 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
Microstructure Representation and Reconstruction of Heterogeneous Materials via Deep Belief Network for Computational Material Design
Apr 28, 2017
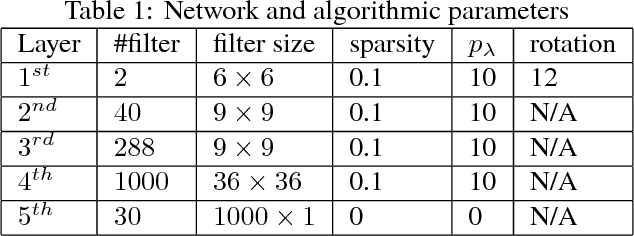
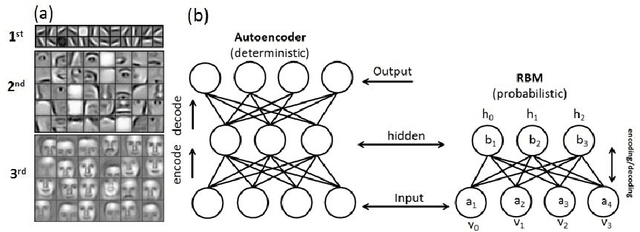
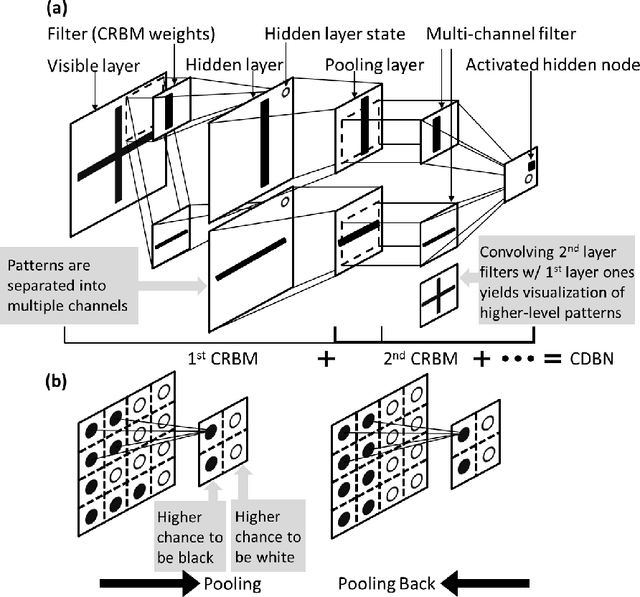
Integrated Computational Materials Engineering (ICME) aims to accelerate optimal design of complex material systems by integrating material science and design automation. For tractable ICME, it is required that (1) a structural feature space be identified to allow reconstruction of new designs, and (2) the reconstruction process be property-preserving. The majority of existing structural presentation schemes rely on the designer's understanding of specific material systems to identify geometric and statistical features, which could be biased and insufficient for reconstructing physically meaningful microstructures of complex material systems. In this paper, we develop a feature learning mechanism based on convolutional deep belief network to automate a two-way conversion between microstructures and their lower-dimensional feature representations, and to achieves a 1000-fold dimension reduction from the microstructure space. The proposed model is applied to a wide spectrum of heterogeneous material systems with distinct microstructural features including Ti-6Al-4V alloy, Pb63-Sn37 alloy, Fontainebleau sandstone, and Spherical colloids, to produce material reconstructions that are close to the original samples with respect to 2-point correlation functions and mean critical fracture strength. This capability is not achieved by existing synthesis methods that rely on the Markovian assumption of material microstructures.
A maximal-information color to gray conversion method for document images: Toward an optimal grayscale representation for document image binarization
Jun 26, 2013
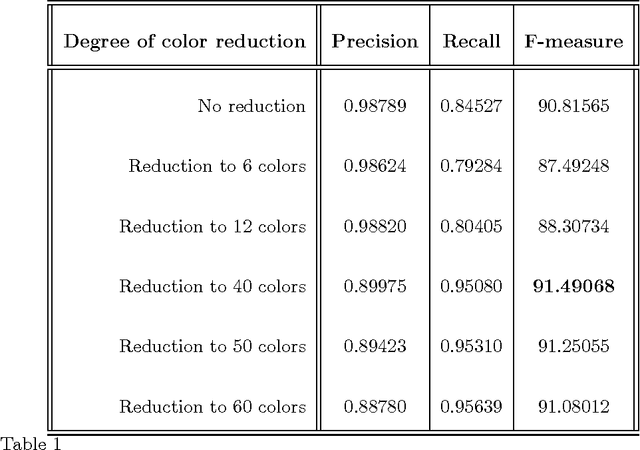

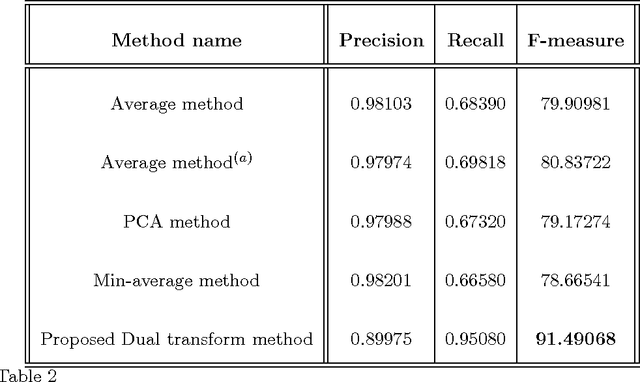
A novel method to convert color/multi-spectral images to gray-level images is introduced to increase the performance of document binarization methods. The method uses the distribution of the pixel data of the input document image in a color space to find a transformation, called the dual transform, which balances the amount of information on all color channels. Furthermore, in order to reduce the intensity variations on the gray output, a color reduction preprocessing step is applied. Then, a channel is selected as the gray value representation of the document image based on the homogeneity criterion on the text regions. In this way, the proposed method can provide a luminance-independent contrast enhancement. The performance of the method is evaluated against various images from two databases, the ICDAR'03 Robust Reading, the KAIST and the DIBCO'09 datasets, subjectively and objectively with promising results. The ground truth images for the images from the ICDAR'03 Robust Reading dataset have been created manually by the authors.