 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Noisy Tracklet Person Re-identification
Jan 16, 2021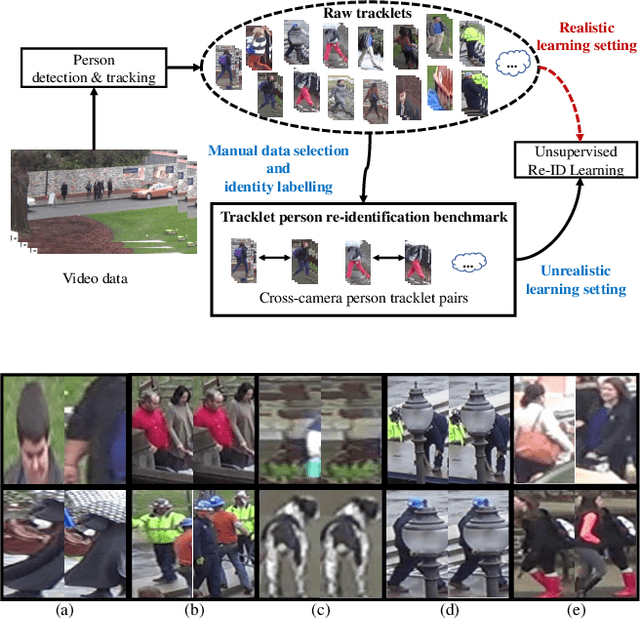

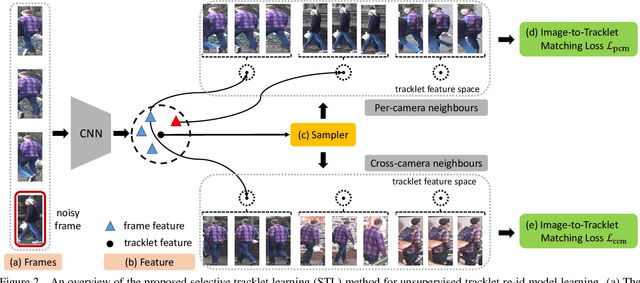
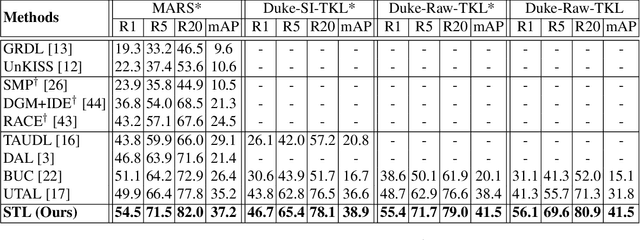
Existing person re-identification (re-id) methods mostly rely on supervised model learning from a large set of person identity labelled training data per domain. This limits their scalability and usability in large scale deployments. In this work, we present a novel selective tracklet learning (STL) approach that can train discriminative person re-id models from unlabelled tracklet data in an unsupervised manner. This avoids the tedious and costly process of exhaustively labelling person image/tracklet true matching pairs across camera views. Importantly, our method is particularly more robust against arbitrary noisy data of raw tracklets therefore scalable to learning discriminative models from unconstrained tracking data. This differs from a handful of existing alternative methods that often assume the existence of true matches and balanced tracklet samples per identity class. This is achieved by formulating a data adaptive image-to-tracklet selective matching loss function explored in a multi-camera multi-task deep learning model structure. Extensive comparative experiments demonstrate that the proposed STL model surpasses significantly the state-of-the-art unsupervised learning and one-shot learning re-id methods on three large tracklet person re-id benchmarks.
Transfer Learning for Protein Structure Classification at Low Resolution
Aug 31, 2020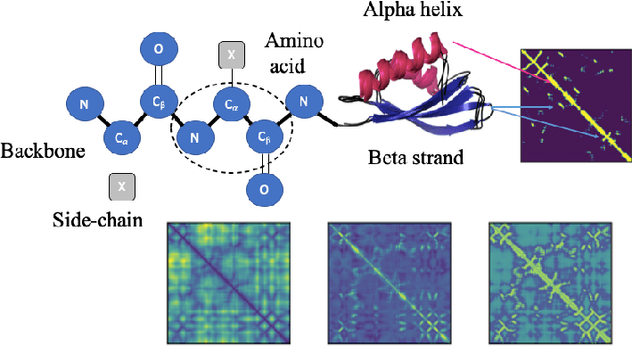
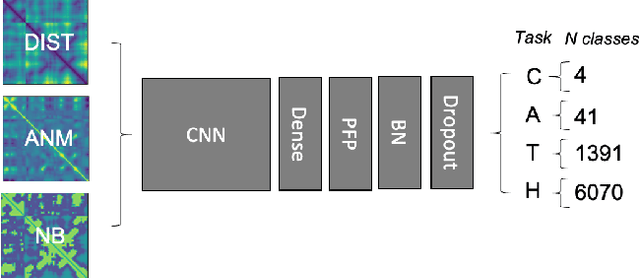
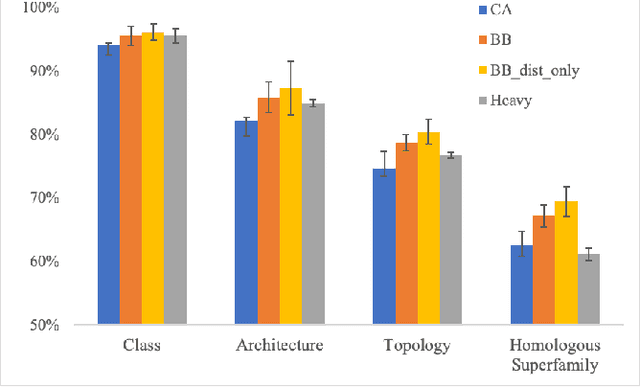

Structure determination is key to understanding protein function at a molecular level. Whilst significant advances have been made in predicting structure and function from amino acid sequence, researchers must still rely on expensive, time-consuming analytical methods to visualise detailed protein conformation. In this study, we demonstrate that it is possible to make accurate ($\geq$80%) predictions of protein class and architecture from structures determined at low ($>$3A) resolution, using a deep convolutional neural network trained on high-resolution ($\leq$3A) structures represented as 2D matrices. Thus, we provide proof of concept for high-speed, low-cost protein structure classification at low resolution, and a basis for extension to prediction of function. We investigate the impact of the input representation on classification performance, showing that side-chain information may not be necessary for fine-grained structure predictions. Finally, we confirm that high-resolution, low-resolution and NMR-determined structures inhabit a common feature space, and thus provide a theoretical foundation for boosting with single-image super-resolution.
Faster Person Re-Identification
Aug 16, 2020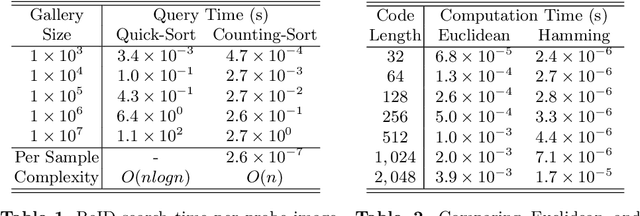
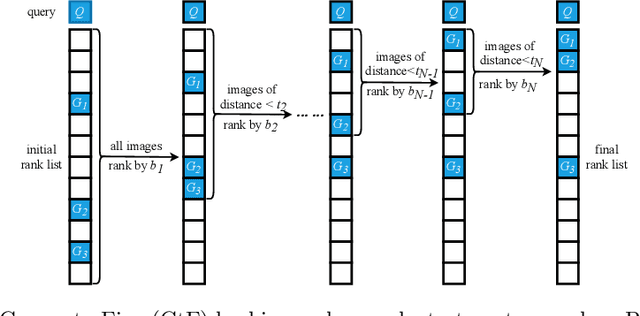
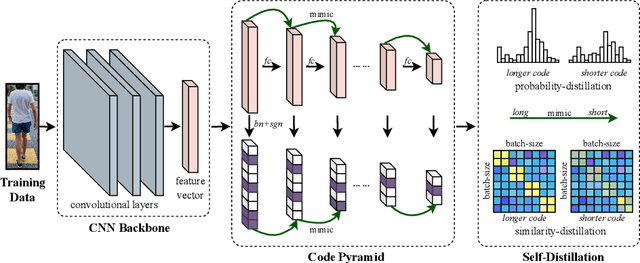
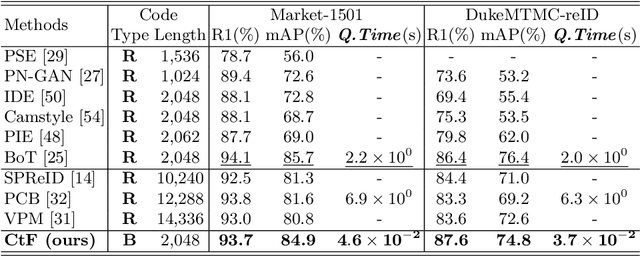
Fast person re-identification (ReID) aims to search person images quickly and accurately. The main idea of recent fast ReID methods is the hashing algorithm, which learns compact binary codes and performs fast Hamming distance and counting sort. However, a very long code is needed for high accuracy (e.g. 2048), which compromises search speed. In this work, we introduce a new solution for fast ReID by formulating a novel Coarse-to-Fine (CtF) hashing code search strategy, which complementarily uses short and long codes, achieving both faster speed and better accuracy. It uses shorter codes to coarsely rank broad matching similarities and longer codes to refine only a few top candidates for more accurate instance ReID. Specifically, we design an All-in-One (AiO) framework together with a Distance Threshold Optimization (DTO) algorithm. In AiO, we simultaneously learn and enhance multiple codes of different lengths in a single model. It learns multiple codes in a pyramid structure, and encourage shorter codes to mimic longer codes by self-distillation. DTO solves a complex threshold search problem by a simple optimization process, and the balance between accuracy and speed is easily controlled by a single parameter. It formulates the optimization target as a $F_{\beta}$ score that can be optimised by Gaussian cumulative distribution functions. Experimental results on 2 datasets show that our proposed method (CtF) is not only 8% more accurate but also 5x faster than contemporary hashing ReID methods. Compared with non-hashing ReID methods, CtF is $50\times$ faster with comparable accuracy. Code is available at https://github.com/wangguanan/light-reid.
Unsupervised Transfer Learning with Self-Supervised Remedy
Jun 08, 2020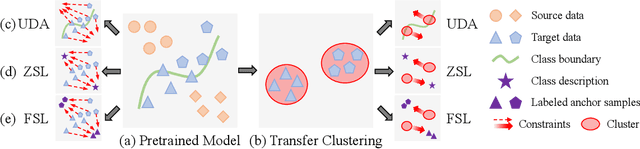
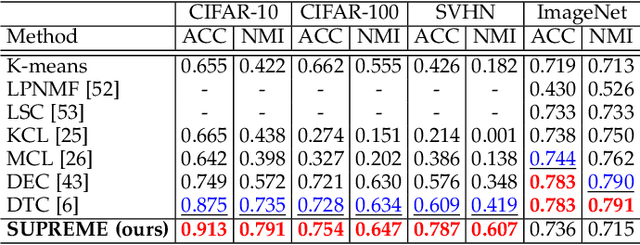
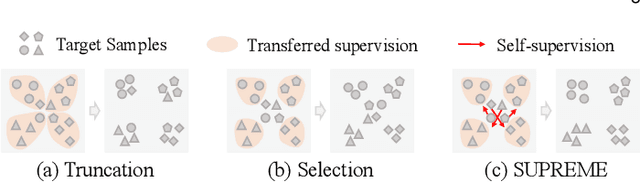
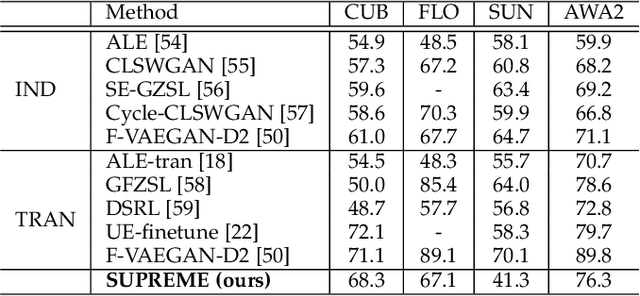
Generalising deep networks to novel domains without manual labels is challenging to deep learning. This problem is intrinsically difficult due to unpredictable changing nature of imagery data distributions in novel domains. Pre-learned knowledge does not transfer well without making strong assumptions about the learned and the novel domains. Different methods have been studied to address the underlying problem based on different assumptions, e.g. from domain adaptation to zero-shot and few-shot learning. In this work, we address this problem by transfer clustering that aims to learn a discriminative latent space of the unlabelled target data in a novel domain by knowledge transfer from labelled related domains. Specifically, we want to leverage relative (pairwise) imagery information, which is freely available and intrinsic to a target domain, to model the target domain image distribution characteristics as well as the prior-knowledge learned from related labelled domains to enable more discriminative clustering of unlabelled target data. Our method mitigates nontransferrable prior-knowledge by self-supervision, benefiting from both transfer and self-supervised learning. Extensive experiments on four datasets for image clustering tasks reveal the superiority of our model over the state-of-the-art transfer clustering techniques. We further demonstrate its competitive transferability on four zero-shot learning benchmarks.
Decentralised Learning from Independent Multi-Domain Labels for Person Re-Identification
Jun 07, 2020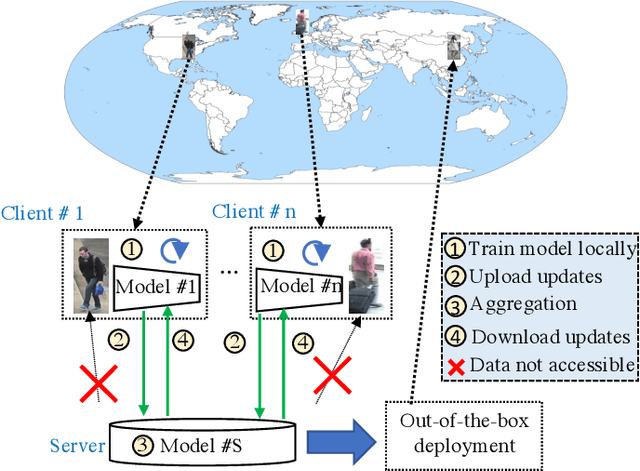
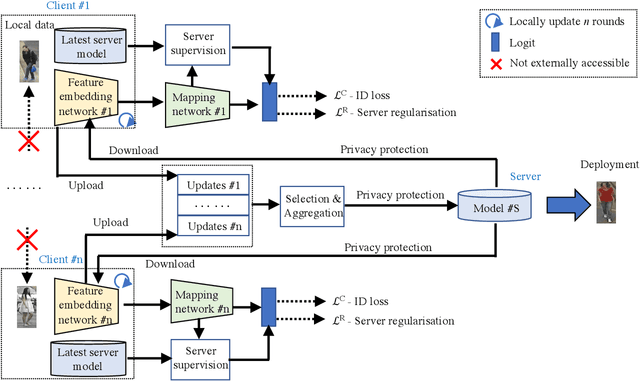
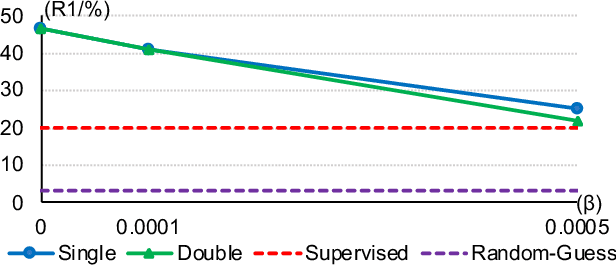
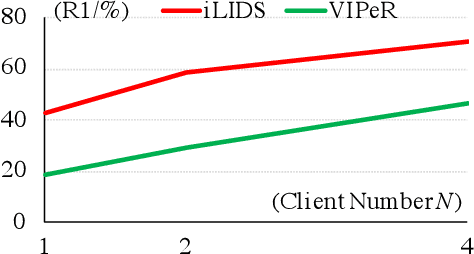
Deep learning has been successful for many computer vision tasks due to the availability of shared and centralised large sized training data. However, increasing awareness of privacy concerns poses new challenges to deep learning, especially for human subject related recognition such as person re-identification (Re-ID). In this work, we solve the Re-ID problem by decentralised model learning from non-shared private training data distributed at multiple user cites of independent multi-domain labels. We propose a novel paradigm called Federated Person Re-Identification (FedReID) to construct a generalisable Re-ID model (a central server) by simultaneously learning collaboratively from multiple privacy-preserved local models (local clients). Each local client learns domain-specific local knowledge from its own set of labels independent from all the other clients (each client has its own non-shared independent labels), while the central server selects and aggregates transferrable local updates to accumulate domain-generic knowledge (a general feature embedding model) without sharing local data therefore inherently protecting privacy. Extensive experiments on 11 Re-ID benchmarks demonstrate the superiority of FedReID against the state-of-the-art Re-ID methods.
Peer Collaborative Learning for Online Knowledge Distillation
Jun 07, 2020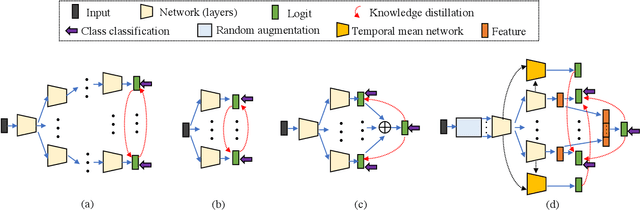
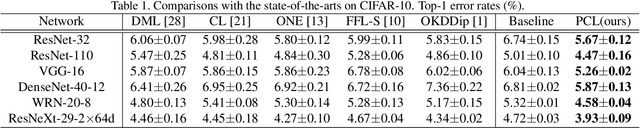
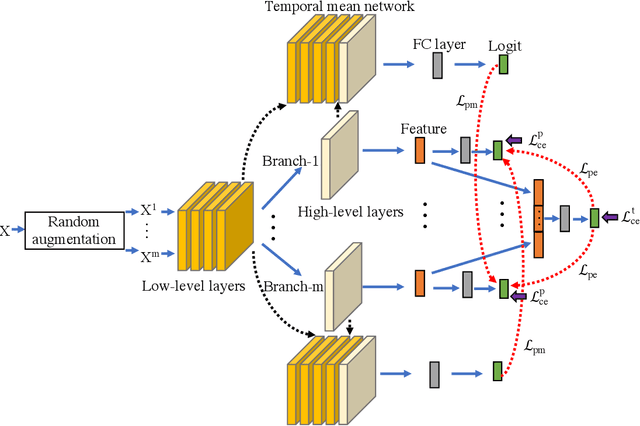

Traditional knowledge distillation uses a two-stage training strategy to transfer knowledge from a high-capacity teacher model to a smaller student model, which relies heavily on the pre-trained teacher. Recent online knowledge distillation alleviates this limitation by collaborative learning, mutual learning and online ensembling, following a one-stage end-to-end training strategy. However, collaborative learning and mutual learning fail to construct an online high-capacity teacher, whilst online ensembling ignores the collaboration among branches and its logit summation impedes the further optimisation of the ensemble teacher. In this work, we propose a novel Peer Collaborative Learning method for online knowledge distillation. Specifically, we employ a multi-branch network (each branch is a peer) and assemble the features from peers with an additional classifier as the peer ensemble teacher to transfer knowledge from the high-capacity teacher to peers and to further optimise the ensemble teacher. Meanwhile, we employ the temporal mean model of each peer as the peer mean teacher to collaboratively transfer knowledge among peers, which facilitates to optimise a more stable model and alleviate the accumulation of training error among peers. Integrating them into a unified framework takes full advantage of online ensembling and network collaboration for improving the quality of online distillation. Extensive experiments on CIFAR-10, CIFAR-100 and ImageNet show that the proposed method not only significantly improves the generalisation capability of various backbone networks, but also outperforms the state-of-the-art alternative methods.
Intra-Camera Supervised Person Re-Identification
Feb 12, 2020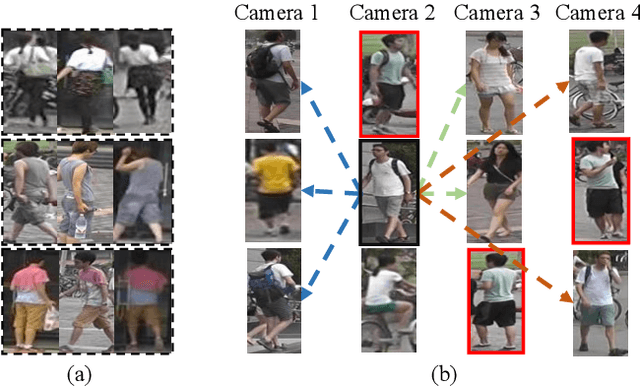
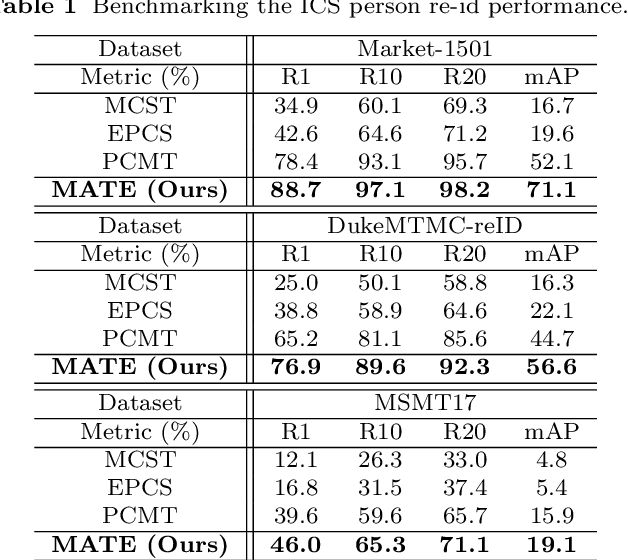
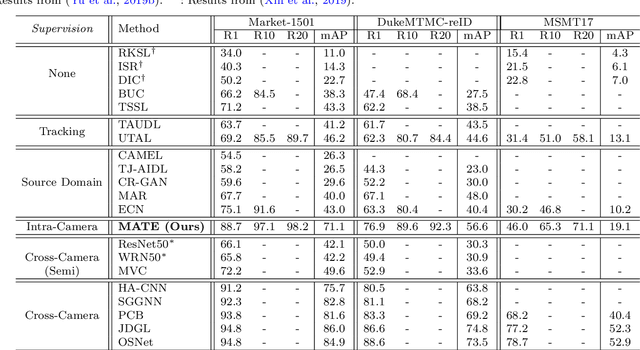
Existing person re-identification (re-id) methods mostly exploit a large set of cross-camera identity labelled training data. This requires a tedious data collection and annotation process, leading to poor scalability in practical re-id applications. On the other hand unsupervised re-id methods do not need identity label information, but they usually suffer from much inferior and insufficient model performance. To overcome these fundamental limitations, we propose a novel person re-identification paradigm based on an idea of independent per-camera identity annotation. This eliminates the most time-consuming and tedious inter-camera identity labelling process, significantly reducing the amount of human annotation efforts. Consequently, it gives rise to a more scalable and more feasible setting, which we call Intra-Camera Supervised (ICS) person re-id, for which we formulate a Multi-tAsk mulTi-labEl (MATE) deep learning method. Specifically, MATE is designed for self-discovering the cross-camera identity correspondence in a per-camera multi-task inference framework. Extensive experiments demonstrate the cost-effectiveness superiority of our method over the alternative approaches on three large person re-id datasets. For example, MATE yields 88.7% rank-1 score on Market-1501 in the proposed ICS person re-id setting, significantly outperforming unsupervised learning models and closely approaching conventional fully supervised learning competitors.
Characteristic Regularisation for Super-Resolving Face Images
Dec 30, 2019
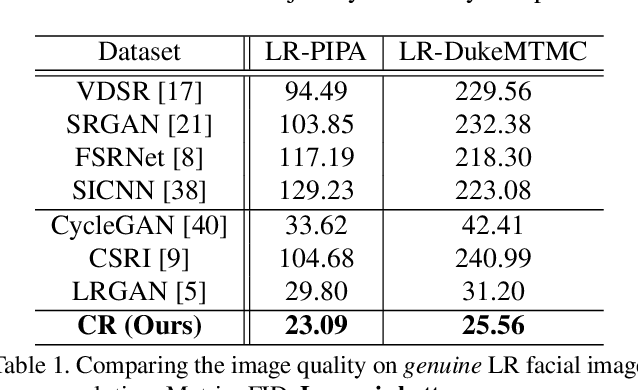
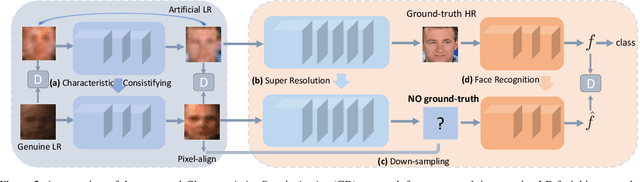
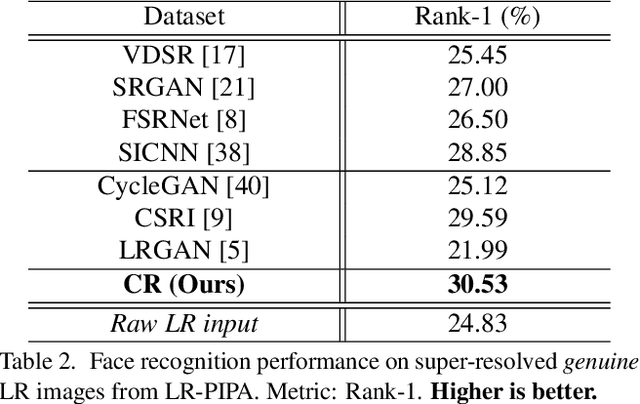
Existing facial image super-resolution (SR) methods focus mostly on improving artificially down-sampled low-resolution (LR) imagery. Such SR models, although strong at handling artificial LR images, often suffer from significant performance drop on genuine LR test data. Previous unsupervised domain adaptation (UDA) methods address this issue by training a model using unpaired genuine LR and HR data as well as cycle consistency loss formulation. However, this renders the model overstretched with two tasks: consistifying the visual characteristics and enhancing the image resolution. Importantly, this makes the end-to-end model training ineffective due to the difficulty of back-propagating gradients through two concatenated CNNs. To solve this problem, we formulate a method that joins the advantages of conventional SR and UDA models. Specifically, we separate and control the optimisations for characteristics consistifying and image super-resolving by introducing Characteristic Regularisation (CR) between them. This task split makes the model training more effective and computationally tractable. Extensive evaluations demonstrate the performance superiority of our method over state-of-the-art SR and UDA models on both genuine and artificial LR facial imagery data.
Intra-Camera Supervised Person Re-Identification: A New Benchmark
Aug 27, 2019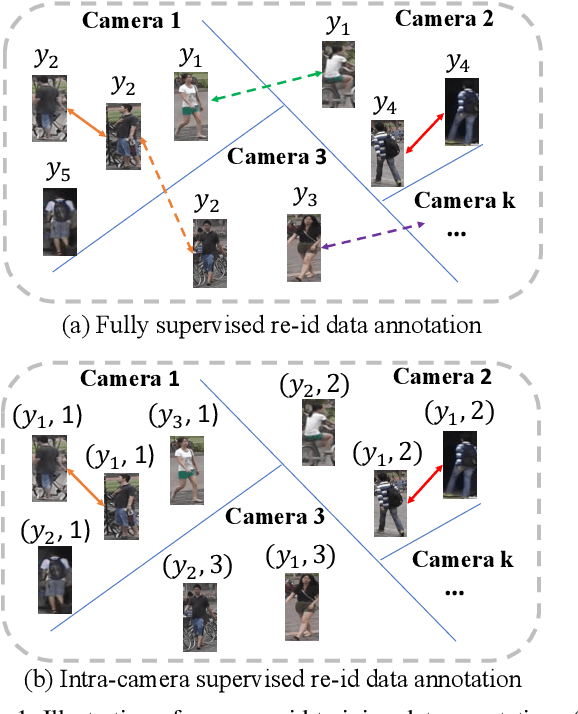
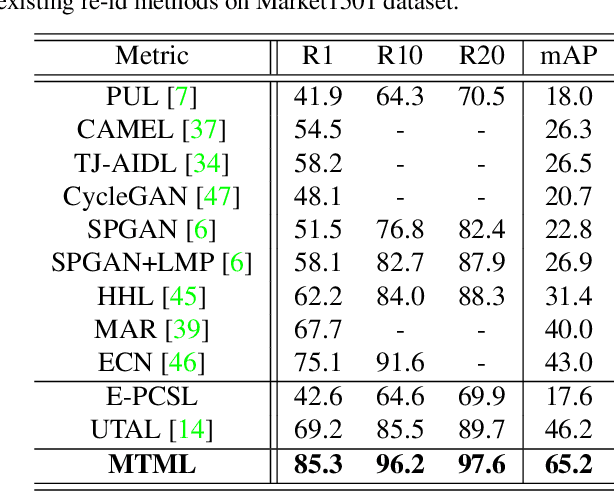
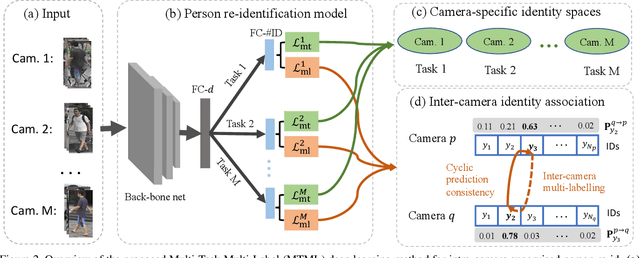
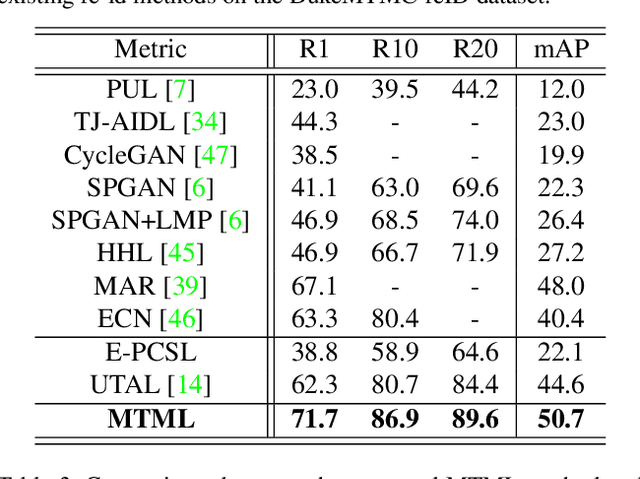
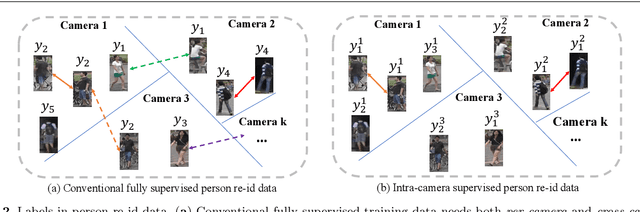
Existing person re-identification (re-id) methods rely mostly on a large set of inter-camera identity labelled training data, requiring a tedious data collection and annotation process therefore leading to poor scalability in practical re-id applications. To overcome this fundamental limitation, we consider person re-identification without inter-camera identity association but only with identity labels independently annotated within each individual camera-view. This eliminates the most time-consuming and tedious inter-camera identity labelling process in order to significantly reduce the amount of human efforts required during annotation. It hence gives rise to a more scalable and more feasible learning scenario, which we call Intra-Camera Supervised (ICS) person re-id. Under this ICS setting with weaker label supervision, we formulate a Multi-Task Multi-Label (MTML) deep learning method. Given no inter-camera association, MTML is specially designed for self-discovering the inter-camera identity correspondence. This is achieved by inter-camera multi-label learning under a joint multi-task inference framework. In addition, MTML can also efficiently learn the discriminative re-id feature representations by fully using the available identity labels within each camera-view. Extensive experiments demonstrate the performance superiority of our MTML model over the state-of-the-art alternative methods on three large-scale person re-id datasets in the proposed intra-camera supervised learning setting.
Zero-Shot Crowd Behavior Recognition
Aug 16, 2019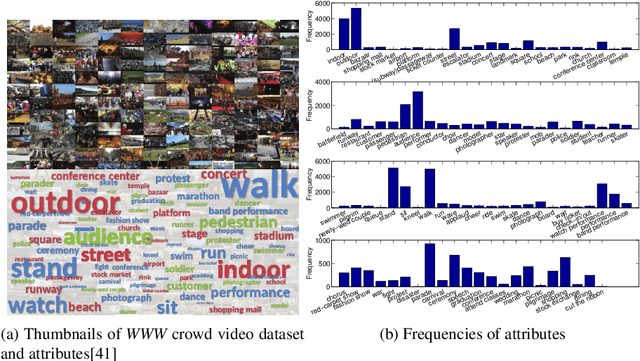

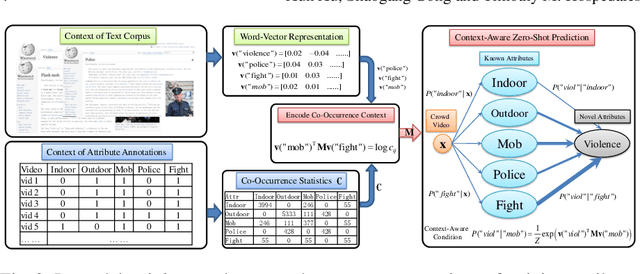
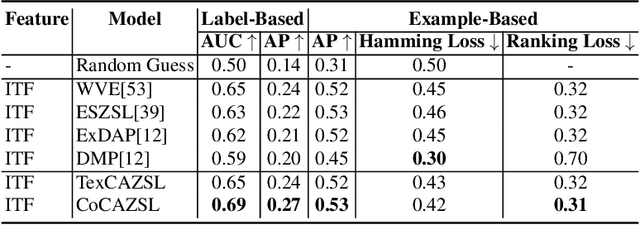
Understanding crowd behavior in video is challenging for computer vision. There have been increasing attempts on modeling crowded scenes by introducing ever larger property ontologies (attributes) and annotating ever larger training datasets. However, in contrast to still images, manually annotating video attributes needs to consider spatiotemporal evolution which is inherently much harder and more costly. Critically, the most interesting crowd behaviors captured in surveillance videos (e.g., street fighting, flash mobs) are either rare, thus have few examples for model training, or unseen previously. Existing crowd analysis techniques are not readily scalable to recognize novel (unseen) crowd behaviors. To address this problem, we investigate and develop methods for recognizing visual crowd behavioral attributes without any training samples, i.e., zero-shot learning crowd behavior recognition. To that end, we relax the common assumption that each individual crowd video instance is only associated with a single crowd attribute. Instead, our model learns to jointly recognize multiple crowd behavioral attributes in each video instance by exploring multiattribute cooccurrence as contextual knowledge for optimizing individual crowd attribute recognition. Joint multilabel attribute prediction in zero-shot learning is inherently nontrivial because cooccurrence statistics does not exist for unseen attributes. To solve this problem, we learn to predict cross-attribute cooccurrence from both online text corpus and multilabel annotation of videos with known attributes. Our experiments show that this approach to modeling multiattribute context not only improves zero-shot crowd behavior recognition on the WWW crowd video dataset, but also generalizes to novel behavior (violence) detection cross-domain in the Violence Flow video dataset.