languages using an AlexNet-styled architecture by fine-tuning from DeepSentiBank. Here, through a more extensive set of experiments, parameter tuning, and training runs, we detail and release higher accuracy models for detecting ANPs across six languages from the same image pool and setting as in the original release using a more modern architecture, GoogLeNet, providing comparable or better performance with reduced network parameter cost. In addition, since the image pool in MVSO can be corrupted by user noise from social interactions, we partitioned out a sub-corpus of MVSO images based on tag-restricted queries for higher fidelity labels. We show that as a result of these higher fidelity labels, higher performing AlexNet-styled ANP detectors can be trained using the tag-restricted image subset as compared to the models in full corpus. We release all these newly trained models for public research use along with the list of tag-restricted images from the MVSO dataset.
Generic Instance Search and Re-identification from One Example via Attributes and Categories
May 23, 2016
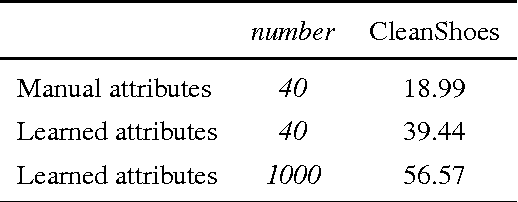
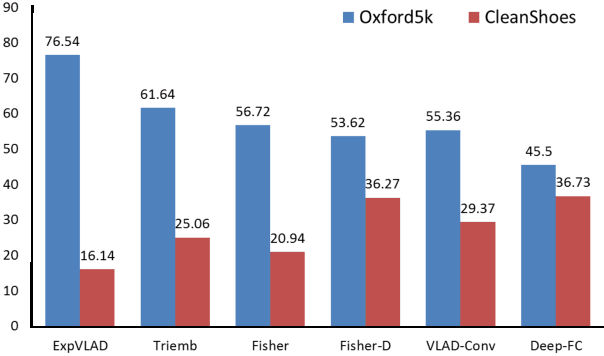
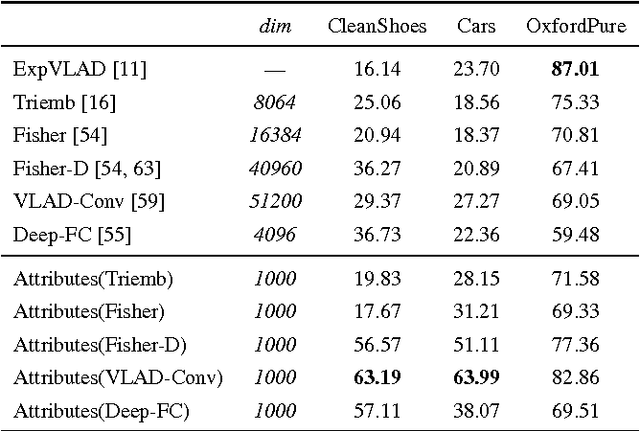
This paper aims for generic instance search from one example where the instance can be an arbitrary object like shoes, not just near-planar and one-sided instances like buildings and logos. First, we evaluate state-of-the-art instance search methods on this problem. We observe that what works for buildings loses its generality on shoes. Second, we propose to use automatically learned category-specific attributes to address the large appearance variations present in generic instance search. Searching among instances from the same category as the query, the category-specific attributes outperform existing approaches by a large margin on shoes and cars and perform on par with the state-of-the-art on buildings. Third, we treat person re-identification as a special case of generic instance search. On the popular VIPeR dataset, we reach state-of-the-art performance with the same method. Fourth, we extend our method to search objects without restriction to the specifically known category. We show that the combination of category-level information and the category-specific attributes is superior to the alternative method combining category-level information with low-level features such as Fisher vector.
Temporal Action Localization in Untrimmed Videos via Multi-stage CNNs
Apr 21, 2016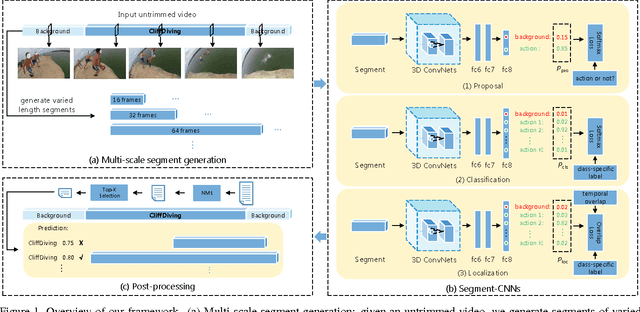
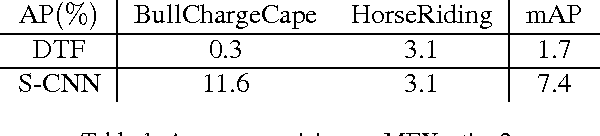

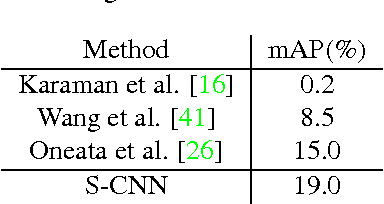
We address temporal action localization in untrimmed long videos. This is important because videos in real applications are usually unconstrained and contain multiple action instances plus video content of background scenes or other activities. To address this challenging issue, we exploit the effectiveness of deep networks in temporal action localization via three segment-based 3D ConvNets: (1) a proposal network identifies candidate segments in a long video that may contain actions; (2) a classification network learns one-vs-all action classification model to serve as initialization for the localization network; and (3) a localization network fine-tunes on the learned classification network to localize each action instance. We propose a novel loss function for the localization network to explicitly consider temporal overlap and therefore achieve high temporal localization accuracy. Only the proposal network and the localization network are used during prediction. On two large-scale benchmarks, our approach achieves significantly superior performances compared with other state-of-the-art systems: mAP increases from 1.7% to 7.4% on MEXaction2 and increases from 15.0% to 19.0% on THUMOS 2014, when the overlap threshold for evaluation is set to 0.5.
Event Specific Multimodal Pattern Mining with Image-Caption Pairs
Jan 05, 2016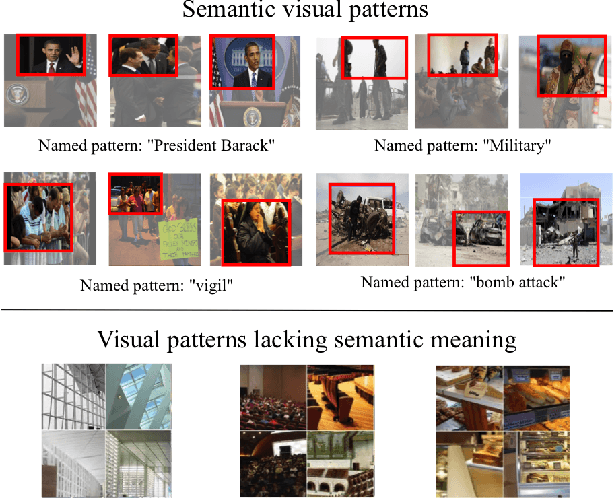

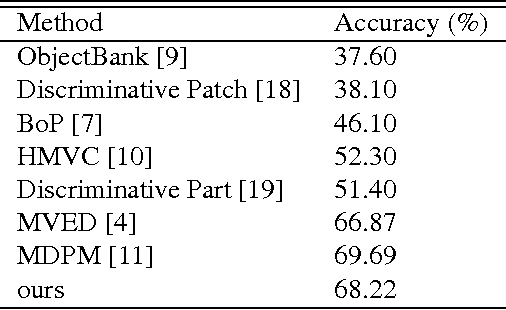
In this paper we describe a novel framework and algorithms for discovering image patch patterns from a large corpus of weakly supervised image-caption pairs generated from news events. Current pattern mining techniques attempt to find patterns that are representative and discriminative, we stipulate that our discovered patterns must also be recognizable by humans and preferably with meaningful names. We propose a new multimodal pattern mining approach that leverages the descriptive captions often accompanying news images to learn semantically meaningful image patch patterns. The mutltimodal patterns are then named using words mined from the associated image captions for each pattern. A novel evaluation framework is provided that demonstrates our patterns are 26.2% more semantically meaningful than those discovered by the state of the art vision only pipeline, and that we can provide tags for the discovered images patches with 54.5% accuracy with no direct supervision. Our methods also discover named patterns beyond those covered by the existing image datasets like ImageNet. To the best of our knowledge this is the first algorithm developed to automatically mine image patch patterns that have strong semantic meaning specific to high-level news events, and then evaluate these patterns based on that criteria.
On Binary Embedding using Circulant Matrices
Dec 05, 2015



Binary embeddings provide efficient and powerful ways to perform operations on large scale data. However binary embedding typically requires long codes in order to preserve the discriminative power of the input space. Thus binary coding methods traditionally suffer from high computation and storage costs in such a scenario. To address this problem, we propose Circulant Binary Embedding (CBE) which generates binary codes by projecting the data with a circulant matrix. The circulant structure allows us to use Fast Fourier Transform algorithms to speed up the computation. For obtaining $k$-bit binary codes from $d$-dimensional data, this improves the time complexity from $O(dk)$ to $O(d\log{d})$, and the space complexity from $O(dk)$ to $O(d)$. We study two settings, which differ in the way we choose the parameters of the circulant matrix. In the first, the parameters are chosen randomly and in the second, the parameters are learned using the data. For randomized CBE, we give a theoretical analysis comparing it with binary embedding using an unstructured random projection matrix. The challenge here is to show that the dependencies in the entries of the circulant matrix do not lead to a loss in performance. In the second setting, we design a novel time-frequency alternating optimization to learn data-dependent circulant projections, which alternatively minimizes the objective in original and Fourier domains. In both the settings, we show by extensive experiments that the CBE approach gives much better performance than the state-of-the-art approaches if we fix a running time, and provides much faster computation with negligible performance degradation if we fix the number of bits in the embedding.
An exploration of parameter redundancy in deep networks with circulant projections
Oct 27, 2015
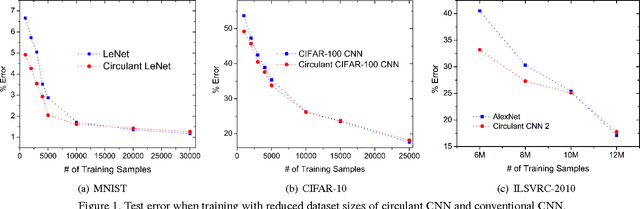
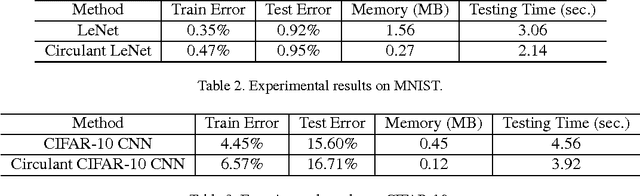
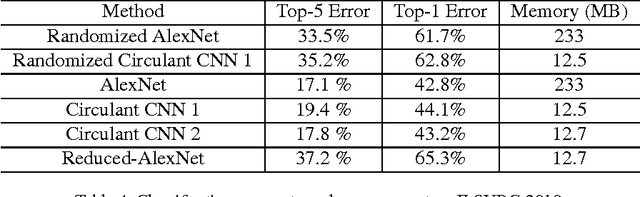
We explore the redundancy of parameters in deep neural networks by replacing the conventional linear projection in fully-connected layers with the circulant projection. The circulant structure substantially reduces memory footprint and enables the use of the Fast Fourier Transform to speed up the computation. Considering a fully-connected neural network layer with d input nodes, and d output nodes, this method improves the time complexity from O(d^2) to O(dlogd) and space complexity from O(d^2) to O(d). The space savings are particularly important for modern deep convolutional neural network architectures, where fully-connected layers typically contain more than 90% of the network parameters. We further show that the gradient computation and optimization of the circulant projections can be performed very efficiently. Our experiments on three standard datasets show that the proposed approach achieves this significant gain in storage and efficiency with minimal increase in error rate compared to neural networks with unstructured projections.
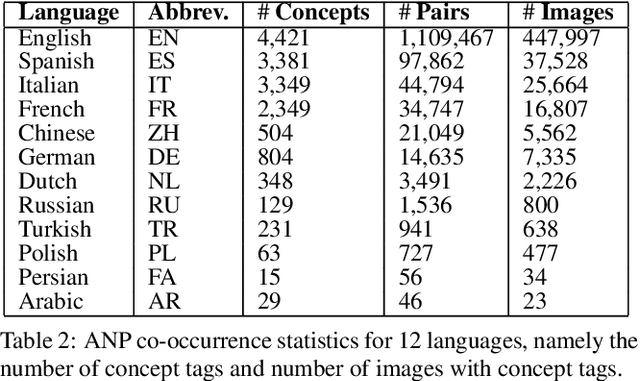
Visual Affect Around the World: A Large-scale Multilingual Visual Sentiment Ontology
Oct 07, 2015

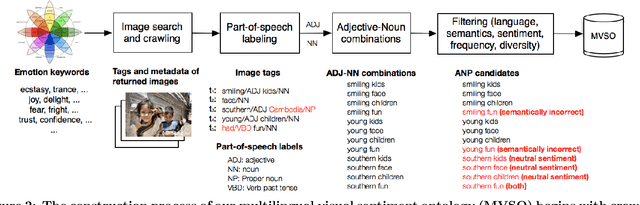
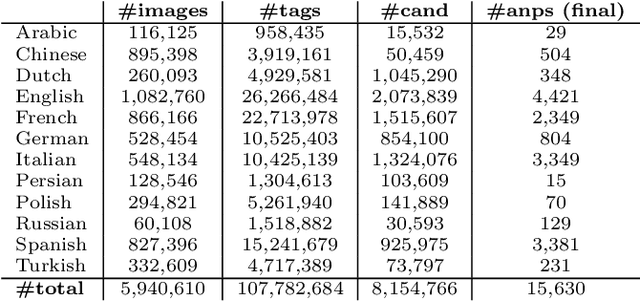
Every culture and language is unique. Our work expressly focuses on the uniqueness of culture and language in relation to human affect, specifically sentiment and emotion semantics, and how they manifest in social multimedia. We develop sets of sentiment- and emotion-polarized visual concepts by adapting semantic structures called adjective-noun pairs, originally introduced by Borth et al. (2013), but in a multilingual context. We propose a new language-dependent method for automatic discovery of these adjective-noun constructs. We show how this pipeline can be applied on a social multimedia platform for the creation of a large-scale multilingual visual sentiment concept ontology (MVSO). Unlike the flat structure in Borth et al. (2013), our unified ontology is organized hierarchically by multilingual clusters of visually detectable nouns and subclusters of emotionally biased versions of these nouns. In addition, we present an image-based prediction task to show how generalizable language-specific models are in a multilingual context. A new, publicly available dataset of >15.6K sentiment-biased visual concepts across 12 languages with language-specific detector banks, >7.36M images and their metadata is also released.