 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximizing the Total Reward via Reward Tweaking
Feb 09, 2020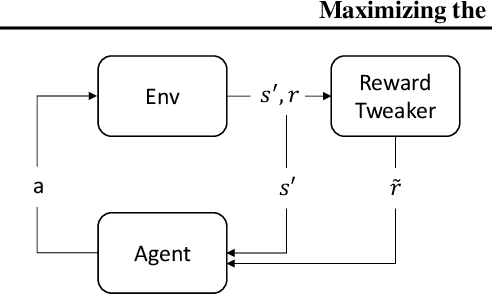

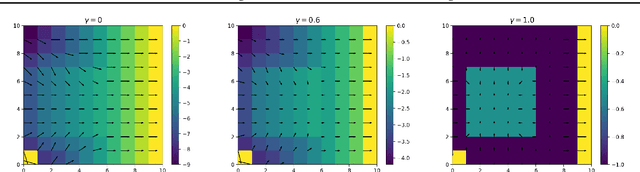
In reinforcement learning, the discount factor $\gamma$ controls the agent's effective planning horizon. Traditionally, this parameter was considered part of the MDP; however, as deep reinforcement learning algorithms tend to become unstable when the effective planning horizon is long, recent works refer to $\gamma$ as a hyper-parameter. In this work, we focus on the finite-horizon setting and introduce \emph{reward tweaking}. Reward tweaking learns a surrogate reward function $\tilde r$ for the discounted setting, which induces an optimal (undiscounted) return in the original finite-horizon task. Theoretically, we show that there exists a surrogate reward which leads to optimality in the original task and discuss the robustness of our approach. Additionally, we perform experiments in a high-dimensional continuous control task and show that reward tweaking guides the agent towards better long-horizon returns when it plans for short horizons using the tweaked reward.
Stabilizing Off-Policy Reinforcement Learning with Conservative Policy Gradients
Oct 02, 2019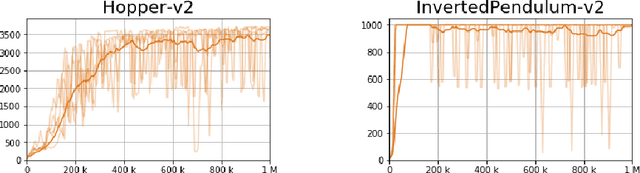

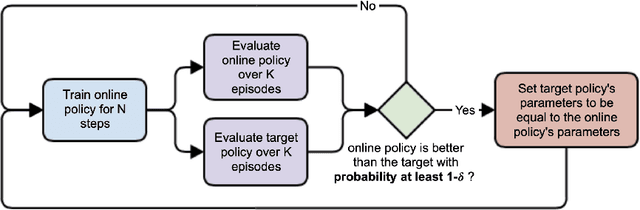
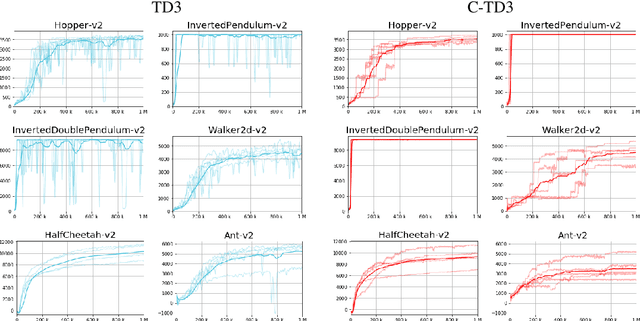
In recent years, advances in deep learning have enabled the application of reinforcement learning algorithms in complex domains. However, they lack the theoretical guarantees which are present in the tabular setting and suffer from many stability and reproducibility problems \citep{henderson2018deep}. In this work, we suggest a simple approach for improving stability and providing probabilistic performance guarantees in off-policy actor-critic deep reinforcement learning regimes. Experiments on continuous action spaces, in the MuJoCo control suite, show that our proposed method reduces the variance of the process and improves the overall performance.
Natural Language State Representation for Reinforcement Learning
Oct 02, 2019
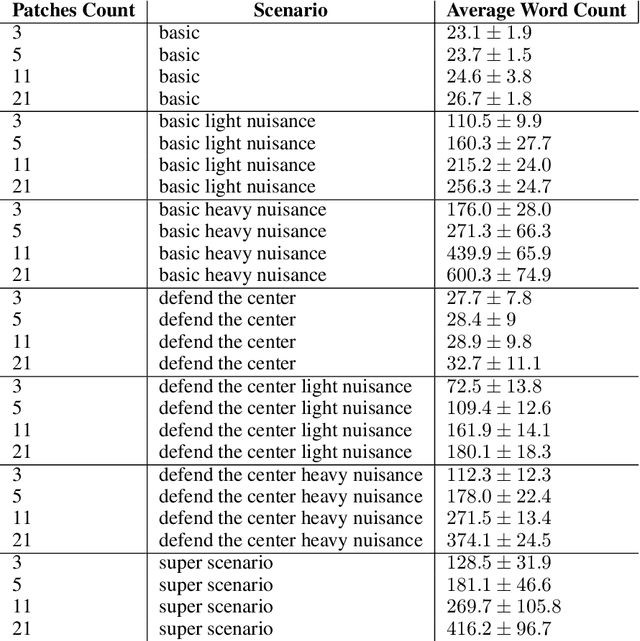
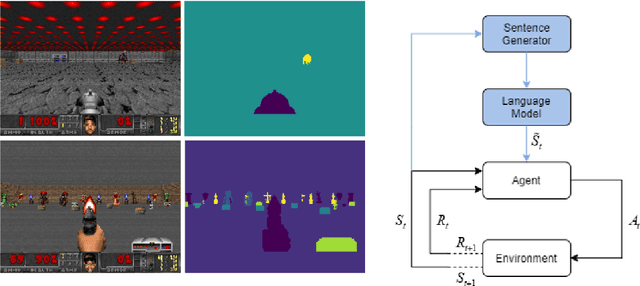

Recent advances in Reinforcement Learning have highlighted the difficulties in learning within complex high dimensional domains. We argue that one of the main reasons that current approaches do not perform well, is that the information is represented sub-optimally. A natural way to describe what we observe, is through natural language. In this paper, we implement a natural language state representation to learn and complete tasks. Our experiments suggest that natural language based agents are more robust, converge faster and perform better than vision based agents, showing the benefit of using natural language representations for Reinforcement Learning.
Multi-Step Greedy and Approximate Real Time Dynamic Programming
Sep 10, 2019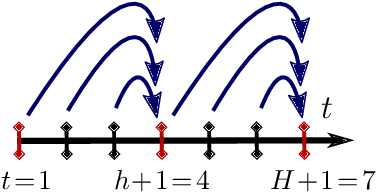

Real Time Dynamic Programming (RTDP) is a well-known Dynamic Programming (DP) based algorithm that combines planning and learning to find an optimal policy for an MDP. It is a planning algorithm because it uses the MDP's model (reward and transition functions) to calculate a 1-step greedy policy w.r.t.~an optimistic value function, by which it acts. It is a learning algorithm because it updates its value function only at the states it visits while interacting with the environment. As a result, unlike DP, RTDP does not require uniform access to the state space in each iteration, which makes it particularly appealing when the state space is large and simultaneously updating all the states is not computationally feasible. In this paper, we study a generalized multi-step greedy version of RTDP, which we call $h$-RTDP, in its exact form, as well as in three approximate settings: approximate model, approximate value updates, and approximate state abstraction. We analyze the sample, computation, and space complexities of $h$-RTDP and establish that increasing $h$ improves sample and space complexity, with the cost of additional offline computational operations. For the approximate cases, we prove that the asymptotic performance of $h$-RTDP is the same as that of a corresponding approximate DP -- the best one can hope for without further assumptions on the approximation errors. $h$-RTDP is the first algorithm with a provably improved sample complexity when increasing the lookahead horizon.
Off-Policy Evaluation in Partially Observable Environments
Sep 09, 2019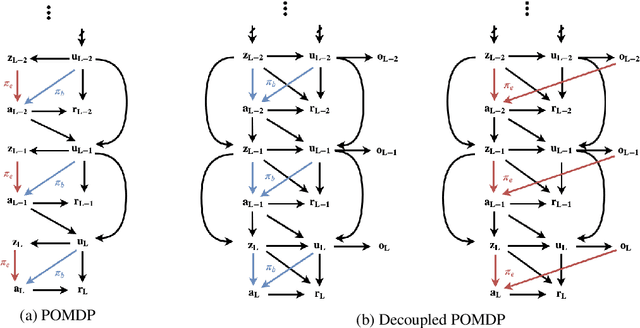
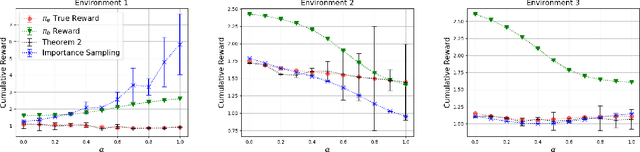
This work studies the problem of batch off-policy evaluation for Reinforcement Learning in partially observable environments. Off-policy evaluation under partial observability is inherently prone to bias, with risk of arbitrarily large errors. We define the problem of off-policy evaluation for Partially Observable Markov Decision Processes (POMDPs) and establish what we believe is the first off-policy evaluation result for POMDPs. In addition, we formulate a model in which observed and unobserved variables are decoupled into two dynamic processes, called a Decoupled POMDP. We show how off-policy evaluation can be performed under this new model, mitigating estimation errors inherent to the procedure we provided for general POMDPs. We demonstrate the pitfalls of off-policy evaluation in POMDPs using a well-known off-policy method, importance sampling, and compare with our result on synthetic medical data.
Adaptive Trust Region Policy Optimization: Global Convergence and Faster Rates for Regularized MDPs
Sep 06, 2019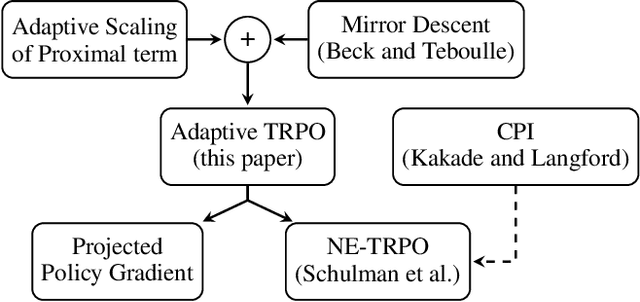
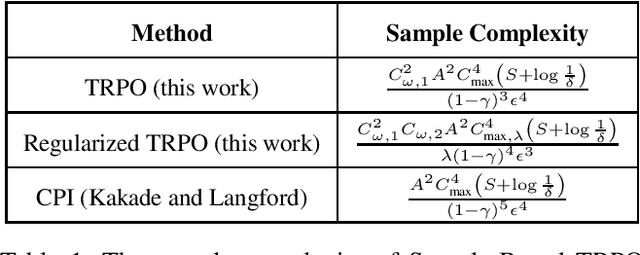
Trust region policy optimization (TRPO) is a popular and empirically successful policy search algorithm in Reinforcement Learning (RL) in which a surrogate problem, that restricts consecutive policies to be `close' to one another, is iteratively solved. Nevertheless, TRPO has been considered a heuristic algorithm inspired by Conservative Policy Iteration (CPI). We show that the adaptive scaling mechanism used in TRPO is in fact the natural "RL version" of traditional trust-region methods from convex analysis. We first analyze TRPO in the planning setting, in which we have access to the model and the entire state space. Then, we consider sample-based TRPO and establish $\tilde O(1/\sqrt{N})$ convergence rate to the global optimum. Importantly, the adaptive scaling mechanism allows us to analyze TRPO in {\em regularized MDPs} for which we prove fast rates of $\tilde O(1/N)$, much like results in convex optimization. This is the first result in RL of better rates when regularizing the instantaneous cost or reward.
Practical Risk Measures in Reinforcement Learning
Aug 22, 2019
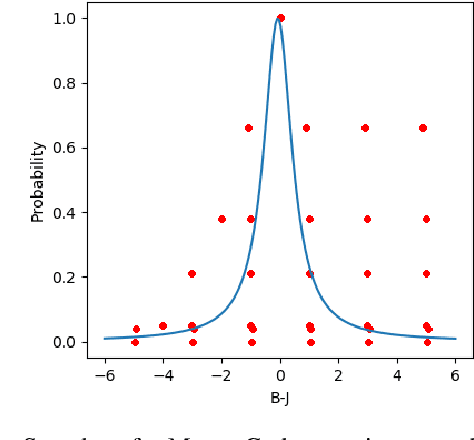
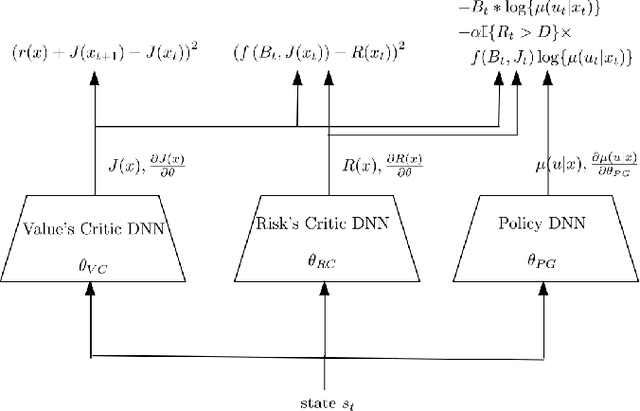
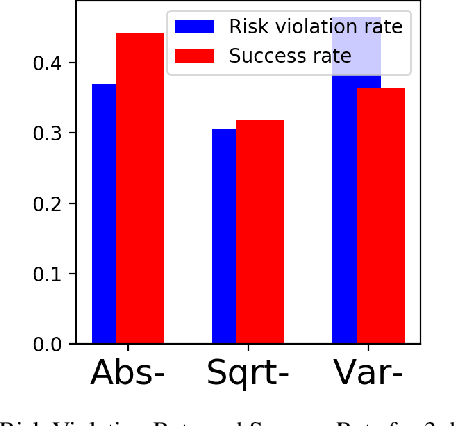
Practical application of Reinforcement Learning (RL) often involves risk considerations. We study a generalized approximation scheme for risk measures, based on Monte-Carlo simulations, where the risk measures need not necessarily be \emph{coherent}. We demonstrate that, even in simple problems, measures such as the variance of the reward-to-go do not capture the risk in a satisfactory manner. In addition, we show how a risk measure can be derived from model's realizations. We propose a neural architecture for estimating the risk and suggest the risk critic architecture that can be use to optimize a policy under general risk measures. We conclude our work with experiments that demonstrate the efficacy of our approach.
Topic Modeling via Full Dependence Mixtures
Jun 13, 2019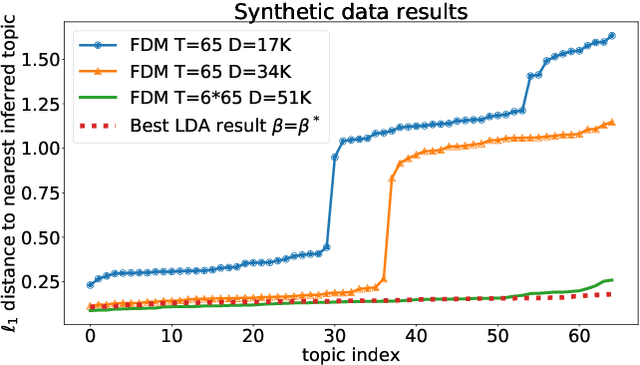
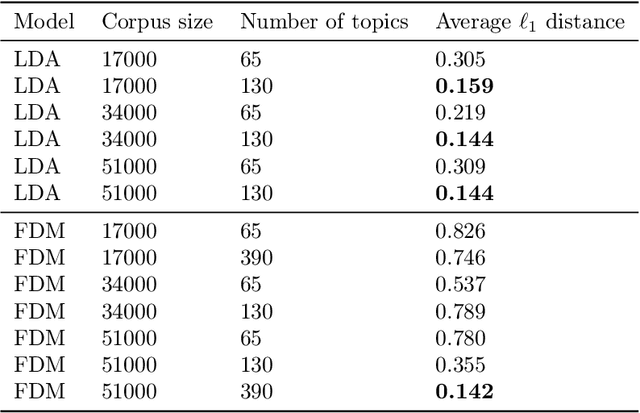
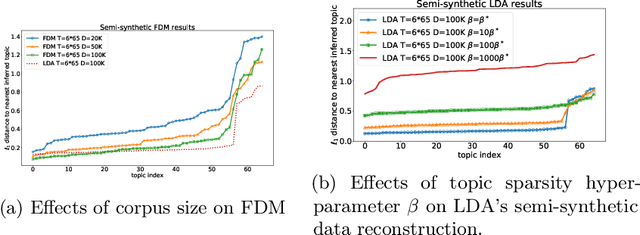
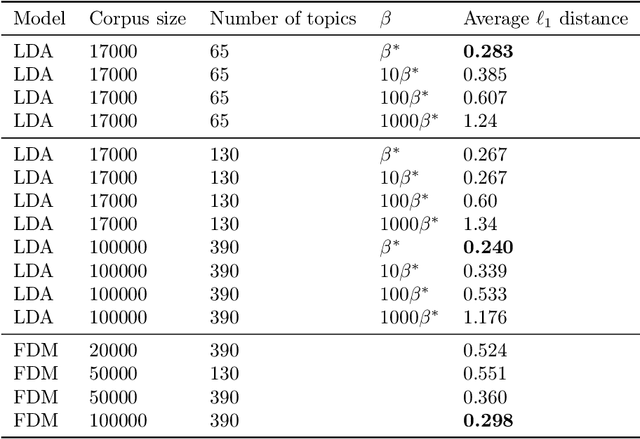
We consider the topic modeling problem for large datasets. For this problem, Latent Dirichlet Allocation (LDA) with a collapsed Gibbs sampler optimization is the state-of-the-art approach in terms of topic quality. However, LDA is a slow approach, and running it on large datasets is impractical even with modern hardware. In this paper we propose to fit topics directly to the co-occurances data of the corpus. In particular, we introduce an extension of a mixture model, the Full Dependence Mixture (FDM), which arises naturally as a model of a second moment under general generative assumptions on the data. While there is some previous work on topic modeling using second moments, we develop a direct stochastic optimization procedure for fitting an FDM with a single Kullback Leibler objective. While moment methods in general have the benefit that an iteration no longer needs to scale with the size of the corpus, our approach also allows us to leverage standard optimizers and GPUs for the problem of topic modeling. We evaluate the approach on synthetic and semi-synthetic data, as well as on the SOTU and Neurips Papers corpora, and show that the approach outperforms LDA, where LDA is run on both full and sub-sampled data.
Variance Estimation For Online Regression via Spectrum Thresholding
Jun 13, 2019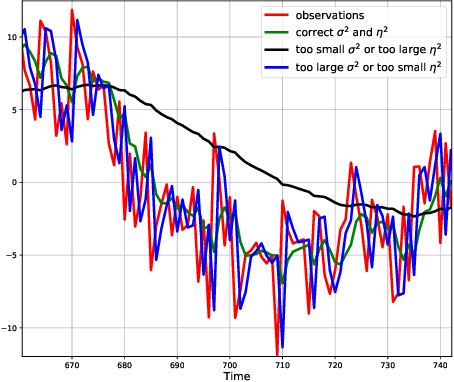
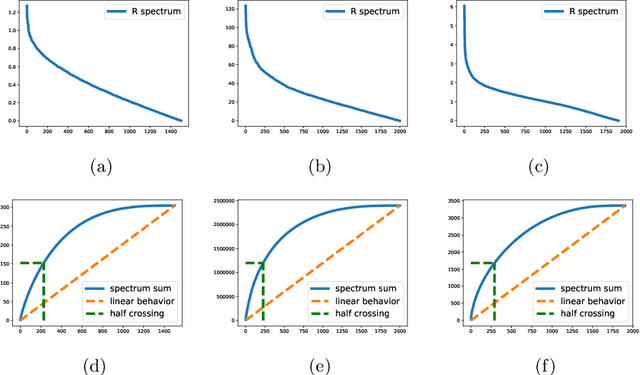
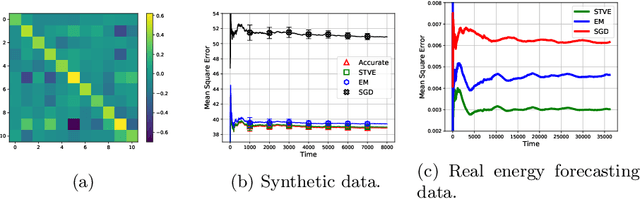
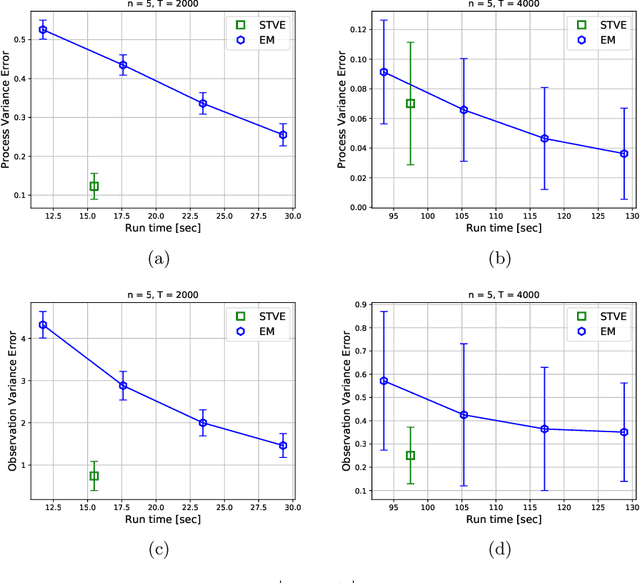
We consider the online linear regression problem, where the predictor vector may vary with time. This problem can be modelled as a linear dynamical system, where the parameters that need to be learned are the variance of both the process noise and the observation noise. The classical approach to learning the variance is via the maximum likelihood estimator -- a non-convex optimization problem prone to local minima and with no finite sample complexity bounds. In this paper we study the global system operator: the operator that maps the noises vectors to the output. In particular, we obtain estimates on its spectrum, and as a result derive the first known variance estimators with sample complexity guarantees for online regression problems. We demonstrate the approach on a number of synthetic and real-world benchmarks.
Batch-Size Independent Regret Bounds for the Combinatorial Multi-Armed Bandit Problem
May 29, 2019We consider the combinatorial multi-armed bandit (CMAB) problem, where the reward function is nonlinear. In this setting, the agent chooses a batch of arms on each round and receives feedback from each arm of the batch. The reward that the agent aims to maximize is a function of the selected arms and their expectations. In many applications, the reward function is highly nonlinear, and the performance of existing algorithms relies on a global Lipschitz constant to encapsulate the function's nonlinearity. This may lead to loose regret bounds, since by itself, a large gradient does not necessarily cause a large regret, but only in regions where the uncertainty in the reward's parameters is high. To overcome this problem, we introduce a new smoothness criterion, which we term \emph{Gini-weighted smoothness}, that takes into account both the nonlinearity of the reward and concentration properties of the arms. We show that a linear dependence of the regret in the batch size in existing algorithms can be replaced by this smoothness parameter. This, in turn, leads to much tighter regret bounds when the smoothness parameter is batch-size independent. For example, in the probabilistic maximum coverage (PMC) problem, that has many applications, including influence maximization, diverse recommendations and more, we achieve dramatic improvements in the upper bounds. We also prove matching lower bounds for the PMC problem and show that our algorithm is tight, up to a logarithmic factor in the problem's parameters.