 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable, Symbiotic, AI and Non-AI Agent Based Parallel Discrete Event Simulations
May 28, 2025To fully leverage the potential of artificial intelligence (AI) systems in a trustworthy manner, it is desirable to couple multiple AI and non-AI systems together seamlessly for constraining and ensuring correctness of the output. This paper introduces a novel parallel discrete event simulation (PDES) based methodology to combine multiple AI and non-AI agents in a causal, rule-based way. Our approach tightly integrates the concept of passage of time, with each agent considered as an entity in the PDES framework and responding to prior requests from other agents. Such coupling mechanism enables the agents to work in a co-operative environment towards a common goal while many tasks run in parallel throughout the simulation. It further enables setting up boundaries to the outputs of the AI agents by applying necessary dynamic constraints using non-AI agents while allowing for scalability through deployment of hundreds of such agents in a larger compute cluster. Distributing smaller AI agents can enable extremely scalable simulations in the future, addressing local memory bottlenecks for model parameter storage. Within a PDES involving both AI and non-AI agents, we break down the problem at hand into structured steps, when necessary, providing a set of multiple choices to the AI agents, and then progressively solve these steps towards a final goal. At each step, the non-AI agents act as unbiased auditors, verifying each action by the AI agents so that certain rules of engagement are followed. We evaluate our approach by solving four problems from four different domains and comparing the results with those from AI models alone. Our results show greater accuracy in solving problems from various domains where the AI models struggle to solve the problems solely by themselves. Results show that overall accuracy of our approach is 68% where as the accuracy of vanilla models is less than 23%.
Generative Discrete Event Process Simulation for Hidden Markov Models to Predict Competitor Time-to-Market
Nov 06, 2024



We study the challenge of predicting the time at which a competitor product, such as a novel high-capacity EV battery or a new car model, will be available to customers; as new information is obtained, this time-to-market estimate is revised. Our scenario is as follows: We assume that the product is under development at a Firm B, which is a competitor to Firm A; as they are in the same industry, Firm A has a relatively good understanding of the processes and steps required to produce the product. While Firm B tries to keep its activities hidden (think of stealth-mode for start-ups), Firm A is nevertheless able to gain periodic insights by observing what type of resources Firm B is using. We show how Firm A can build a model that predicts when Firm B will be ready to sell its product; the model leverages knowledge of the underlying processes and required resources to build a Parallel Discrete Simulation (PDES)-based process model that it then uses as a generative model to train a Hidden Markov Model (HMM). We study the question of how many resource observations Firm A requires in order to accurately assess the current state of development at Firm B. In order to gain general insights into the capabilities of this approach, we study the effect of different process graph densities, different densities of the resource-activity maps, etc., and also scaling properties as we increase the number resource counts. We find that in most cases, the HMM achieves a prediction accuracy of 70 to 80 percent after 20 (daily) observations of a production process that lasts 150 days on average and we characterize the effects of different problem instance densities on this prediction accuracy. Our results give insight into the level of market knowledge required for accurate and early time-to-market prediction.
BB-ML: Basic Block Performance Prediction using Machine Learning Techniques
Feb 18, 2022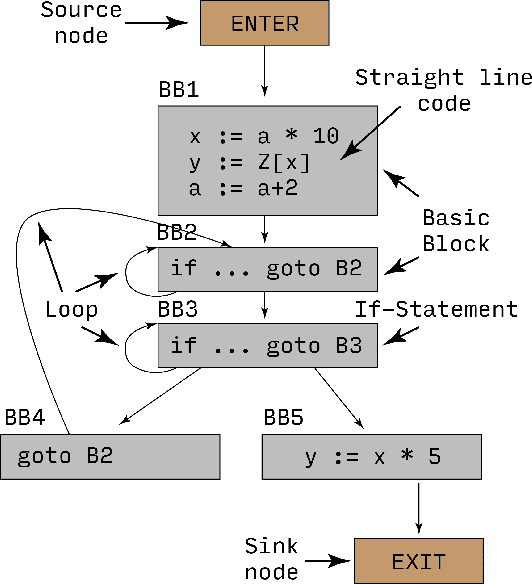
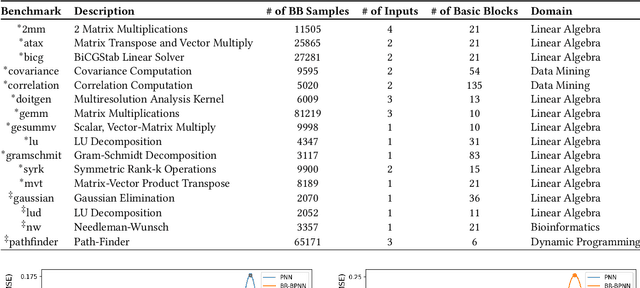
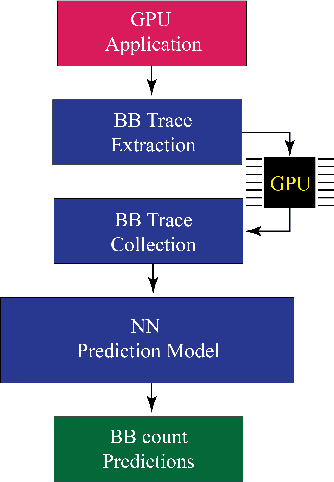
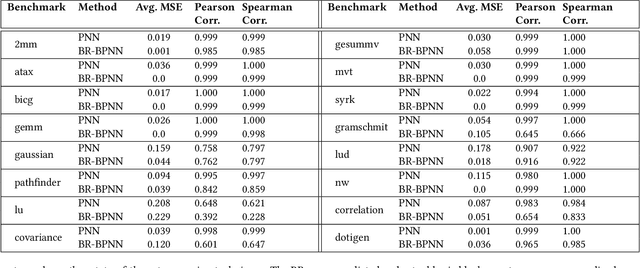
Recent years have seen the adoption of Machine Learning (ML) techniques to predict the performance of large-scale applications, mostly at a coarse level. In contrast, we propose to use ML techniques for performance prediction at much finer granularity, namely at the levels of Basic Block (BB), which are the single entry-single exit code blocks that are used as analysis tools by all compilers to break down a large code into manageable pieces. Utilizing ML and BB analysis together can enable scalable hardware-software co-design beyond the current state of the art. In this work, we extrapolate the basic block execution counts of GPU applications for large inputs sizes from the counts of smaller input sizes of the same application. We employ two ML models, a Poisson Neural Network (PNN) and a Bayesian Regularization Backpropagation Neural Network (BR-BPNN). We train both models using the lowest input values of the application and random input values to predict basic block counts. Results show that our models accurately predict the basic block execution counts of 16 benchmark applications. For PNN and BR-BPNN models, we achieve an average accuracy of 93.5% and 95.6%, respectively, while extrapolating the basic block counts for large input sets when the model is trained using smaller input sets. Additionally, the models show an average accuracy of 97.7% and 98.1%, respectively, while predicting basic block counts on random instances.