 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorCode: Face Morphing Attack Generation using Generative Codebooks
Oct 10, 2024



Face recognition systems (FRS) can be compromised by face morphing attacks, which blend textural and geometric information from multiple facial images. The rapid evolution of generative AI, especially Generative Adversarial Networks (GAN) or Diffusion models, where encoded images are interpolated to generate high-quality face morphing images. In this work, we present a novel method for the automatic face morphing generation method \textit{MorCode}, which leverages a contemporary encoder-decoder architecture conditioned on codebook learning to generate high-quality morphing images. Extensive experiments were performed on the newly constructed morphing dataset using five state-of-the-art morphing generation techniques using both digital and print-scan data. The attack potential of the proposed morphing generation technique, \textit{MorCode}, was benchmarked using three different face recognition systems. The obtained results indicate the highest attack potential of the proposed \textit{MorCode} when compared with five state-of-the-art morphing generation methods on both digital and print scan data.
Gumbel Rao Monte Carlo based Bi-Modal Neural Architecture Search for Audio-Visual Deepfake Detection
Oct 09, 2024



Deepfakes pose a critical threat to biometric authentication systems by generating highly realistic synthetic media. Existing multimodal deepfake detectors often struggle to adapt to diverse data and rely on simple fusion methods. To address these challenges, we propose Gumbel-Rao Monte Carlo Bi-modal Neural Architecture Search (GRMC-BMNAS), a novel architecture search framework that employs Gumbel-Rao Monte Carlo sampling to optimize multimodal fusion. It refines the Straight through Gumbel Softmax (STGS) method by reducing variance with Rao-Blackwellization, stabilizing network training. Using a two-level search approach, the framework optimizes the network architecture, parameters, and performance. Crucial features are efficiently identified from backbone networks, while within the cell structure, a weighted fusion operation integrates information from various sources. By varying parameters such as temperature and number of Monte carlo samples yields an architecture that maximizes classification performance and better generalisation capability. Experimental results on the FakeAVCeleb and SWAN-DF datasets demonstrate an impressive AUC percentage of 95.4\%, achieved with minimal model parameters.
Straight Through Gumbel Softmax Estimator based Bimodal Neural Architecture Search for Audio-Visual Deepfake Detection
Jun 19, 2024



Deepfakes are a major security risk for biometric authentication. This technology creates realistic fake videos that can impersonate real people, fooling systems that rely on facial features and voice patterns for identification. Existing multimodal deepfake detectors rely on conventional fusion methods, such as majority rule and ensemble voting, which often struggle to adapt to changing data characteristics and complex patterns. In this paper, we introduce the Straight-through Gumbel-Softmax (STGS) framework, offering a comprehensive approach to search multimodal fusion model architectures. Using a two-level search approach, the framework optimizes the network architecture, parameters, and performance. Initially, crucial features were efficiently identified from backbone networks, whereas within the cell structure, a weighted fusion operation integrated information from various sources. An architecture that maximizes the classification performance is derived by varying parameters such as temperature and sampling time. The experimental results on the FakeAVCeleb and SWAN-DF datasets demonstrated an impressive AUC value 94.4\% achieved with minimal model parameters.
MLSD-GAN -- Generating Strong High Quality Face Morphing Attacks using Latent Semantic Disentanglement
Apr 19, 2024



Face-morphing attacks are a growing concern for biometric researchers, as they can be used to fool face recognition systems (FRS). These attacks can be generated at the image level (supervised) or representation level (unsupervised). Previous unsupervised morphing attacks have relied on generative adversarial networks (GANs). More recently, researchers have used linear interpolation of StyleGAN-encoded images to generate morphing attacks. In this paper, we propose a new method for generating high-quality morphing attacks using StyleGAN disentanglement. Our approach, called MLSD-GAN, spherically interpolates the disentangled latents to produce realistic and diverse morphing attacks. We evaluate the vulnerability of MLSD-GAN on two deep-learning-based FRS techniques. The results show that MLSD-GAN poses a significant threat to FRS, as it can generate morphing attacks that are highly effective at fooling these systems.
BOXREC: Recommending a Box of Preferred Outfits in Online Shopping
Feb 26, 2024



Over the past few years, automation of outfit composition has gained much attention from the research community. Most of the existing outfit recommendation systems focus on pairwise item compatibility prediction (using visual and text features) to score an outfit combination having several items, followed by recommendation of top-n outfits or a capsule wardrobe having a collection of outfits based on user's fashion taste. However, none of these consider user's preference of price-range for individual clothing types or an overall shopping budget for a set of items. In this paper, we propose a box recommendation framework - BOXREC - which at first, collects user preferences across different item types (namely, top-wear, bottom-wear and foot-wear) including price-range of each type and a maximum shopping budget for a particular shopping session. It then generates a set of preferred outfits by retrieving all types of preferred items from the database (according to user specified preferences including price-ranges), creates all possible combinations of three preferred items (belonging to distinct item types) and verifies each combination using an outfit scoring framework - BOXREC-OSF. Finally, it provides a box full of fashion items, such that different combinations of the items maximize the number of outfits suitable for an occasion while satisfying maximum shopping budget. Empirical results show superior performance of BOXREC-OSF over the baseline methods.
Efficient Indexing of Meta-Data (Extracted from Educational Videos)
Dec 11, 2023Video lectures are becoming more popular and in demand as online classroom teaching is becoming more prevalent. Massive Open Online Courses (MOOCs), such as NPTEL, have been creating high-quality educational content that is freely accessible to students online. A large number of colleges across the country are now using NPTEL videos in their classrooms. So more video lectures are being recorded, maintained, and uploaded. These videos generally contain information about that video before the lecture begins. We generally observe that these educational videos have metadata containing five to six attributes: Institute Name, Publisher Name, Department Name, Professor Name, Subject Name, and Topic Name. It would be easy to maintain these videos if we could organize them according to their categories. The indexing of these videos based on this information is beneficial for students all around the world to efficiently utilise these videos. In this project, we are trying to get the metadata information mentioned above from the video lectures.
hf0: A hybrid pitch extraction method for multimodal voice
Apr 22, 2019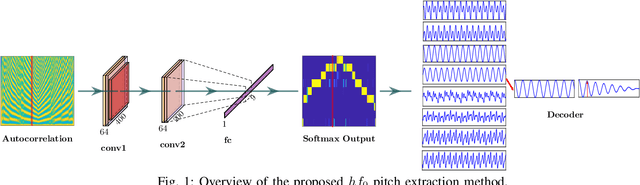
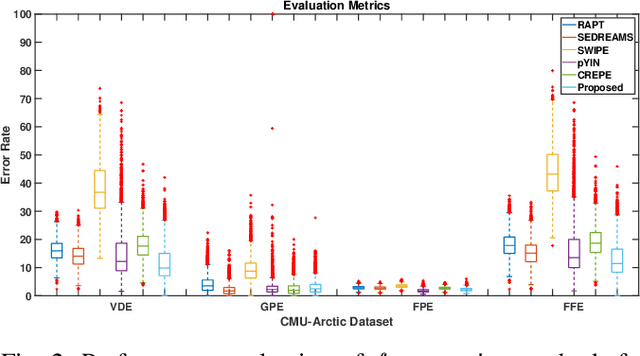
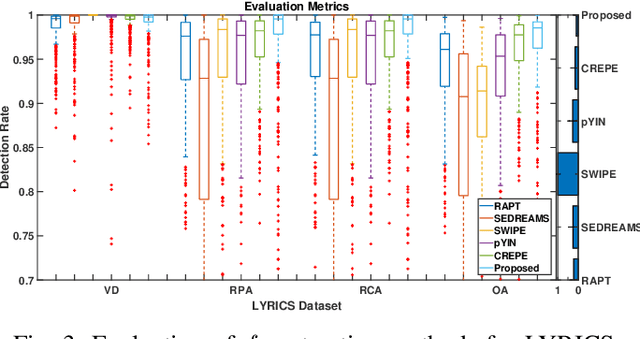

Pitch or fundamental frequency (f0) extraction is a fundamental problem studied extensively for its potential applications in speech and clinical applications. In literature, explicit mode specific (modal speech or singing voice or emotional/ expressive speech or noisy speech) signal processing and deep learning f0 extraction methods that exploit the quasi periodic nature of the signal in time, harmonic property in spectral or combined form to extract the pitch is developed. Hence, there is no single unified method which can reliably extract the pitch from various modes of the acoustic signal. In this work, we propose a hybrid f0 extraction method which seamlessly extracts the pitch across modes of speech production with very high accuracy required for many applications. The proposed hybrid model exploits the advantages of deep learning and signal processing methods to minimize the pitch detection error and adopts to various modes of acoustic signal. Specifically, we propose an ordinal regression convolutional neural networks to map the periodicity rich input representation to obtain the nominal pitch classes which drastically reduces the number of classes required for pitch detection unlike other deep learning approaches. Further, the accurate f0 is estimated from the nominal pitch class labels by filtering and autocorrelation. We show that the proposed method generalizes to the unseen modes of voice production and various noises for large scale datasets. Also, the proposed hybrid model significantly reduces the learning parameters required to train the deep model compared to other methods. Furthermore,the evaluation measures showed that the proposed method is significantly better than the state-of-the-art signal processing and deep learning approaches.
Glottal Closure Instants Detection From Pathological Acoustic Speech Signal Using Deep Learning
Nov 25, 2018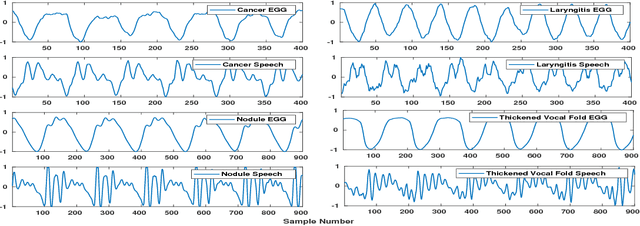
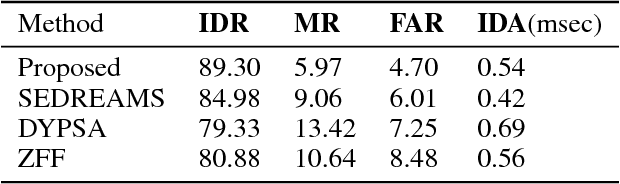
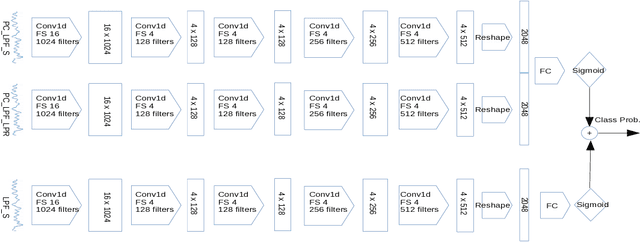
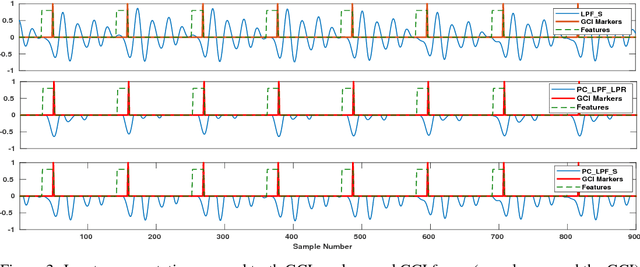
In this paper, we propose a classification based glottal closure instants (GCI) detection from pathological acoustic speech signal, which finds many applications in vocal disorder analysis. Till date, GCI for pathological disorder is extracted from laryngeal (glottal source) signal recorded from Electroglottograph, a dedicated device designed to measure the vocal folds vibration around the larynx. We have created a pathological dataset which consists of simultaneous recordings of glottal source and acoustic speech signal of six different disorders from vocal disordered patients. The GCI locations are manually annotated for disorder analysis and supervised learning. We have proposed convolutional neural network based GCI detection method by fusing deep acoustic speech and linear prediction residual features for robust GCI detection. The experimental results showed that the proposed method is significantly better than the state-of-the-art GCI detection methods.