 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Graph Transformer for NLP Sentiment Classification
Jun 09, 2025Quantum machine learning is a promising direction for building more efficient and expressive models, particularly in domains where understanding complex, structured data is critical. We present the Quantum Graph Transformer (QGT), a hybrid graph-based architecture that integrates a quantum self-attention mechanism into the message-passing framework for structured language modeling. The attention mechanism is implemented using parameterized quantum circuits (PQCs), which enable the model to capture rich contextual relationships while significantly reducing the number of trainable parameters compared to classical attention mechanisms. We evaluate QGT on five sentiment classification benchmarks. Experimental results show that QGT consistently achieves higher or comparable accuracy than existing quantum natural language processing (QNLP) models, including both attention-based and non-attention-based approaches. When compared with an equivalent classical graph transformer, QGT yields an average accuracy improvement of 5.42% on real-world datasets and 4.76% on synthetic datasets. Additionally, QGT demonstrates improved sample efficiency, requiring nearly 50% fewer labeled samples to reach comparable performance on the Yelp dataset. These results highlight the potential of graph-based QNLP techniques for advancing efficient and scalable language understanding.
Graph Neural Networks for Parameterized Quantum Circuits Expressibility Estimation
May 13, 2024



Parameterized quantum circuits (PQCs) are fundamental to quantum machine learning (QML), quantum optimization, and variational quantum algorithms (VQAs). The expressibility of PQCs is a measure that determines their capability to harness the full potential of the quantum state space. It is thus a crucial guidepost to know when selecting a particular PQC ansatz. However, the existing technique for expressibility computation through statistical estimation requires a large number of samples, which poses significant challenges due to time and computational resource constraints. This paper introduces a novel approach for expressibility estimation of PQCs using Graph Neural Networks (GNNs). We demonstrate the predictive power of our GNN model with a dataset consisting of 25,000 samples from the noiseless IBM QASM Simulator and 12,000 samples from three distinct noisy quantum backends. The model accurately estimates expressibility, with root mean square errors (RMSE) of 0.05 and 0.06 for the noiseless and noisy backends, respectively. We compare our model's predictions with reference circuits [Sim and others, QuTe'2019] and IBM Qiskit's hardware-efficient ansatz sets to further evaluate our model's performance. Our experimental evaluation in noiseless and noisy scenarios reveals a close alignment with ground truth expressibility values, highlighting the model's efficacy. Moreover, our model exhibits promising extrapolation capabilities, predicting expressibility values with low RMSE for out-of-range qubit circuits trained solely on only up to 5-qubit circuit sets. This work thus provides a reliable means of efficiently evaluating the expressibility of diverse PQCs on noiseless simulators and hardware.
BB-ML: Basic Block Performance Prediction using Machine Learning Techniques
Feb 18, 2022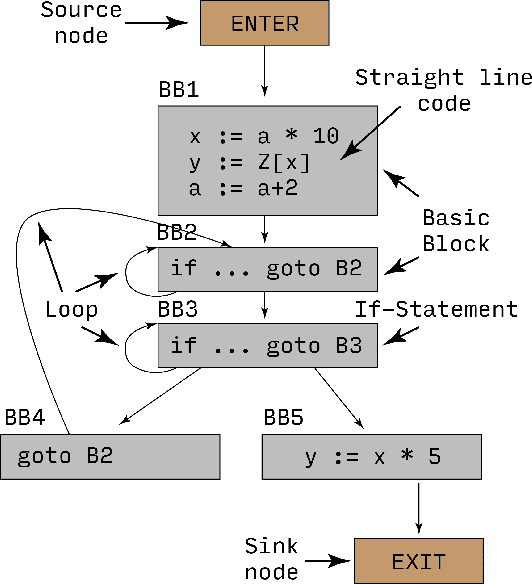
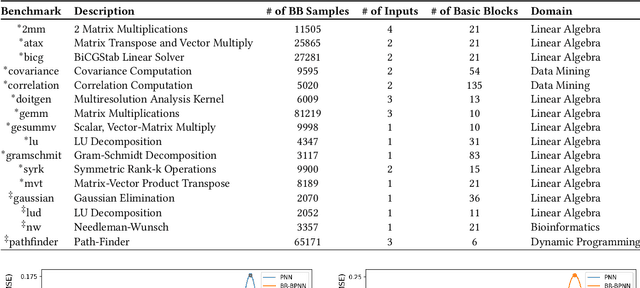
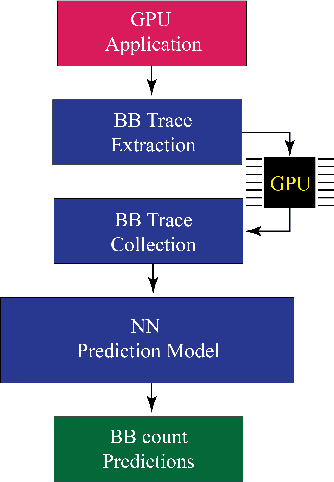
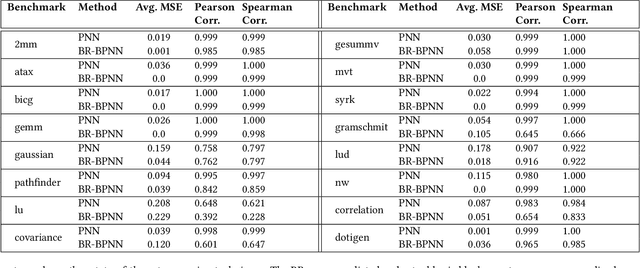
Recent years have seen the adoption of Machine Learning (ML) techniques to predict the performance of large-scale applications, mostly at a coarse level. In contrast, we propose to use ML techniques for performance prediction at much finer granularity, namely at the levels of Basic Block (BB), which are the single entry-single exit code blocks that are used as analysis tools by all compilers to break down a large code into manageable pieces. Utilizing ML and BB analysis together can enable scalable hardware-software co-design beyond the current state of the art. In this work, we extrapolate the basic block execution counts of GPU applications for large inputs sizes from the counts of smaller input sizes of the same application. We employ two ML models, a Poisson Neural Network (PNN) and a Bayesian Regularization Backpropagation Neural Network (BR-BPNN). We train both models using the lowest input values of the application and random input values to predict basic block counts. Results show that our models accurately predict the basic block execution counts of 16 benchmark applications. For PNN and BR-BPNN models, we achieve an average accuracy of 93.5% and 95.6%, respectively, while extrapolating the basic block counts for large input sets when the model is trained using smaller input sets. Additionally, the models show an average accuracy of 97.7% and 98.1%, respectively, while predicting basic block counts on random instances.