 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeLFusion: Latent Diffusion for Behavior-Driven Human Motion Prediction
Nov 25, 2022Stochastic human motion prediction (HMP) has generally been tackled with generative adversarial networks and variational autoencoders. Most prior works aim at predicting highly diverse movements in terms of the skeleton joints' dispersion. This has led to methods predicting fast and motion-divergent movements, which are often unrealistic and incoherent with past motion. Such methods also neglect contexts that need to anticipate diverse low-range behaviors, or actions, with subtle joint displacements. To address these issues, we present BeLFusion, a model that, for the first time, leverages latent diffusion models in HMP to sample from a latent space where behavior is disentangled from pose and motion. As a result, diversity is encouraged from a behavioral perspective. Thanks to our behavior coupler's ability to transfer sampled behavior to ongoing motion, BeLFusion's predictions display a variety of behaviors that are significantly more realistic than the state of the art. To support it, we introduce two metrics, the Area of the Cumulative Motion Distribution, and the Average Pairwise Distance Error, which are correlated to our definition of realism according to a qualitative study with 126 participants. Finally, we prove BeLFusion's generalization power in a new cross-dataset scenario for stochastic HMP.
SoccerNet 2022 Challenges Results
Oct 05, 2022
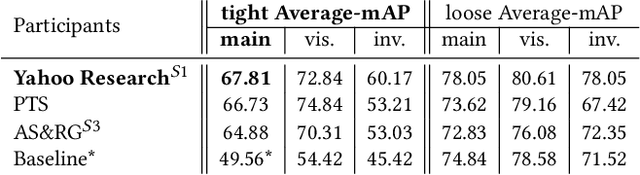
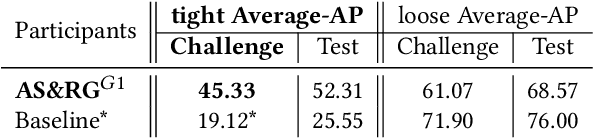
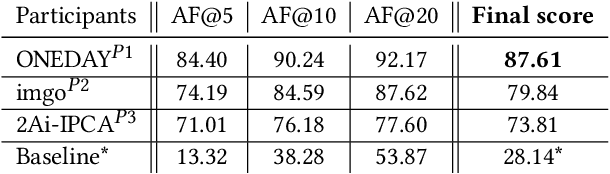
The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.
NeurIPS'22 Cross-Domain MetaDL competition: Design and baseline results
Aug 31, 2022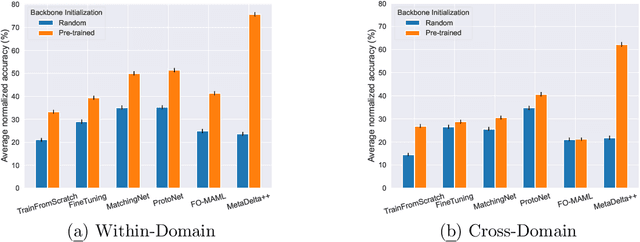

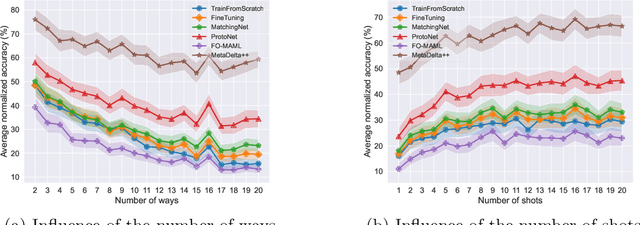

We present the design and baseline results for a new challenge in the ChaLearn meta-learning series, accepted at NeurIPS'22, focusing on "cross-domain" meta-learning. Meta-learning aims to leverage experience gained from previous tasks to solve new tasks efficiently (i.e., with better performance, little training data, and/or modest computational resources). While previous challenges in the series focused on within-domain few-shot learning problems, with the aim of learning efficiently N-way k-shot tasks (i.e., N class classification problems with k training examples), this competition challenges the participants to solve "any-way" and "any-shot" problems drawn from various domains (healthcare, ecology, biology, manufacturing, and others), chosen for their humanitarian and societal impact. To that end, we created Meta-Album, a meta-dataset of 40 image classification datasets from 10 domains, from which we carve out tasks with any number of "ways" (within the range 2-20) and any number of "shots" (within the range 1-20). The competition is with code submission, fully blind-tested on the CodaLab challenge platform. The code of the winners will be open-sourced, enabling the deployment of automated machine learning solutions for few-shot image classification across several domains.
A Non-Anatomical Graph Structure for isolated hand gesture separation in continuous gesture sequences
Jul 15, 2022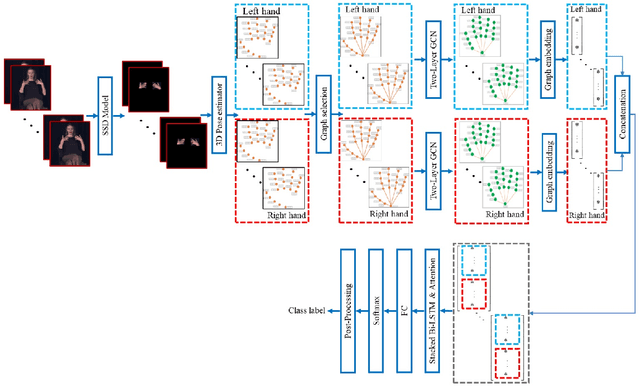
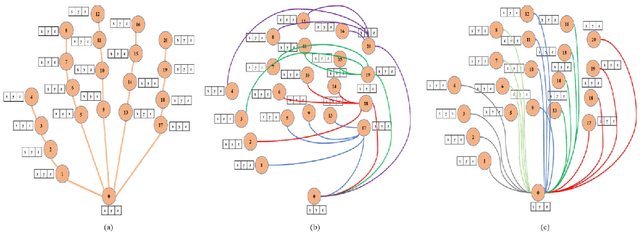
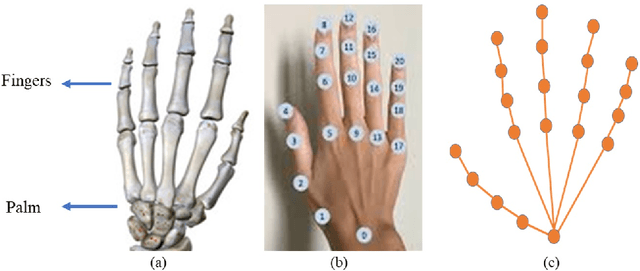
Continuous Hand Gesture Recognition (CHGR) has been extensively studied by researchers in the last few decades. Recently, one model has been presented to deal with the challenge of the boundary detection of isolated gestures in a continuous gesture video [17]. To enhance the model performance and also replace the handcrafted feature extractor in the presented model in [17], we propose a GCN model and combine it with the stacked Bi-LSTM and Attention modules to push the temporal information in the video stream. Considering the breakthroughs of GCN models for skeleton modality, we propose a two-layer GCN model to empower the 3D hand skeleton features. Finally, the class probabilities of each isolated gesture are fed to the post-processing module, borrowed from [17]. Furthermore, we replace the anatomical graph structure with some non-anatomical graph structures. Due to the lack of a large dataset, including both the continuous gesture sequences and the corresponding isolated gestures, three public datasets in Dynamic Hand Gesture Recognition (DHGR), RKS-PERSIANSIGN, and ASLVID, are used for evaluation. Experimental results show the superiority of the proposed model in dealing with isolated gesture boundaries detection in continuous gesture sequences
UniUD-FBK-UB-UniBZ Submission to the EPIC-Kitchens-100 Multi-Instance Retrieval Challenge 2022
Jun 22, 2022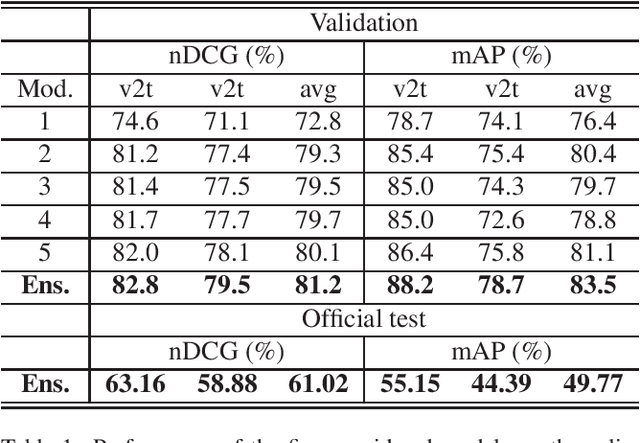
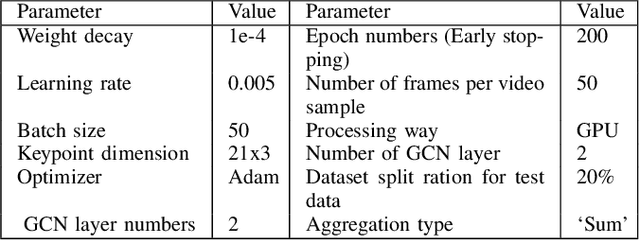
This report presents the technical details of our submission to the EPIC-Kitchens-100 Multi-Instance Retrieval Challenge 2022. To participate in the challenge, we designed an ensemble consisting of different models trained with two recently developed relevance-augmented versions of the widely used triplet loss. Our submission, visible on the public leaderboard, obtains an average score of 61.02% nDCG and 49.77% mAP.
Relevance-based Margin for Contrastively-trained Video Retrieval Models
Apr 27, 2022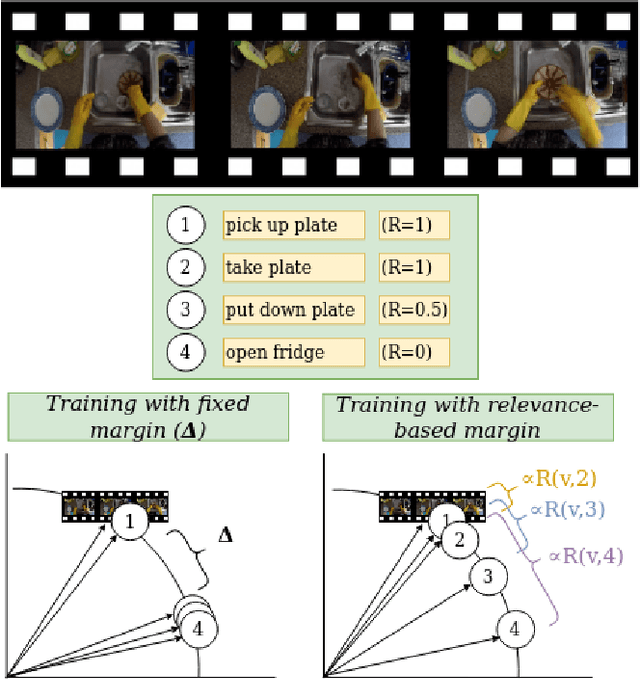
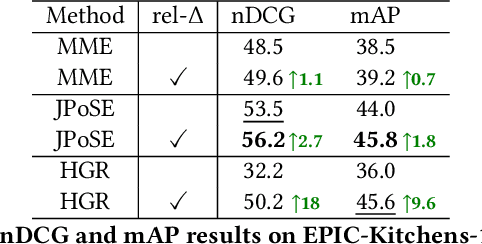
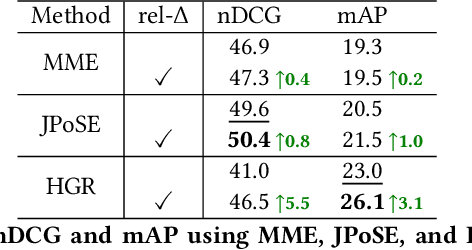
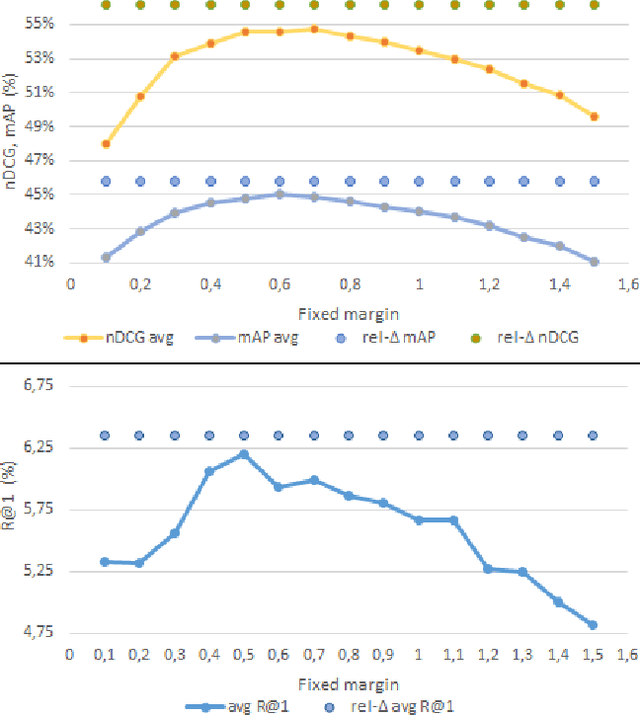
Video retrieval using natural language queries has attracted increasing interest due to its relevance in real-world applications, from intelligent access in private media galleries to web-scale video search. Learning the cross-similarity of video and text in a joint embedding space is the dominant approach. To do so, a contrastive loss is usually employed because it organizes the embedding space by putting similar items close and dissimilar items far. This framework leads to competitive recall rates, as they solely focus on the rank of the groundtruth items. Yet, assessing the quality of the ranking list is of utmost importance when considering intelligent retrieval systems, since multiple items may share similar semantics, hence a high relevance. Moreover, the aforementioned framework uses a fixed margin to separate similar and dissimilar items, treating all non-groundtruth items as equally irrelevant. In this paper we propose to use a variable margin: we argue that varying the margin used during training based on how much relevant an item is to a given query, i.e. a relevance-based margin, easily improves the quality of the ranking lists measured through nDCG and mAP. We demonstrate the advantages of our technique using different models on EPIC-Kitchens-100 and YouCook2. We show that even if we carefully tuned the fixed margin, our technique (which does not have the margin as a hyper-parameter) would still achieve better performance. Finally, extensive ablation studies and qualitative analysis support the robustness of our approach. Code will be released at \url{https://github.com/aranciokov/RelevanceMargin-ICMR22}.
Word separation in continuous sign language using isolated signs and post-processing
Apr 13, 2022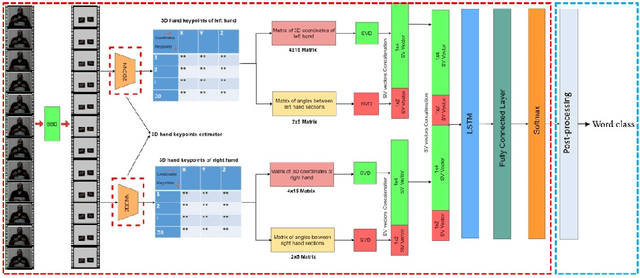

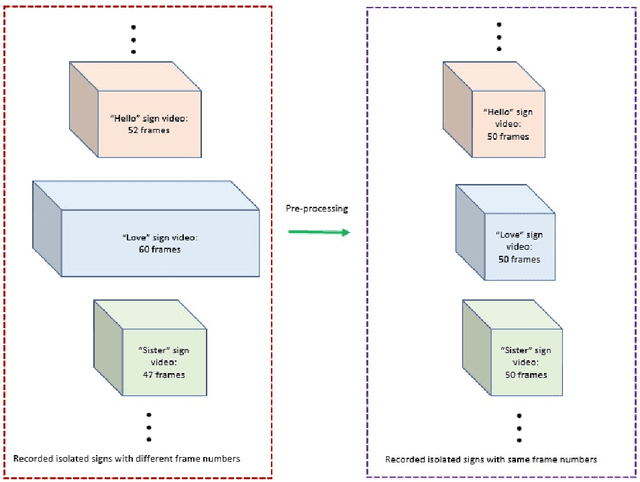

Continuous Sign Language Recognition (CSLR) is a long challenging task in Computer Vision due to the difficulties in detecting the explicit boundaries between the words in a sign sentence. To deal with this challenge, we propose a two-stage model. In the first stage, the predictor model, which includes a combination of CNN, SVD, and LSTM, is trained with the isolated signs. In the second stage, we apply a post-processing algorithm to the Softmax outputs obtained from the first part of the model in order to separate the isolated signs in the continuous signs. Due to the lack of a large dataset, including both the sign sequences and the corresponding isolated signs, two public datasets in Isolated Sign Language Recognition (ISLR), RKS-PERSIANSIGN and ASLVID, are used for evaluation. Results of the continuous sign videos confirm the efficiency of the proposed model to deal with isolated sign boundaries detection.
Towards explaining the generalization gap in neural networks using topological data analysis
Mar 23, 2022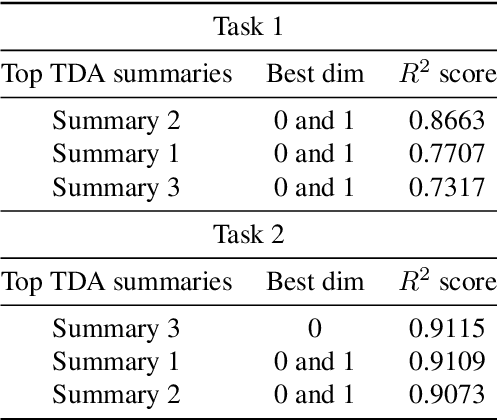
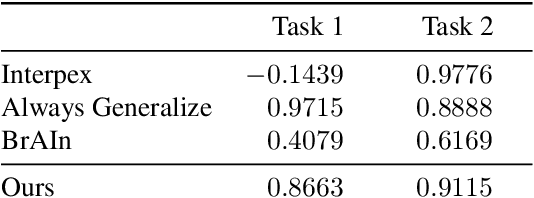
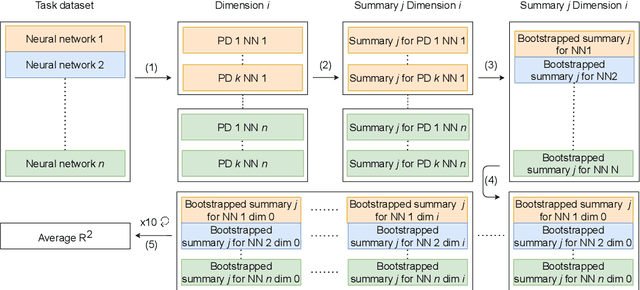
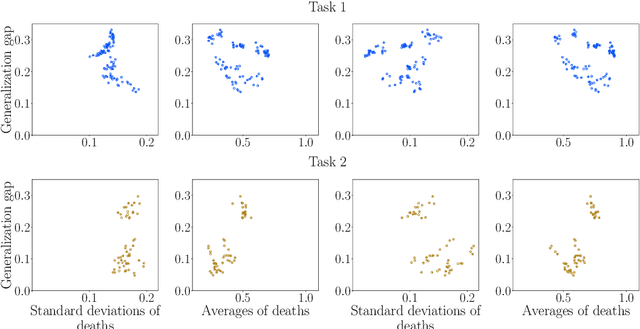
Understanding how neural networks generalize on unseen data is crucial for designing more robust and reliable models. In this paper, we study the generalization gap of neural networks using methods from topological data analysis. For this purpose, we compute homological persistence diagrams of weighted graphs constructed from neuron activation correlations after a training phase, aiming to capture patterns that are linked to the generalization capacity of the network. We compare the usefulness of different numerical summaries from persistence diagrams and show that a combination of some of them can accurately predict and partially explain the generalization gap without the need of a test set. Evaluation on two computer vision recognition tasks (CIFAR10 and SVHN) shows competitive generalization gap prediction when compared against state-of-the-art methods.
Towards Self-Supervised Gaze Estimation
Mar 21, 2022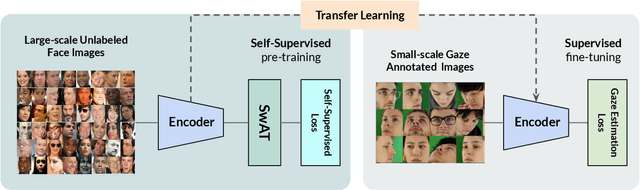

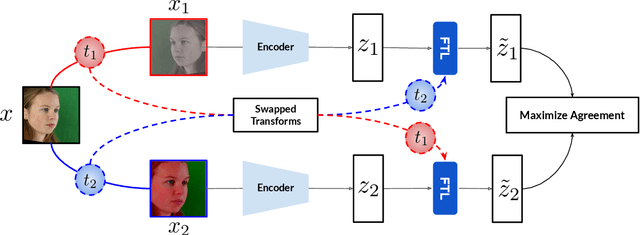
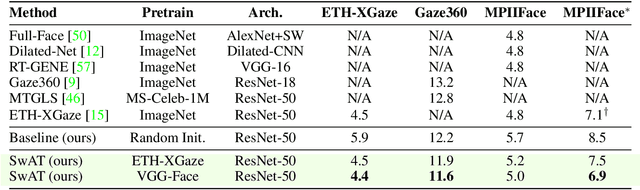
Recent joint embedding-based self-supervised methods have surpassed standard supervised approaches on various image recognition tasks such as image classification. These self-supervised methods aim at maximizing agreement between features extracted from two differently transformed views of the same image, which results in learning an invariant representation with respect to appearance and geometric image transformations. However, the effectiveness of these approaches remains unclear in the context of gaze estimation, a structured regression task that requires equivariance under geometric transformations (e.g., rotations, horizontal flip). In this work, we propose SwAT, an equivariant version of the online clustering-based self-supervised approach SwAV, to learn more informative representations for gaze estimation. We identify the most effective image transformations for self-supervised pretraining and demonstrate that SwAT, with ResNet-50 and supported with uncurated unlabeled face images, outperforms state-of-the-art gaze estimation methods and supervised baselines in various experiments. In particular, we achieve up to 57% and 25% improvements in cross-dataset and within-dataset evaluation tasks on existing benchmarks (ETH-XGaze, Gaze360, and MPIIFaceGaze).
Gate-Shift-Fuse for Video Action Recognition
Mar 16, 2022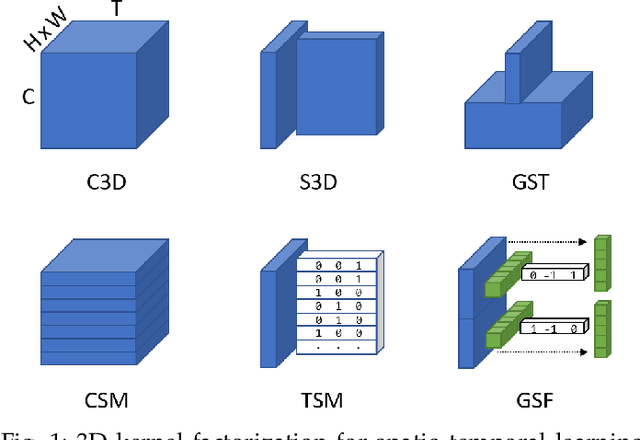
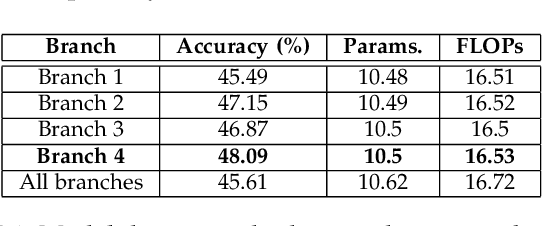
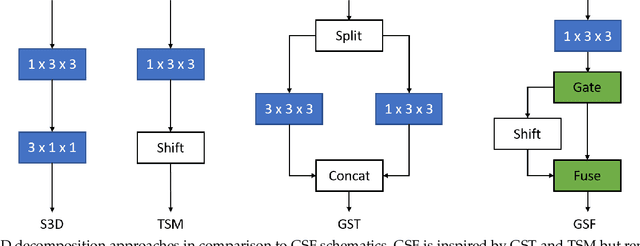
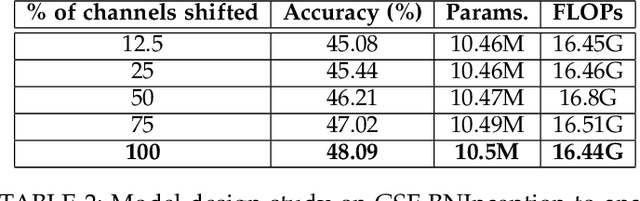
Convolutional Neural Networks are the de facto models for image recognition. However 3D CNNs, the straight forward extension of 2D CNNs for video recognition, have not achieved the same success on standard action recognition benchmarks. One of the main reasons for this reduced performance of 3D CNNs is the increased computational complexity requiring large scale annotated datasets to train them in scale. 3D kernel factorization approaches have been proposed to reduce the complexity of 3D CNNs. Existing kernel factorization approaches follow hand-designed and hard-wired techniques. In this paper we propose Gate-Shift-Fuse (GSF), a novel spatio-temporal feature extraction module which controls interactions in spatio-temporal decomposition and learns to adaptively route features through time and combine them in a data dependent manner. GSF leverages grouped spatial gating to decompose input tensor and channel weighting to fuse the decomposed tensors. GSF can be inserted into existing 2D CNNs to convert them into an efficient and high performing spatio-temporal feature extractor, with negligible parameter and compute overhead. We perform an extensive analysis of GSF using two popular 2D CNN families and achieve state-of-the-art or competitive performance on five standard action recognition benchmarks. Code and models will be made publicly available at https://github.com/swathikirans/GSF.