 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Monocular Depth in Dynamic Scenes via Instance-Aware Projection Consistency
Feb 04, 2021

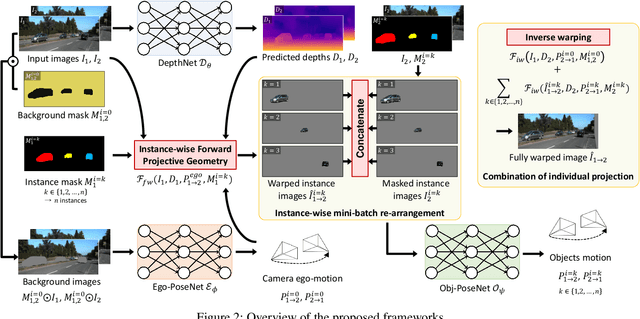
We present an end-to-end joint training framework that explicitly models 6-DoF motion of multiple dynamic objects, ego-motion and depth in a monocular camera setup without supervision. Our technical contributions are three-fold. First, we highlight the fundamental difference between inverse and forward projection while modeling the individual motion of each rigid object, and propose a geometrically correct projection pipeline using a neural forward projection module. Second, we design a unified instance-aware photometric and geometric consistency loss that holistically imposes self-supervisory signals for every background and object region. Lastly, we introduce a general-purpose auto-annotation scheme using any off-the-shelf instance segmentation and optical flow models to produce video instance segmentation maps that will be utilized as input to our training pipeline. These proposed elements are validated in a detailed ablation study. Through extensive experiments conducted on the KITTI and Cityscapes dataset, our framework is shown to outperform the state-of-the-art depth and motion estimation methods. Our code, dataset, and models are available at https://github.com/SeokjuLee/Insta-DM .
ResNet or DenseNet? Introducing Dense Shortcuts to ResNet
Oct 23, 2020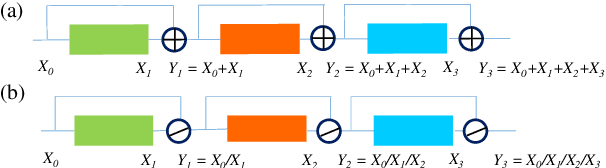

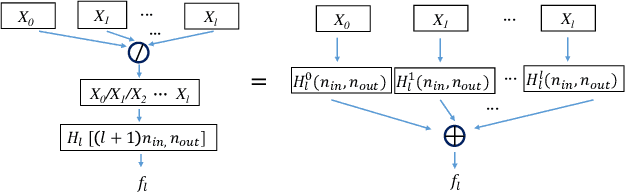

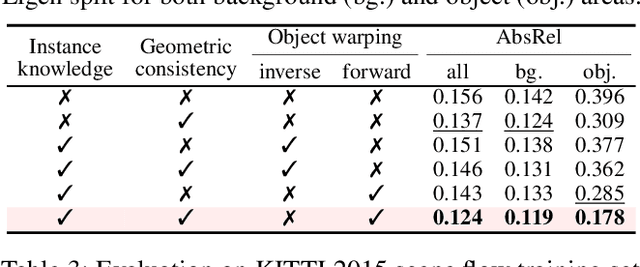
ResNet or DenseNet? Nowadays, most deep learning based approaches are implemented with seminal backbone networks, among them the two arguably most famous ones are ResNet and DenseNet. Despite their competitive performance and overwhelming popularity, inherent drawbacks exist for both of them. For ResNet, the identity shortcut that stabilizes training also limits its representation capacity, while DenseNet has a higher capacity with multi-layer feature concatenation. However, the dense concatenation causes a new problem of requiring high GPU memory and more training time. Partially due to this, it is not a trivial choice between ResNet and DenseNet. This paper provides a unified perspective of dense summation to analyze them, which facilitates a better understanding of their core difference. We further propose dense weighted normalized shortcuts as a solution to the dilemma between them. Our proposed dense shortcut inherits the design philosophy of simple design in ResNet and DenseNet. On several benchmark datasets, the experimental results show that the proposed DSNet achieves significantly better results than ResNet, and achieves comparable performance as DenseNet but requiring fewer computation resources.
Unsupervised Intra-domain Adaptation for Semantic Segmentation through Self-Supervision
Apr 20, 2020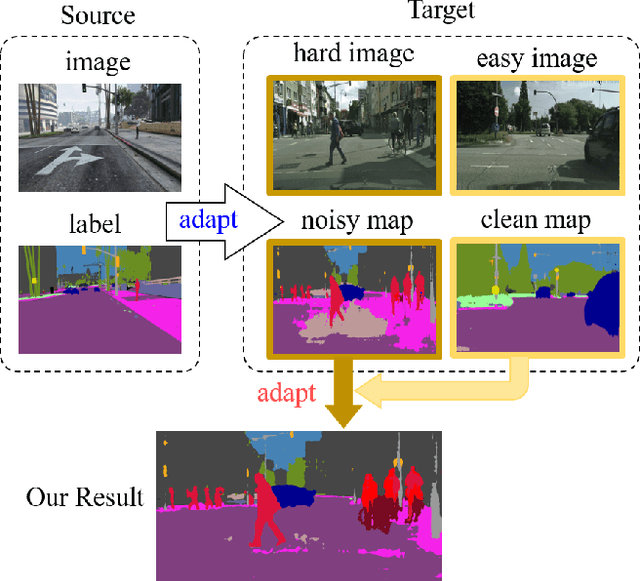
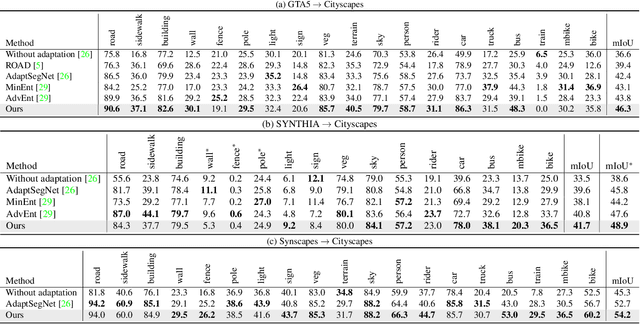
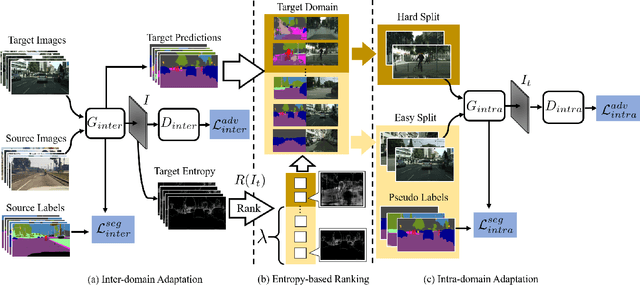

Convolutional neural network-based approaches have achieved remarkable progress in semantic segmentation. However, these approaches heavily rely on annotated data which are labor intensive. To cope with this limitation, automatically annotated data generated from graphic engines are used to train segmentation models. However, the models trained from synthetic data are difficult to transfer to real images. To tackle this issue, previous works have considered directly adapting models from the source data to the unlabeled target data (to reduce the inter-domain gap). Nonetheless, these techniques do not consider the large distribution gap among the target data itself (intra-domain gap). In this work, we propose a two-step self-supervised domain adaptation approach to minimize the inter-domain and intra-domain gap together. First, we conduct the inter-domain adaptation of the model; from this adaptation, we separate the target domain into an easy and hard split using an entropy-based ranking function. Finally, to decrease the intra-domain gap, we propose to employ a self-supervised adaptation technique from the easy to the hard split. Experimental results on numerous benchmark datasets highlight the effectiveness of our method against existing state-of-the-art approaches. The source code is available at https://github.com/feipan664/IntraDA.git.
Instance-wise Depth and Motion Learning from Monocular Videos
Dec 19, 2019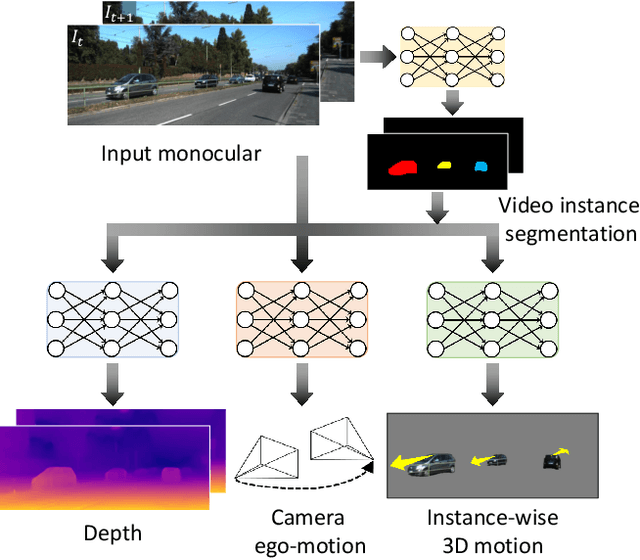
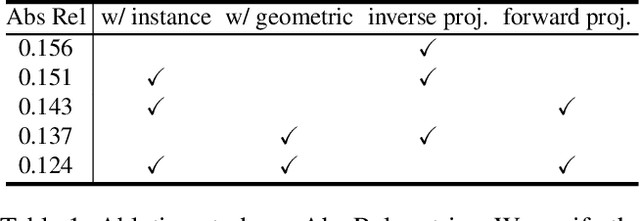
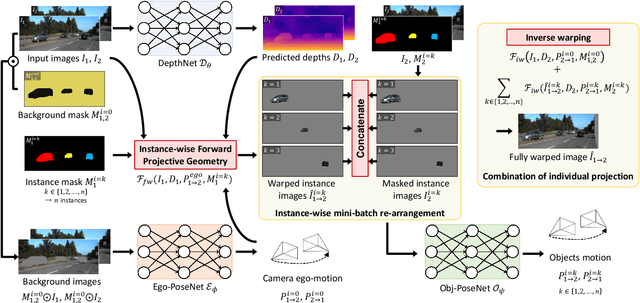
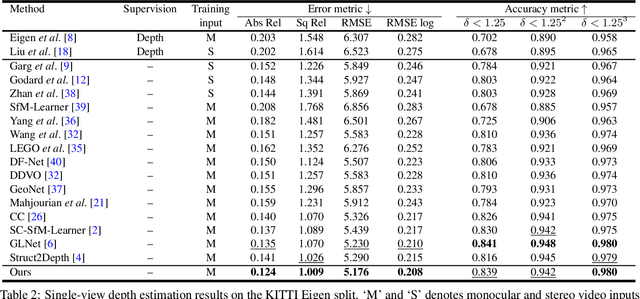
We present an end-to-end joint training framework that explicitly models 6-DoF motion of multiple dynamic objects, ego-motion and depth in a monocular camera setup without supervision. The only annotation used in our pipeline is a video instance segmentation map that can be predicted by our new auto-annotation scheme. Our technical contributions are three-fold. First, we propose a differentiable forward rigid projection module that plays a key role in our instance-wise depth and motion learning. Second, we design an instance-wise photometric and geometric consistency loss that effectively decomposes background and moving object regions. Lastly, we introduce an instance-wise mini-batch re-arrangement scheme that does not require additional iterations in training. These proposed elements are validated in a detailed ablation study. Through extensive experiments conducted on the KITTI dataset, our framework is shown to outperform the state-of-the-art depth and motion estimation methods.
Learning Residual Flow as Dynamic Motion from Stereo Videos
Sep 16, 2019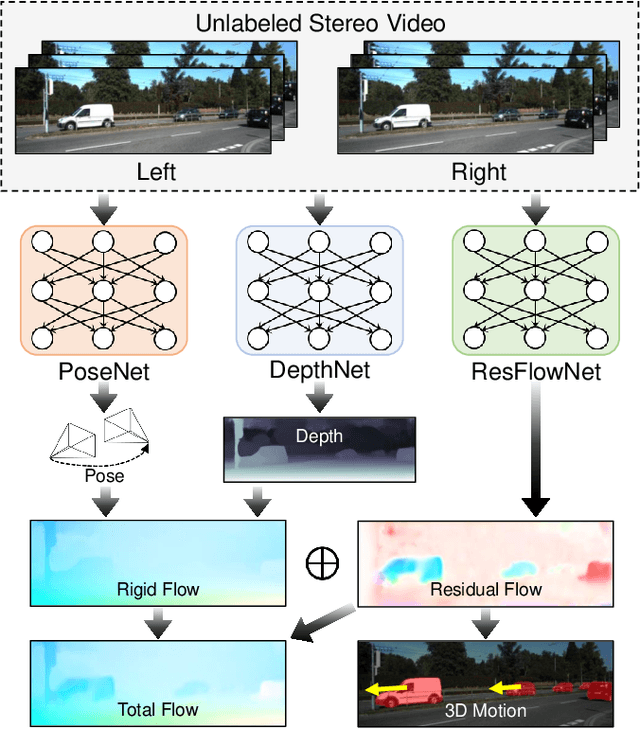
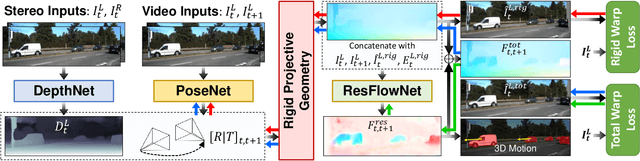
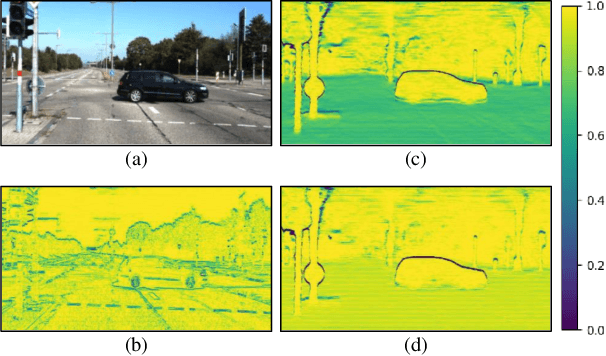
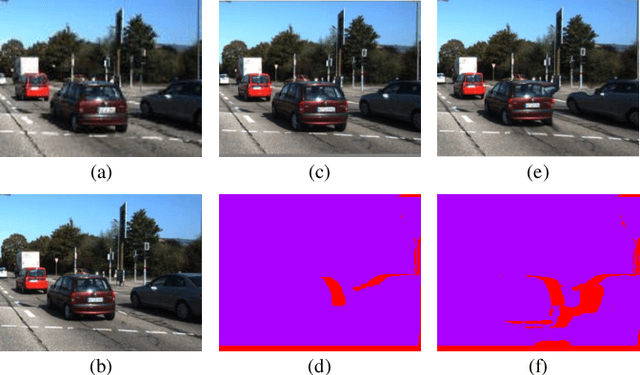
We present a method for decomposing the 3D scene flow observed from a moving stereo rig into stationary scene elements and dynamic object motion. Our unsupervised learning framework jointly reasons about the camera motion, optical flow, and 3D motion of moving objects. Three cooperating networks predict stereo matching, camera motion, and residual flow, which represents the flow component due to object motion and not from camera motion. Based on rigid projective geometry, the estimated stereo depth is used to guide the camera motion estimation, and the depth and camera motion are used to guide the residual flow estimation. We also explicitly estimate the 3D scene flow of dynamic objects based on the residual flow and scene depth. Experiments on the KITTI dataset demonstrate the effectiveness of our approach and show that our method outperforms other state-of-the-art algorithms on the optical flow and visual odometry tasks.
Visuomotor Understanding for Representation Learning of Driving Scenes
Sep 16, 2019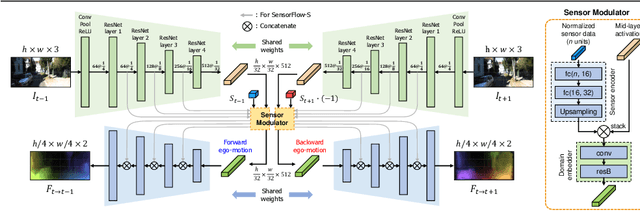
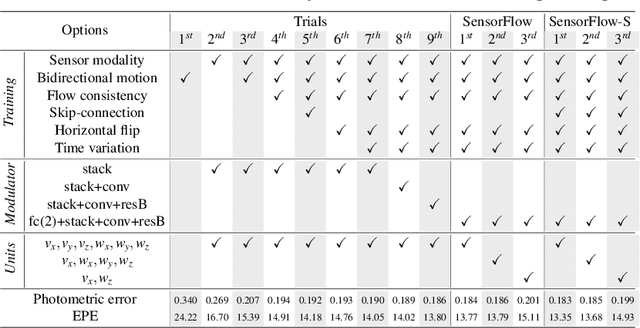
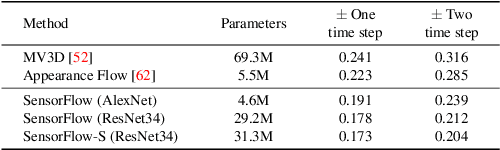
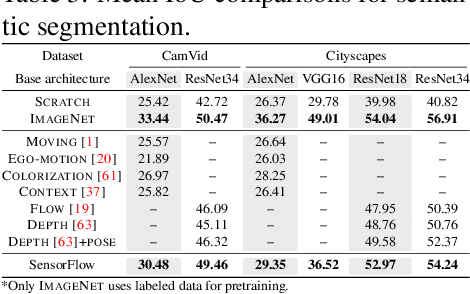
Dashboard cameras capture a tremendous amount of driving scene video each day. These videos are purposefully coupled with vehicle sensing data, such as from the speedometer and inertial sensors, providing an additional sensing modality for free. In this work, we leverage the large-scale unlabeled yet naturally paired data for visual representation learning in the driving scenario. A representation is learned in an end-to-end self-supervised framework for predicting dense optical flow from a single frame with paired sensing data. We postulate that success on this task requires the network to learn semantic and geometric knowledge in the ego-centric view. For example, forecasting a future view to be seen from a moving vehicle requires an understanding of scene depth, scale, and movement of objects. We demonstrate that our learned representation can benefit other tasks that require detailed scene understanding and outperforms competing unsupervised representations on semantic segmentation.
Variational Prototyping-Encoder: One-Shot Learning with Prototypical Images
Apr 17, 2019

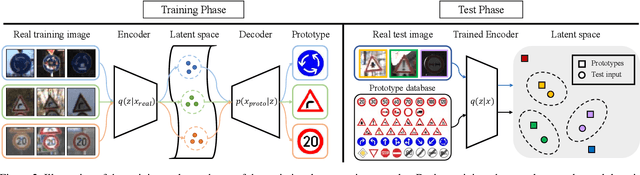
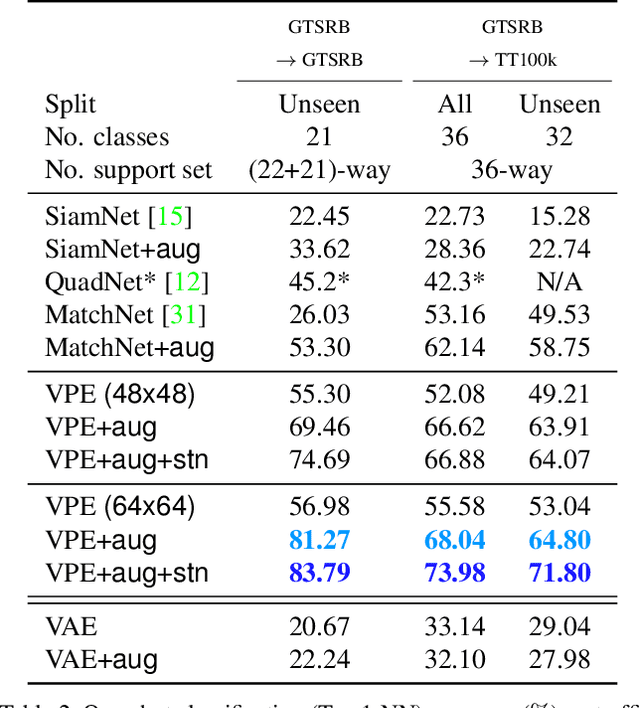
In daily life, graphic symbols, such as traffic signs and brand logos, are ubiquitously utilized around us due to its intuitive expression beyond language boundary. We tackle an open-set graphic symbol recognition problem by one-shot classification with prototypical images as a single training example for each novel class. We take an approach to learn a generalizable embedding space for novel tasks. We propose a new approach called variational prototyping-encoder (VPE) that learns the image translation task from real-world input images to their corresponding prototypical images as a meta-task. As a result, VPE learns image similarity as well as prototypical concepts which differs from widely used metric learning based approaches. Our experiments with diverse datasets demonstrate that the proposed VPE performs favorably against competing metric learning based one-shot methods. Also, our qualitative analyses show that our meta-task induces an effective embedding space suitable for unseen data representation.
Co-domain Embedding using Deep Quadruplet Networks for Unseen Traffic Sign Recognition
Dec 05, 2017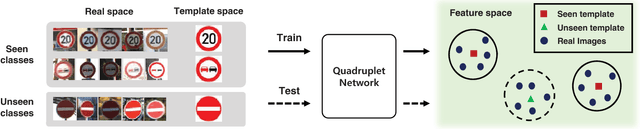
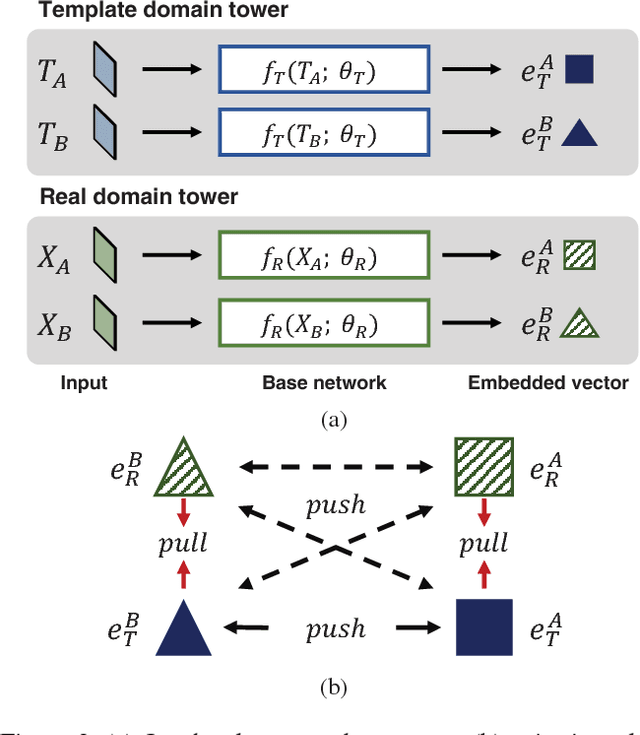
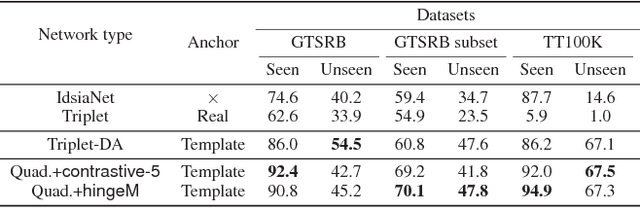
Recent advances in visual recognition show overarching success by virtue of large amounts of supervised data. However,the acquisition of a large supervised dataset is often challenging. This is also true for intelligent transportation applications, i.e., traffic sign recognition. For example, a model trained with data of one country may not be easily generalized to another country without much data. We propose a novel feature embedding scheme for unseen class classification when the representative class template is given. Traffic signs, unlike other objects, have official images. We perform co-domain embedding using a quadruple relationship from real and synthetic domains. Our quadruplet network fully utilizes the explicit pairwise similarity relationships among samples from different domains. We validate our method on three datasets with two experiments involving one-shot classification and feature generalization. The results show that the proposed method outperforms competing approaches on both seen and unseen classes.
VPGNet: Vanishing Point Guided Network for Lane and Road Marking Detection and Recognition
Oct 17, 2017
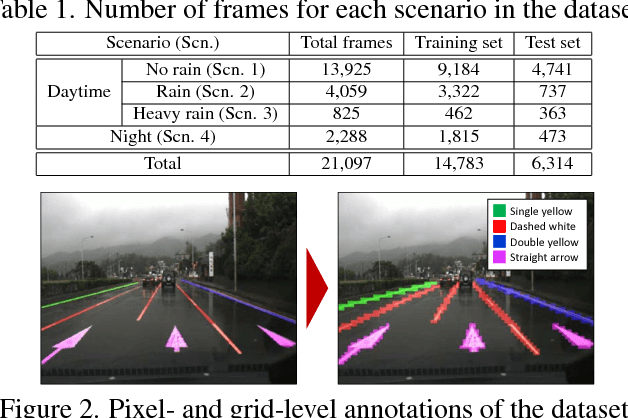
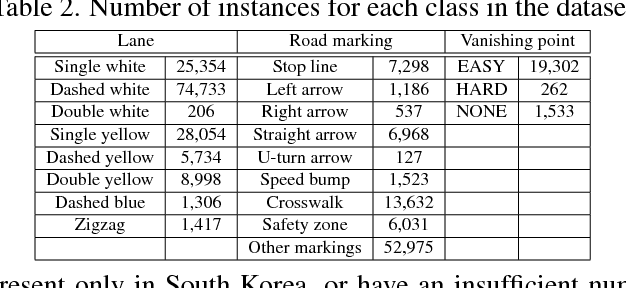
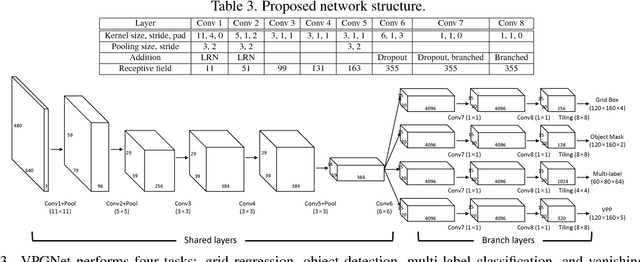
In this paper, we propose a unified end-to-end trainable multi-task network that jointly handles lane and road marking detection and recognition that is guided by a vanishing point under adverse weather conditions. We tackle rainy and low illumination conditions, which have not been extensively studied until now due to clear challenges. For example, images taken under rainy days are subject to low illumination, while wet roads cause light reflection and distort the appearance of lane and road markings. At night, color distortion occurs under limited illumination. As a result, no benchmark dataset exists and only a few developed algorithms work under poor weather conditions. To address this shortcoming, we build up a lane and road marking benchmark which consists of about 20,000 images with 17 lane and road marking classes under four different scenarios: no rain, rain, heavy rain, and night. We train and evaluate several versions of the proposed multi-task network and validate the importance of each task. The resulting approach, VPGNet, can detect and classify lanes and road markings, and predict a vanishing point with a single forward pass. Experimental results show that our approach achieves high accuracy and robustness under various conditions in real-time (20 fps). The benchmark and the VPGNet model will be publicly available.
Pixel-Level Matching for Video Object Segmentation using Convolutional Neural Networks
Aug 17, 2017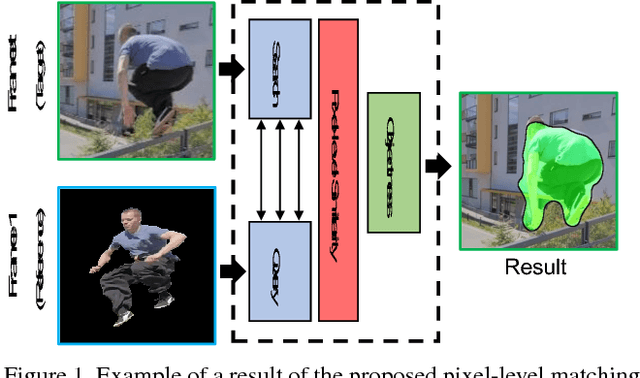
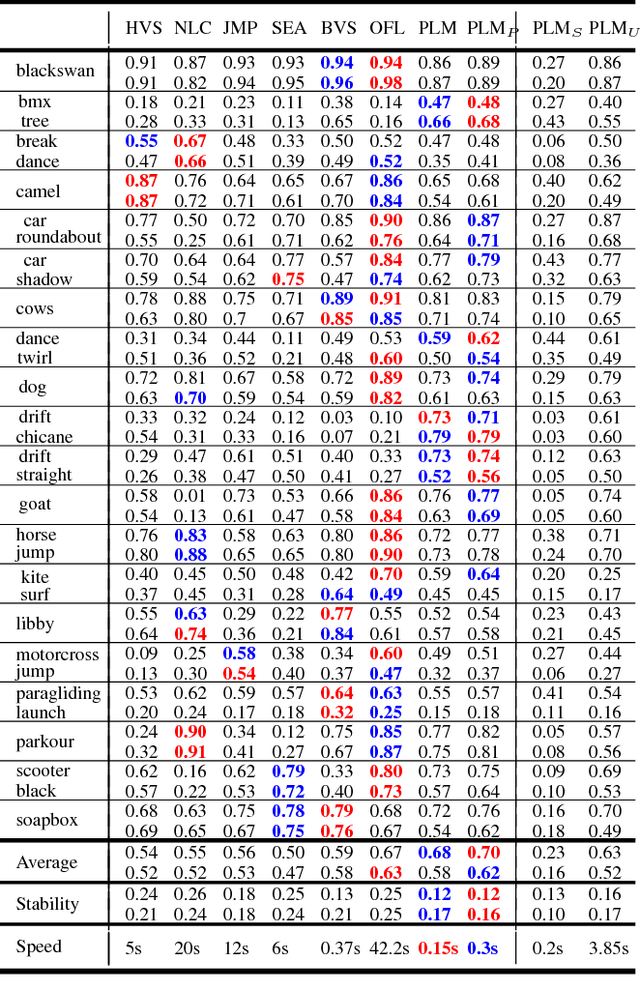
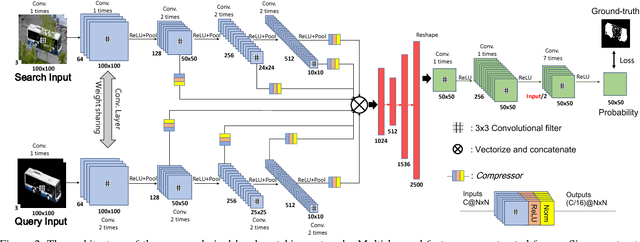
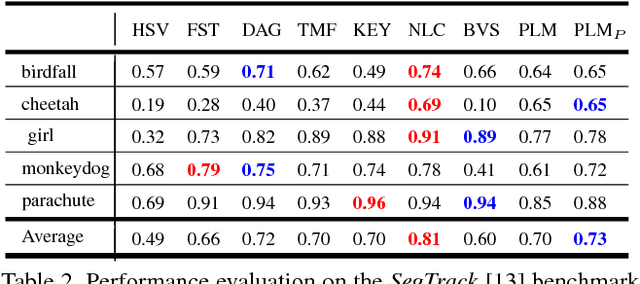
We propose a novel video object segmentation algorithm based on pixel-level matching using Convolutional Neural Networks (CNN). Our network aims to distinguish the target area from the background on the basis of the pixel-level similarity between two object units. The proposed network represents a target object using features from different depth layers in order to take advantage of both the spatial details and the category-level semantic information. Furthermore, we propose a feature compression technique that drastically reduces the memory requirements while maintaining the capability of feature representation. Two-stage training (pre-training and fine-tuning) allows our network to handle any target object regardless of its category (even if the object's type does not belong to the pre-training data) or of variations in its appearance through a video sequence. Experiments on large datasets demonstrate the effectiveness of our model - against related methods - in terms of accuracy, speed, and stability. Finally, we introduce the transferability of our network to different domains, such as the infrared data domain.