 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffMagicFace: Identity Consistent Facial Editing of Real Videos
Apr 15, 2026Text-conditioned image editing has greatly benefitted from the advancements in Image Diffusion Models. However, extending these techniques to facial video editing introduces challenges in preserving facial identity throughout the source video and ensuring consistency of the edited subject across frames. In this paper, we introduce DiffMagicFace, a unique video editing framework that integrates two fine-tuned models for text and image control. These models operate concurrently during inference to produce video frames that maintain identity features while seamlessly aligning with the editing semantics. To ensure the consistency of the edited videos, we develop a dataset comprising images showcasing various facial perspectives for each edited subject. The creation of a data set is achieved through rendering techniques and the subsequent application of optimization algorithms. Remarkably, our approach does not depend on video datasets but still delivers high-quality results in both consistency and content. The excellent effect holds even for complex tasks like talking head videos and distinguishing closely related categories. The videos edited using our framework exhibit parity with videos that are made using traditional rendering software. Through comparative analysis with current state-of-the-art methods, our framework demonstrates superior performance in both visual appeal and quantitative metrics.
GaussianGrow: Geometry-aware Gaussian Growing from 3D Point Clouds with Text Guidance
Apr 07, 20263D Gaussian Splatting has demonstrated superior performance in rendering efficiency and quality, yet the generation of 3D Gaussians still remains a challenge without proper geometric priors. Existing methods have explored predicting point maps as geometric references for inferring Gaussian primitives, while the unreliable estimated geometries may lead to poor generations. In this work, we introduce GaussianGrow, a novel approach that generates 3D Gaussians by learning to grow them from easily accessible 3D point clouds, naturally enforcing geometric accuracy in Gaussian generation. Specifically, we design a text-guided Gaussian growing scheme that leverages a multi-view diffusion model to synthesize consistent appearances from input point clouds for supervision. To mitigate artifacts caused by fusing neighboring views, we constrain novel views generated at non-preset camera poses identified in overlapping regions across different views. For completing the hard-to-observe regions, we propose to iteratively detect the camera pose by observing the largest un-grown regions in point clouds and inpainting them by inpainting the rendered view with a pretrained 2D diffusion model. The process continues until complete Gaussians are generated. We extensively evaluate GaussianGrow on text-guided Gaussian generation from synthetic and even real-scanned point clouds. Project Page: https://weiqi-zhang.github.io/GaussianGrow
4C4D: 4 Camera 4D Gaussian Splatting
Apr 05, 2026This paper tackles the challenge of recovering 4D dynamic scenes from videos captured by as few as four portable cameras. Learning to model scene dynamics for temporally consistent novel-view rendering is a foundational task in computer graphics, where previous works often require dense multi-view captures using camera arrays of dozens or even hundreds of views. We propose \textbf{4C4D}, a novel framework that enables high-fidelity 4D Gaussian Splatting from video captures of extremely sparse cameras. Our key insight lies that the geometric learning under sparse settings is substantially more difficult than modeling appearance. Driven by this observation, we introduce a Neural Decaying Function on Gaussian opacities for enhancing the geometric modeling capability of 4D Gaussians. This design mitigates the inherent imbalance between geometry and appearance modeling in 4DGS by encouraging the 4DGS gradients to focus more on geometric learning. Extensive experiments across sparse-view datasets with varying camera overlaps show that 4C4D achieves superior performance over prior art. Project page at: https://junshengzhou.github.io/4C4D.
Hybrid Spatio-Temporal Graph Convolutional Network: Improving Traffic Prediction with Navigation Data
Jun 23, 2020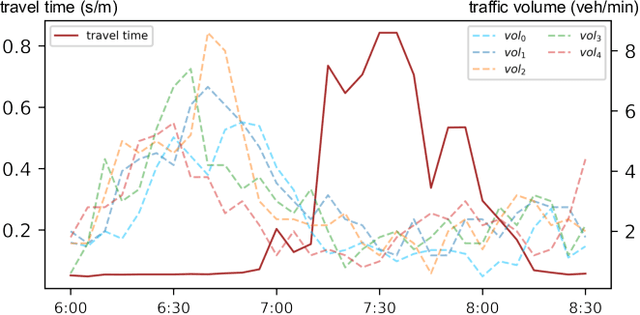
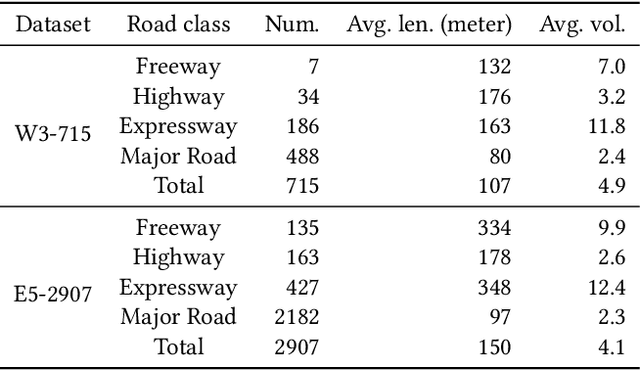
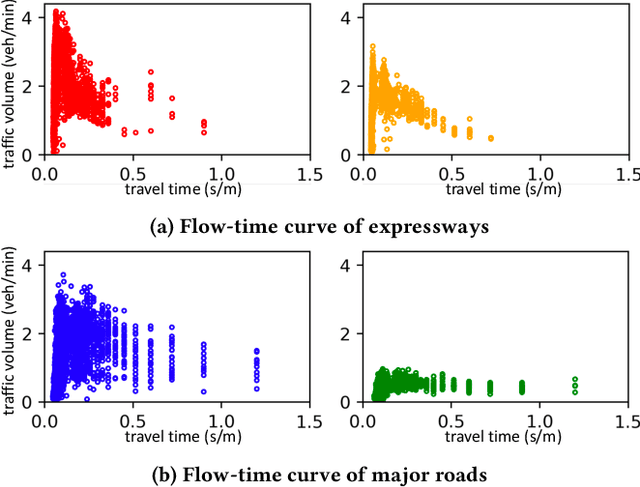
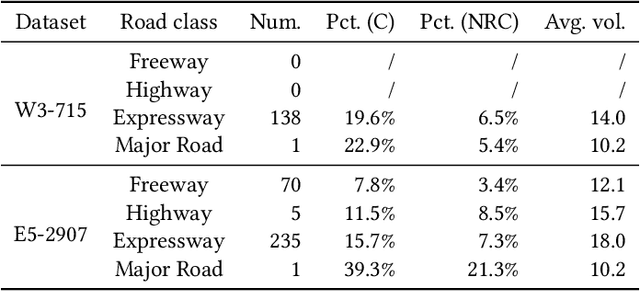
Traffic forecasting has recently attracted increasing interest due to the popularity of online navigation services, ridesharing and smart city projects. Owing to the non-stationary nature of road traffic, forecasting accuracy is fundamentally limited by the lack of contextual information. To address this issue, we propose the Hybrid Spatio-Temporal Graph Convolutional Network (H-STGCN), which is able to "deduce" future travel time by exploiting the data of upcoming traffic volume. Specifically, we propose an algorithm to acquire the upcoming traffic volume from an online navigation engine. Taking advantage of the piecewise-linear flow-density relationship, a novel transformer structure converts the upcoming volume into its equivalent in travel time. We combine this signal with the commonly-utilized travel-time signal, and then apply graph convolution to capture the spatial dependency. Particularly, we construct a compound adjacency matrix which reflects the innate traffic proximity. We conduct extensive experiments on real-world datasets. The results show that H-STGCN remarkably outperforms state-of-the-art methods in various metrics, especially for the prediction of non-recurring congestion.