 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Modulate pre-trained Models in RL
Jun 26, 2023Reinforcement Learning (RL) has been successful in various domains like robotics, game playing, and simulation. While RL agents have shown impressive capabilities in their specific tasks, they insufficiently adapt to new tasks. In supervised learning, this adaptation problem is addressed by large-scale pre-training followed by fine-tuning to new down-stream tasks. Recently, pre-training on multiple tasks has been gaining traction in RL. However, fine-tuning a pre-trained model often suffers from catastrophic forgetting, that is, the performance on the pre-training tasks deteriorates when fine-tuning on new tasks. To investigate the catastrophic forgetting phenomenon, we first jointly pre-train a model on datasets from two benchmark suites, namely Meta-World and DMControl. Then, we evaluate and compare a variety of fine-tuning methods prevalent in natural language processing, both in terms of performance on new tasks, and how well performance on pre-training tasks is retained. Our study shows that with most fine-tuning approaches, the performance on pre-training tasks deteriorates significantly. Therefore, we propose a novel method, Learning-to-Modulate (L2M), that avoids the degradation of learned skills by modulating the information flow of the frozen pre-trained model via a learnable modulation pool. Our method achieves state-of-the-art performance on the Continual-World benchmark, while retaining performance on the pre-training tasks. Finally, to aid future research in this area, we release a dataset encompassing 50 Meta-World and 16 DMControl tasks.
Semantic HELM: An Interpretable Memory for Reinforcement Learning
Jun 15, 2023Reinforcement learning agents deployed in the real world often have to cope with partially observable environments. Therefore, most agents employ memory mechanisms to approximate the state of the environment. Recently, there have been impressive success stories in mastering partially observable environments, mostly in the realm of computer games like Dota 2, StarCraft II, or MineCraft. However, none of these methods are interpretable in the sense that it is not comprehensible for humans how the agent decides which actions to take based on its inputs. Yet, human understanding is necessary in order to deploy such methods in high-stake domains like autonomous driving or medical applications. We propose a novel memory mechanism that operates on human language to illuminate the decision-making process. First, we use CLIP to associate visual inputs with language tokens. Then we feed these tokens to a pretrained language model that serves the agent as memory and provides it with a coherent and interpretable representation of the past. Our memory mechanism achieves state-of-the-art performance in environments where memorizing the past is crucial to solve tasks. Further, we present situations where our memory component excels or fails to demonstrate strengths and weaknesses of our new approach.
Addressing Parameter Choice Issues in Unsupervised Domain Adaptation by Aggregation
May 02, 2023



We study the problem of choosing algorithm hyper-parameters in unsupervised domain adaptation, i.e., with labeled data in a source domain and unlabeled data in a target domain, drawn from a different input distribution. We follow the strategy to compute several models using different hyper-parameters, and, to subsequently compute a linear aggregation of the models. While several heuristics exist that follow this strategy, methods are still missing that rely on thorough theories for bounding the target error. In this turn, we propose a method that extends weighted least squares to vector-valued functions, e.g., deep neural networks. We show that the target error of the proposed algorithm is asymptotically not worse than twice the error of the unknown optimal aggregation. We also perform a large scale empirical comparative study on several datasets, including text, images, electroencephalogram, body sensor signals and signals from mobile phones. Our method outperforms deep embedded validation (DEV) and importance weighted validation (IWV) on all datasets, setting a new state-of-the-art performance for solving parameter choice issues in unsupervised domain adaptation with theoretical error guarantees. We further study several competitive heuristics, all outperforming IWV and DEV on at least five datasets. However, our method outperforms each heuristic on at least five of seven datasets.
* Oral talk (notable-top-5%) at International Conference On Learning Representations (ICLR), 2023
Contrastive Tuning: A Little Help to Make Masked Autoencoders Forget
Apr 20, 2023



Masked Image Modeling (MIM) methods, like Masked Autoencoders (MAE), efficiently learn a rich representation of the input. However, for adapting to downstream tasks, they require a sufficient amount of labeled data since their rich features capture not only objects but also less relevant image background. In contrast, Instance Discrimination (ID) methods focus on objects. In this work, we study how to combine the efficiency and scalability of MIM with the ability of ID to perform downstream classification in the absence of large amounts of labeled data. To this end, we introduce Masked Autoencoder Contrastive Tuning (MAE-CT), a sequential approach that applies Nearest Neighbor Contrastive Learning (NNCLR) to a pre-trained MAE. MAE-CT tunes the rich features such that they form semantic clusters of objects without using any labels. Applied to large and huge Vision Transformer (ViT) models, MAE-CT matches or excels previous self-supervised methods trained on ImageNet in linear probing, k-NN and low-shot classification accuracy as well as in unsupervised clustering accuracy. Notably, similar results can be achieved without additional image augmentations. While ID methods generally rely on hand-crafted augmentations to avoid shortcut learning, we find that nearest neighbor lookup is sufficient and that this data-driven augmentation effect improves with model size. MAE-CT is compute efficient. For instance, starting from a MAE pre-trained ViT-L/16, MAE-CT increases the ImageNet 1% low-shot accuracy from 67.7% to 72.6%, linear probing accuracy from 76.0% to 80.2% and k-NN accuracy from 60.6% to 79.1% in just five hours using eight A100 GPUs.
Conformal Prediction for Time Series with Modern Hopfield Networks
Mar 22, 2023



To quantify uncertainty, conformal prediction methods are gaining continuously more interest and have already been successfully applied to various domains. However, they are difficult to apply to time series as the autocorrelative structure of time series violates basic assumptions required by conformal prediction. We propose HopCPT, a novel conformal prediction approach for time series that not only copes with temporal structures but leverages them. We show that our approach is theoretically well justified for time series where temporal dependencies are present. In experiments, we demonstrate that our new approach outperforms state-of-the-art conformal prediction methods on multiple real-world time series datasets from four different domains.
Traffic4cast at NeurIPS 2022 -- Predict Dynamics along Graph Edges from Sparse Node Data: Whole City Traffic and ETA from Stationary Vehicle Detectors
Mar 14, 2023



The global trends of urbanization and increased personal mobility force us to rethink the way we live and use urban space. The Traffic4cast competition series tackles this problem in a data-driven way, advancing the latest methods in machine learning for modeling complex spatial systems over time. In this edition, our dynamic road graph data combine information from road maps, $10^{12}$ probe data points, and stationary vehicle detectors in three cities over the span of two years. While stationary vehicle detectors are the most accurate way to capture traffic volume, they are only available in few locations. Traffic4cast 2022 explores models that have the ability to generalize loosely related temporal vertex data on just a few nodes to predict dynamic future traffic states on the edges of the entire road graph. In the core challenge, participants are invited to predict the likelihoods of three congestion classes derived from the speed levels in the GPS data for the entire road graph in three cities 15 min into the future. We only provide vehicle count data from spatially sparse stationary vehicle detectors in these three cities as model input for this task. The data are aggregated in 15 min time bins for one hour prior to the prediction time. For the extended challenge, participants are tasked to predict the average travel times on super-segments 15 min into the future - super-segments are longer sequences of road segments in the graph. The competition results provide an important advance in the prediction of complex city-wide traffic states just from publicly available sparse vehicle data and without the need for large amounts of real-time floating vehicle data.
Enhancing Activity Prediction Models in Drug Discovery with the Ability to Understand Human Language
Mar 06, 2023



Activity and property prediction models are the central workhorses in drug discovery and materials sciences, but currently they have to be trained or fine-tuned for new tasks. Without training or fine-tuning, scientific language models could be used for such low-data tasks through their announced zero- and few-shot capabilities. However, their predictive quality at activity prediction is lacking. In this work, we envision a novel type of activity prediction model that is able to adapt to new prediction tasks at inference time, via understanding textual information describing the task. To this end, we propose a new architecture with separate modules for chemical and natural language inputs, and a contrastive pre-training objective on data from large biochemical databases. In extensive experiments, we show that our method CLAMP yields improved predictive performance on few-shot learning benchmarks and zero-shot problems in drug discovery. We attribute the advances of our method to the modularized architecture and to our pre-training objective.
G-Signatures: Global Graph Propagation With Randomized Signatures
Feb 17, 2023



Graph neural networks (GNNs) have evolved into one of the most popular deep learning architectures. However, GNNs suffer from over-smoothing node information and, therefore, struggle to solve tasks where global graph properties are relevant. We introduce G-Signatures, a novel graph learning method that enables global graph propagation via randomized signatures. G-Signatures use a new graph lifting concept to embed graph structured information, which can be interpreted as path in latent space. We further introduce the idea of latent space path mapping, which allows us to repetitively traverse latent space paths, and, thus globally process information. G-Signatures excel at extracting and processing global graph properties, and effectively scale to large graph problems. Empirically, we confirm the advantages of our G-Signatures at several classification and regression tasks.
Txt2Img-MHN: Remote Sensing Image Generation from Text Using Modern Hopfield Networks
Aug 08, 2022
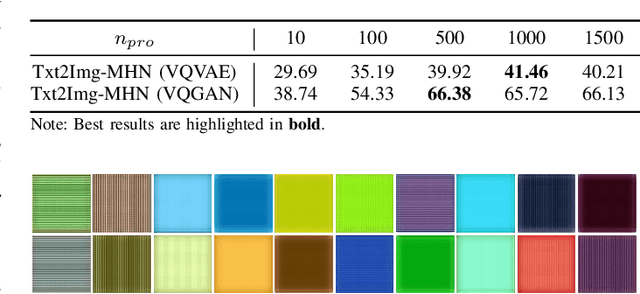
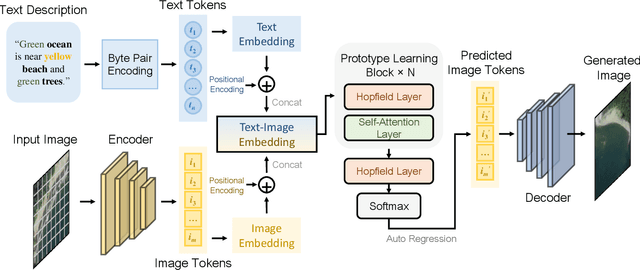
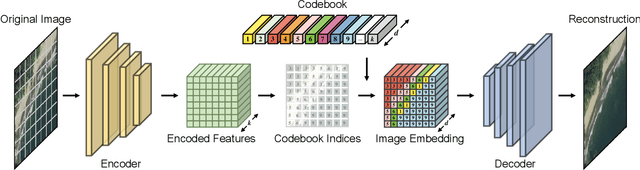
The synthesis of high-resolution remote sensing images based on text descriptions has great potential in many practical application scenarios. Although deep neural networks have achieved great success in many important remote sensing tasks, generating realistic remote sensing images from text descriptions is still very difficult. To address this challenge, we propose a novel text-to-image modern Hopfield network (Txt2Img-MHN). The main idea of Txt2Img-MHN is to conduct hierarchical prototype learning on both text and image embeddings with modern Hopfield layers. Instead of directly learning concrete but highly diverse text-image joint feature representations for different semantics, Txt2Img-MHN aims to learn the most representative prototypes from text-image embeddings, achieving a coarse-to-fine learning strategy. These learned prototypes can then be utilized to represent more complex semantics in the text-to-image generation task. To better evaluate the realism and semantic consistency of the generated images, we further conduct zero-shot classification on real remote sensing data using the classification model trained on synthesized images. Despite its simplicity, we find that the overall accuracy in the zero-shot classification may serve as a good metric to evaluate the ability to generate an image from text. Extensive experiments on the benchmark remote sensing text-image dataset demonstrate that the proposed Txt2Img-MHN can generate more realistic remote sensing images than existing methods. Code and pre-trained models are available online (https://github.com/YonghaoXu/Txt2Img-MHN).
Reactive Exploration to Cope with Non-Stationarity in Lifelong Reinforcement Learning
Jul 12, 2022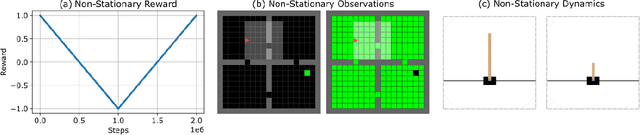
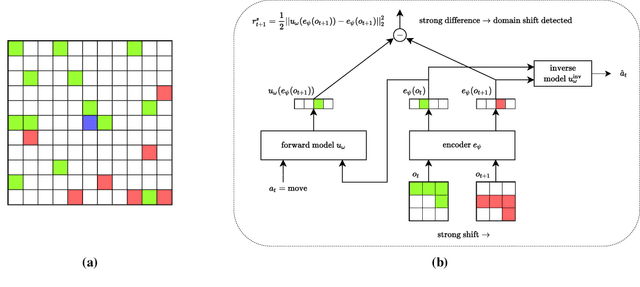
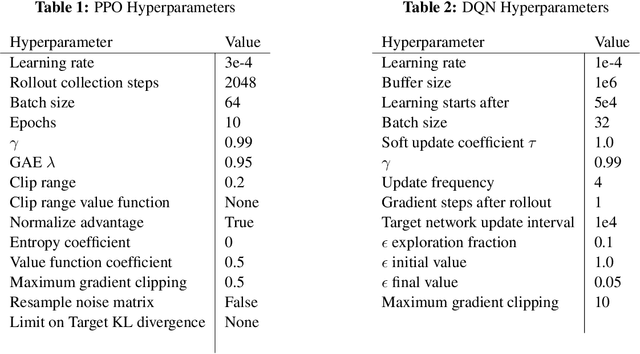
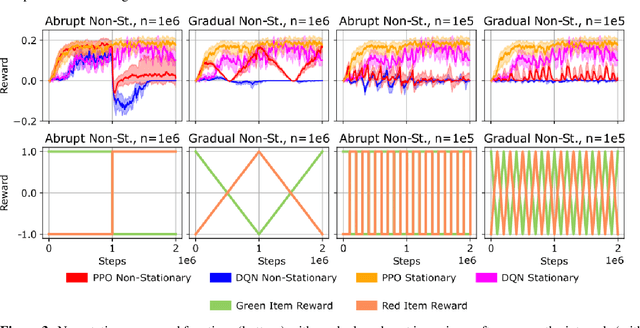
In lifelong learning, an agent learns throughout its entire life without resets, in a constantly changing environment, as we humans do. Consequently, lifelong learning comes with a plethora of research problems such as continual domain shifts, which result in non-stationary rewards and environment dynamics. These non-stationarities are difficult to detect and cope with due to their continuous nature. Therefore, exploration strategies and learning methods are required that are capable of tracking the steady domain shifts, and adapting to them. We propose Reactive Exploration to track and react to continual domain shifts in lifelong reinforcement learning, and to update the policy correspondingly. To this end, we conduct experiments in order to investigate different exploration strategies. We empirically show that representatives of the policy-gradient family are better suited for lifelong learning, as they adapt more quickly to distribution shifts than Q-learning. Thereby, policy-gradient methods profit the most from Reactive Exploration and show good results in lifelong learning with continual domain shifts. Our code is available at: https://github.com/ml-jku/reactive-exploration.