 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Planning Under Uncertainty for AUVs Using Virtual Maps
Mar 07, 2024



Reliable localization is an essential capability for marine robots navigating in GPS-denied environments. SLAM, commonly used to mitigate dead reckoning errors, still fails in feature-sparse environments or with limited-range sensors. Pose estimation can be improved by incorporating the uncertainty prediction of future poses into the planning process and choosing actions that reduce uncertainty. However, performing belief propagation is computationally costly, especially when operating in large-scale environments. This work proposes a computationally efficient planning under uncertainty frame-work suitable for large-scale, feature-sparse environments. Our strategy leverages SLAM graph and occupancy map data obtained from a prior exploration phase to create a virtual map, describing the uncertainty of each map cell using a multivariate Gaussian. The virtual map is then used as a cost map in the planning phase, and performing belief propagation at each step is avoided. A receding horizon planning strategy is implemented, managing a goal-reaching and uncertainty-reduction tradeoff. Simulation experiments in a realistic underwater environment validate this approach. Experimental comparisons against a full belief propagation approach and a standard shortest-distance approach are conducted.
Virtual Maps for Autonomous Exploration of Cluttered Underwater Environments
Feb 16, 2022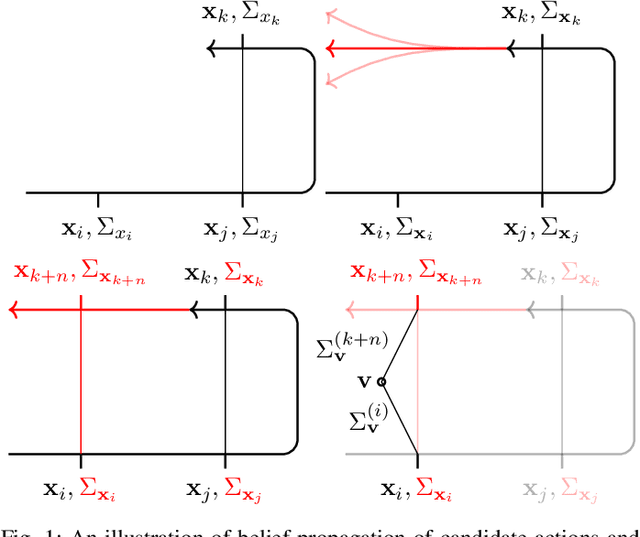
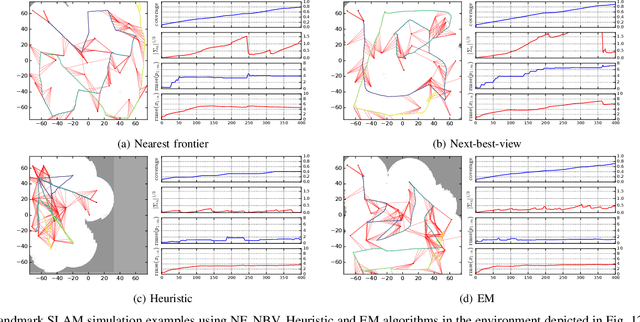
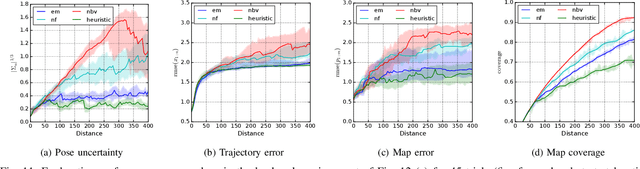
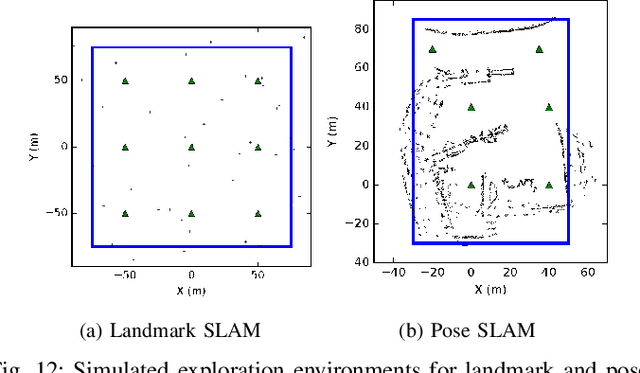
We consider the problem of autonomous mobile robot exploration in an unknown environment, taking into account a robot's coverage rate, map uncertainty, and state estimation uncertainty. This paper presents a novel exploration framework for underwater robots operating in cluttered environments, built upon simultaneous localization and mapping (SLAM) with imaging sonar. The proposed system comprises path generation, place recognition forecasting, belief propagation and utility evaluation using a virtual map, which estimates the uncertainty associated with map cells throughout a robot's workspace. We evaluate the performance of this framework in simulated experiments, showing that our algorithm maintains a high coverage rate during exploration while also maintaining low mapping and localization error. The real-world applicability of our framework is also demonstrated on an underwater remotely operated vehicle (ROV) exploring a harbor environment.
Zero-Shot Reinforcement Learning on Graphs for Autonomous Exploration Under Uncertainty
May 11, 2021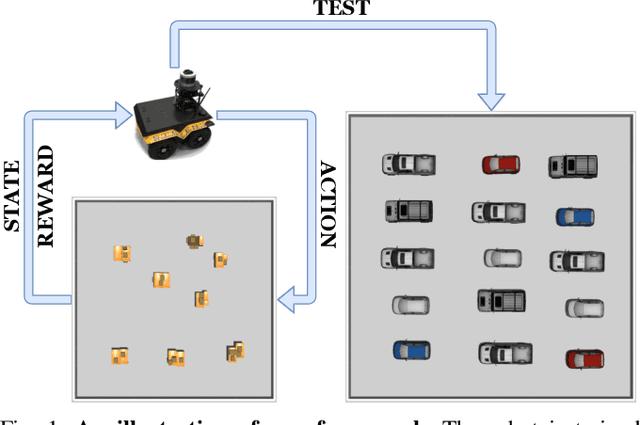


This paper studies the problem of autonomous exploration under localization uncertainty for a mobile robot with 3D range sensing. We present a framework for self-learning a high-performance exploration policy in a single simulation environment, and transferring it to other environments, which may be physical or virtual. Recent work in transfer learning achieves encouraging performance by domain adaptation and domain randomization to expose an agent to scenarios that fill the inherent gaps in sim2sim and sim2real approaches. However, it is inefficient to train an agent in environments with randomized conditions to learn the important features of its current state. An agent can use domain knowledge provided by human experts to learn efficiently. We propose a novel approach that uses graph neural networks in conjunction with deep reinforcement learning, enabling decision-making over graphs containing relevant exploration information provided by human experts to predict a robot's optimal sensing action in belief space. The policy, which is trained only in a single simulation environment, offers a real-time, scalable, and transferable decision-making strategy, resulting in zero-shot transfer to other simulation environments and even real-world environments.
Autonomous Exploration Under Uncertainty via Deep Reinforcement Learning on Graphs
Jul 24, 2020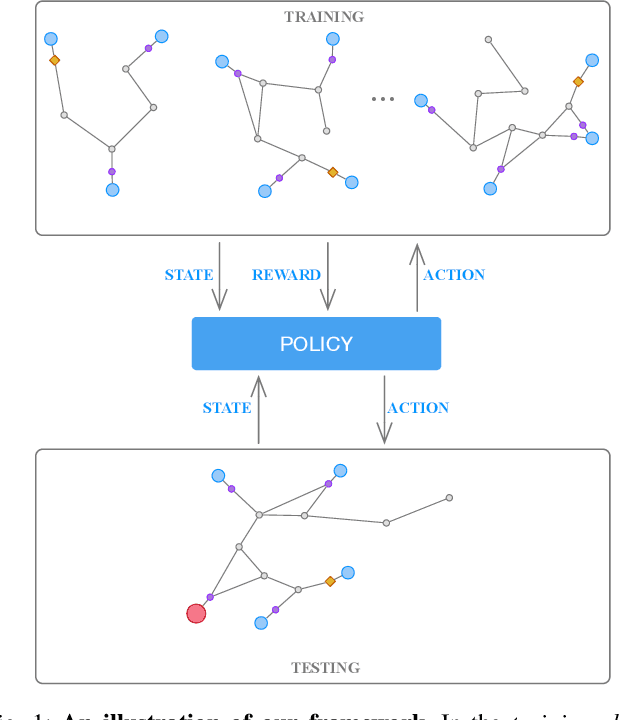
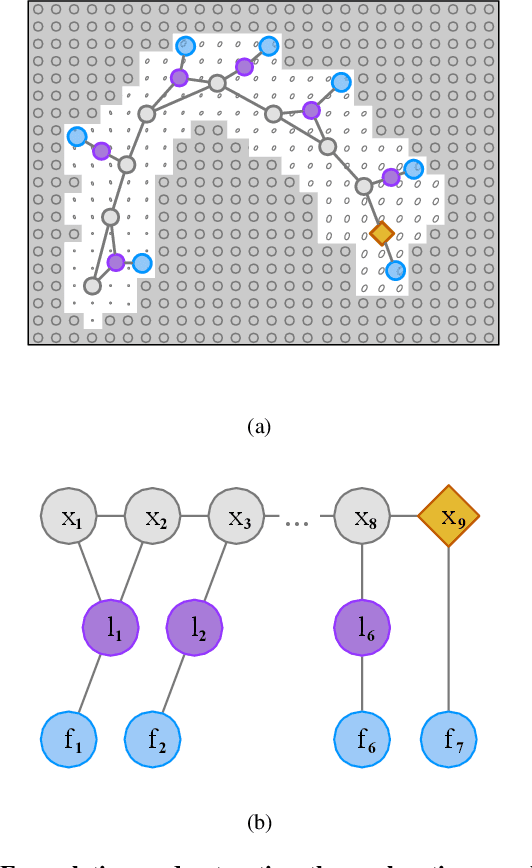
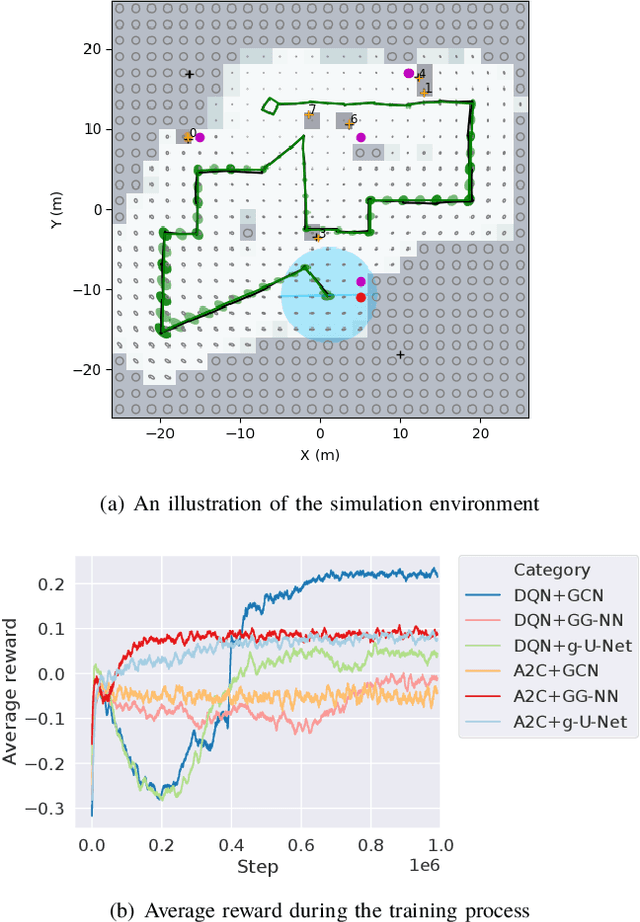
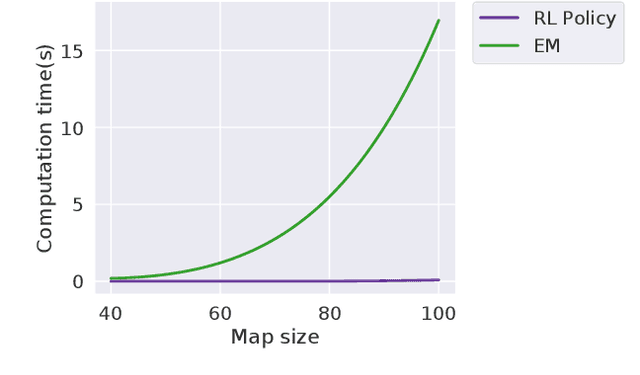
We consider an autonomous exploration problem in which a range-sensing mobile robot is tasked with accurately mapping the landmarks in an a priori unknown environment efficiently in real-time; it must choose sensing actions that both curb localization uncertainty and achieve information gain. For this problem, belief space planning methods that forward-simulate robot sensing and estimation may often fail in real-time implementation, scaling poorly with increasing size of the state, belief and action spaces. We propose a novel approach that uses graph neural networks (GNNs) in conjunction with deep reinforcement learning (DRL), enabling decision-making over graphs containing exploration information to predict a robot's optimal sensing action in belief space. The policy, which is trained in different random environments without human intervention, offers a real-time, scalable decision-making process whose high-performance exploratory sensing actions yield accurate maps and high rates of information gain.
Simulation-based Lidar Super-resolution for Ground Vehicles
Apr 10, 2020
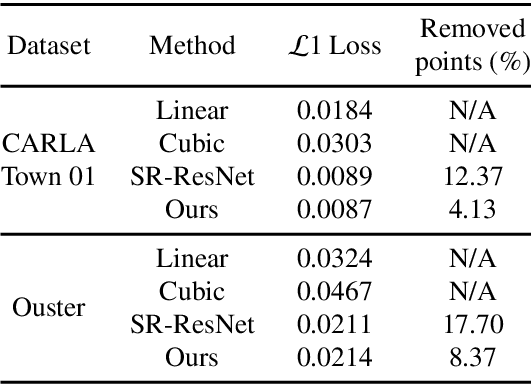
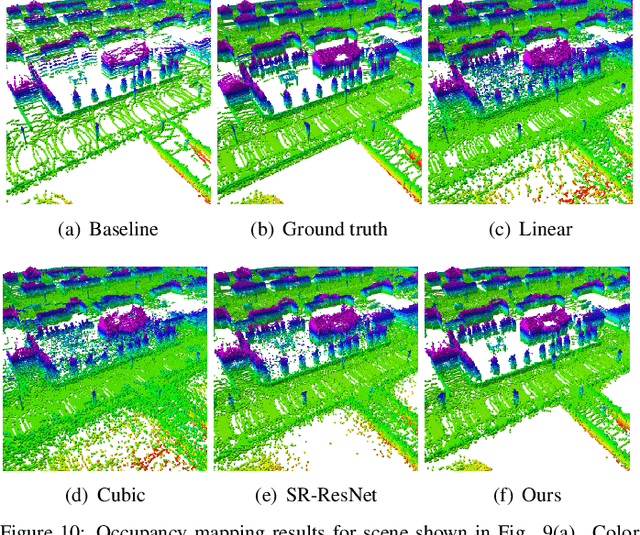

We propose a methodology for lidar super-resolution with ground vehicles driving on roadways, which relies completely on a driving simulator to enhance, via deep learning, the apparent resolution of a physical lidar. To increase the resolution of the point cloud captured by a sparse 3D lidar, we convert this problem from 3D Euclidean space into an image super-resolution problem in 2D image space, which is solved using a deep convolutional neural network. By projecting a point cloud onto a range image, we are able to efficiently enhance the resolution of such an image using a deep neural network. Typically, the training of a deep neural network requires vast real-world data. Our approach does not require any real-world data, as we train the network purely using computer-generated data. Thus our method is applicable to the enhancement of any type of 3D lidar theoretically. By novelly applying Monte-Carlo dropout in the network and removing the predictions with high uncertainty, our method produces high accuracy point clouds comparable with the observations of a real high resolution lidar. We present experimental results applying our method to several simulated and real-world datasets. We argue for the method's potential benefits in real-world robotics applications such as occupancy mapping and terrain modeling.
Sparse Gaussian Process Temporal Difference Learning for Marine Robot Navigation
Oct 02, 2018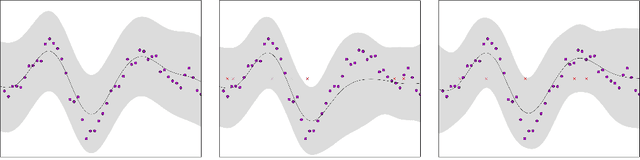
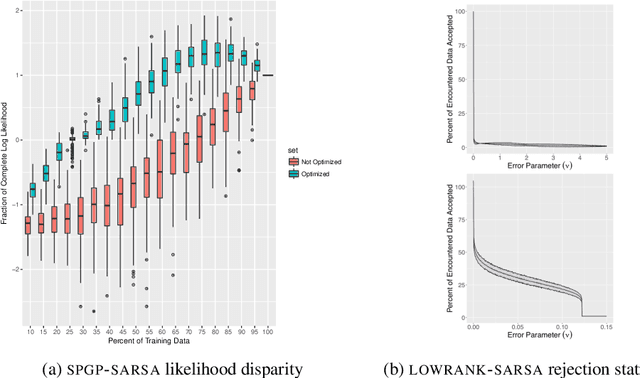
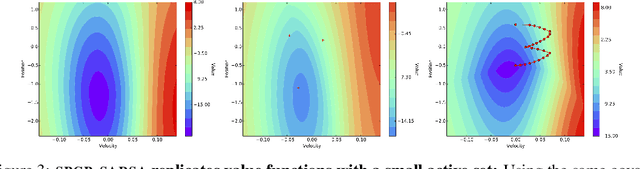

We present a method for Temporal Difference (TD) learning that addresses several challenges faced by robots learning to navigate in a marine environment. For improved data efficiency, our method reduces TD updates to Gaussian Process regression. To make predictions amenable to online settings, we introduce a sparse approximation with improved quality over current rejection-based sparse methods. We derive the predictive value function posterior and use the moments to obtain a new algorithm for model-free policy evaluation, SPGP-SARSA. With simple changes, we show SPGP-SARSA can be reduced to a model-based equivalent, SPGP-TD. We perform comprehensive simulation studies and also conduct physical learning trials with an underwater robot. Our results show SPGP-SARSA can outperform the state-of-the-art sparse method, replicate the prediction quality of its exact counterpart, and be applied to solve underwater navigation tasks.