 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinite Expression Method for Solving High-Dimensional Partial Differential Equations
Jun 21, 2022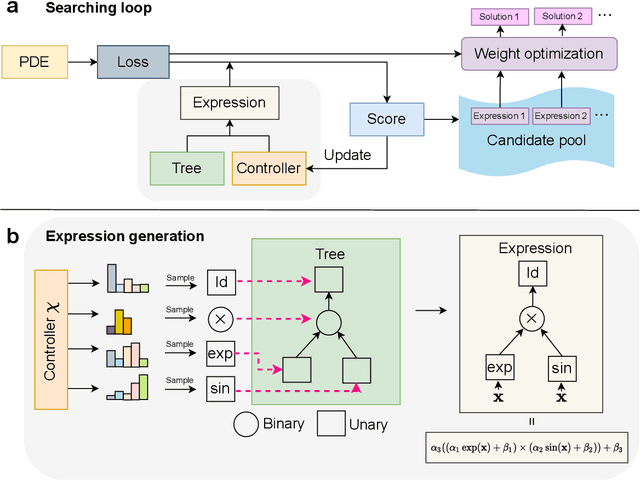

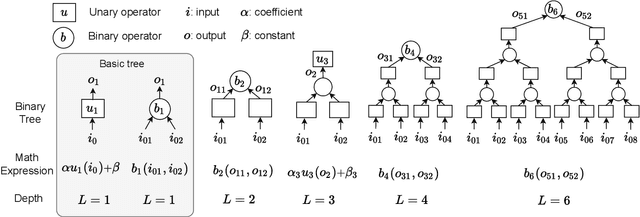
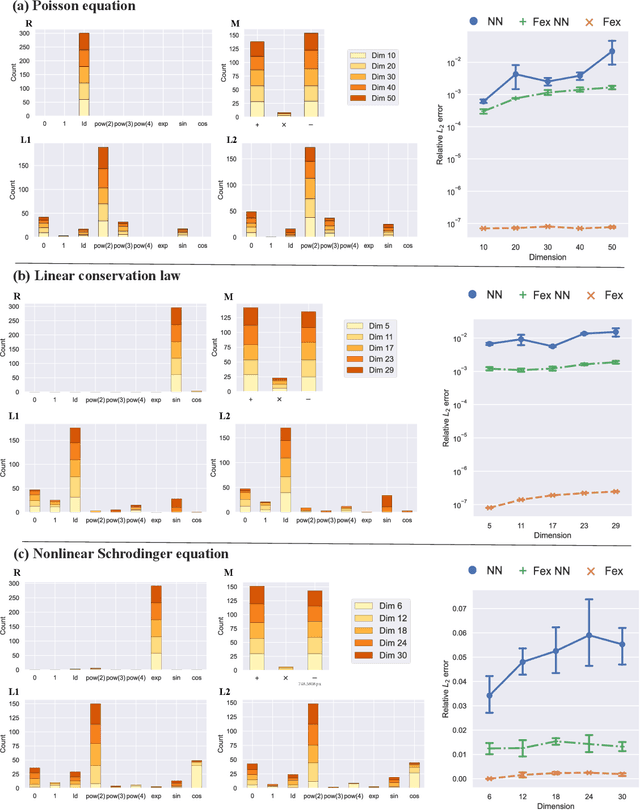
Designing efficient and accurate numerical solvers for high-dimensional partial differential equations (PDEs) remains a challenging and important topic in computational science and engineering, mainly due to the ``curse of dimensionality" in designing numerical schemes that scale in dimension. This paper introduces a new methodology that seeks an approximate PDE solution in the space of functions with finitely many analytic expressions and, hence, this methodology is named the finite expression method (FEX). It is proved in approximation theory that FEX can avoid the curse of dimensionality. As a proof of concept, a deep reinforcement learning method is proposed to implement FEX for various high-dimensional PDEs in different dimensions, achieving high and even machine accuracy with a memory complexity polynomial in dimension and an amenable time complexity. An approximate solution with finite analytic expressions also provides interpretable insights into the ground truth PDE solution, which can further help to advance the understanding of physical systems and design postprocessing techniques for a refined solution.
Stationary Density Estimation of Itô Diffusions Using Deep Learning
Sep 09, 2021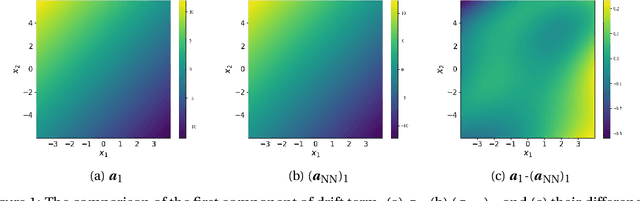
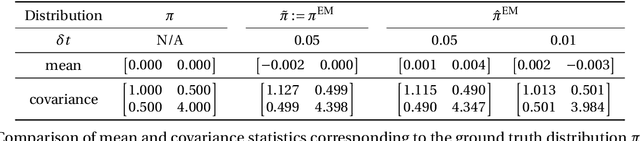
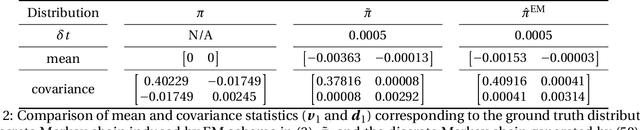
In this paper, we consider the density estimation problem associated with the stationary measure of ergodic It\^o diffusions from a discrete-time series that approximate the solutions of the stochastic differential equations. To take an advantage of the characterization of density function through the stationary solution of a parabolic-type Fokker-Planck PDE, we proceed as follows. First, we employ deep neural networks to approximate the drift and diffusion terms of the SDE by solving appropriate supervised learning tasks. Subsequently, we solve a steady-state Fokker-Plank equation associated with the estimated drift and diffusion coefficients with a neural-network-based least-squares method. We establish the convergence of the proposed scheme under appropriate mathematical assumptions, accounting for the generalization errors induced by regressing the drift and diffusion coefficients, and the PDE solvers. This theoretical study relies on a recent perturbation theory of Markov chain result that shows a linear dependence of the density estimation to the error in estimating the drift term, and generalization error results of nonparametric regression and of PDE regression solution obtained with neural-network models. The effectiveness of this method is reflected by numerical simulations of a two-dimensional Student's t distribution and a 20-dimensional Langevin dynamics.
AlterSGD: Finding Flat Minima for Continual Learning by Alternative Training
Jul 13, 2021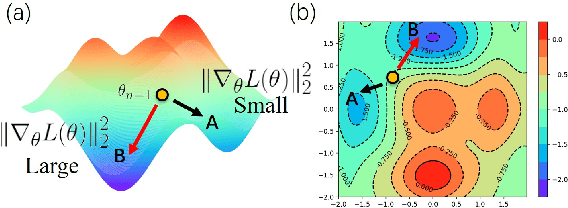
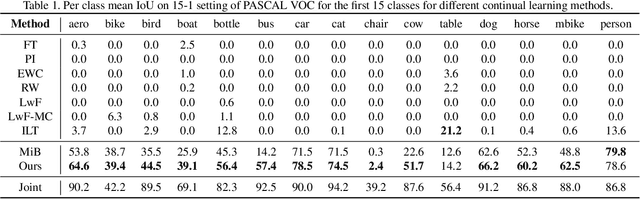
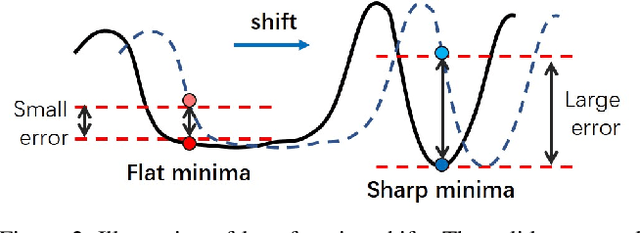
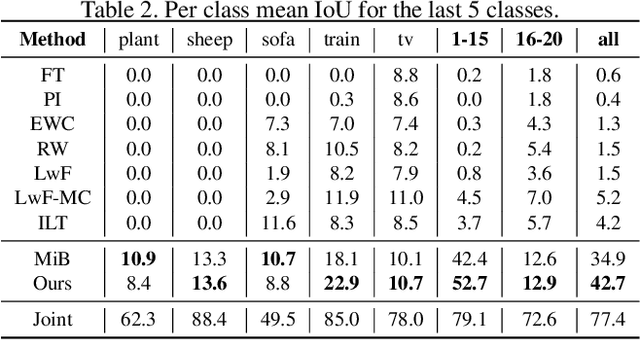
Deep neural networks suffer from catastrophic forgetting when learning multiple knowledge sequentially, and a growing number of approaches have been proposed to mitigate this problem. Some of these methods achieved considerable performance by associating the flat local minima with forgetting mitigation in continual learning. However, they inevitably need (1) tedious hyperparameters tuning, and (2) additional computational cost. To alleviate these problems, in this paper, we propose a simple yet effective optimization method, called AlterSGD, to search for a flat minima in the loss landscape. In AlterSGD, we conduct gradient descent and ascent alternatively when the network tends to converge at each session of learning new knowledge. Moreover, we theoretically prove that such a strategy can encourage the optimization to converge to a flat minima. We verify AlterSGD on continual learning benchmark for semantic segmentation and the empirical results show that we can significantly mitigate the forgetting and outperform the state-of-the-art methods with a large margin under challenging continual learning protocols.
Blending Pruning Criteria for Convolutional Neural Networks
Jul 11, 2021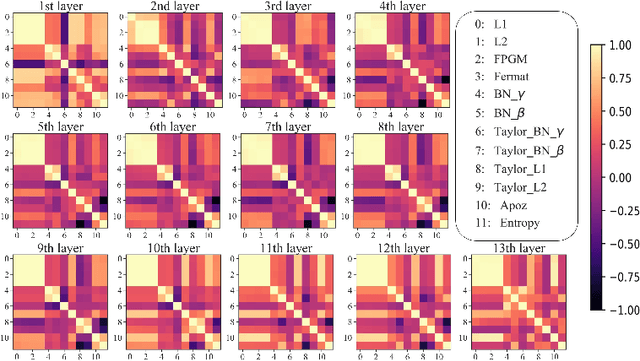
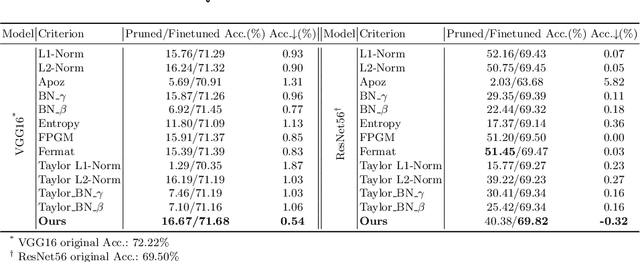
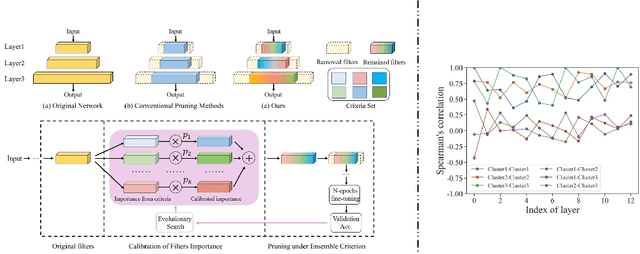
The advancement of convolutional neural networks (CNNs) on various vision applications has attracted lots of attention. Yet the majority of CNNs are unable to satisfy the strict requirement for real-world deployment. To overcome this, the recent popular network pruning is an effective method to reduce the redundancy of the models. However, the ranking of filters according to their "importance" on different pruning criteria may be inconsistent. One filter could be important according to a certain criterion, while it is unnecessary according to another one, which indicates that each criterion is only a partial view of the comprehensive "importance". From this motivation, we propose a novel framework to integrate the existing filter pruning criteria by exploring the criteria diversity. The proposed framework contains two stages: Criteria Clustering and Filters Importance Calibration. First, we condense the pruning criteria via layerwise clustering based on the rank of "importance" score. Second, within each cluster, we propose a calibration factor to adjust their significance for each selected blending candidates and search for the optimal blending criterion via Evolutionary Algorithm. Quantitative results on the CIFAR-100 and ImageNet benchmarks show that our framework outperforms the state-of-the-art baselines, regrading to the compact model performance after pruning.
Solving PDEs on Unknown Manifolds with Machine Learning
Jun 12, 2021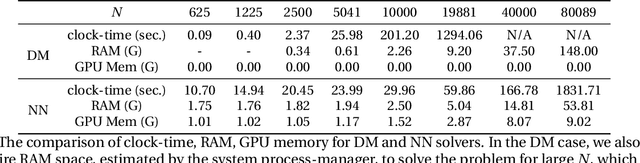
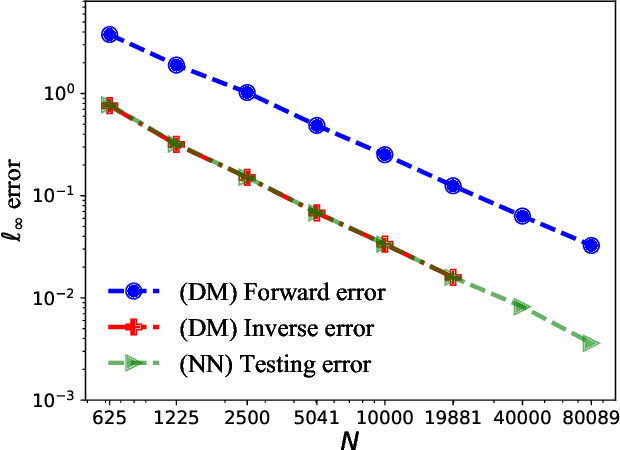

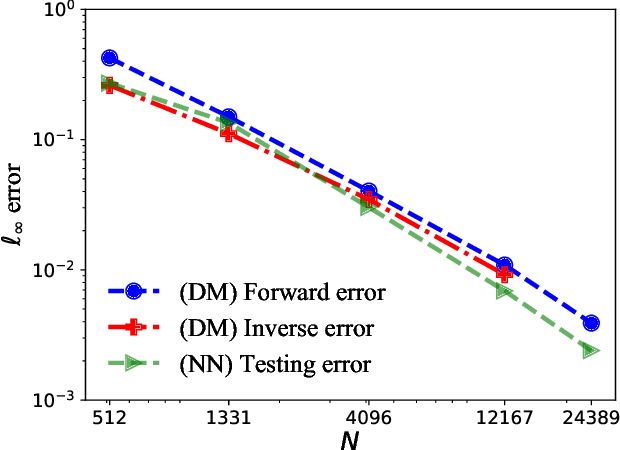
This paper proposes a mesh-free computational framework and machine learning theory for solving elliptic PDEs on unknown manifolds, identified with point clouds, based on diffusion maps (DM) and deep learning. The PDE solver is formulated as a supervised learning task to solve a least-squares regression problem that imposes an algebraic equation approximating a PDE (and boundary conditions if applicable). This algebraic equation involves a graph-Laplacian type matrix obtained via DM asymptotic expansion, which is a consistent estimator of second-order elliptic differential operators. The resulting numerical method is to solve a highly non-convex empirical risk minimization problem subjected to a solution from a hypothesis space of neural-network type functions. In a well-posed elliptic PDE setting, when the hypothesis space consists of feedforward neural networks with either infinite width or depth, we show that the global minimizer of the empirical loss function is a consistent solution in the limit of large training data. When the hypothesis space is a two-layer neural network, we show that for a sufficiently large width, the gradient descent method can identify a global minimizer of the empirical loss function. Supporting numerical examples demonstrate the convergence of the solutions and the effectiveness of the proposed solver in avoiding numerical issues that hampers the traditional approach when a large data set becomes available, e.g., large matrix inversion.
Reproducing Activation Function for Deep Learning
Jan 13, 2021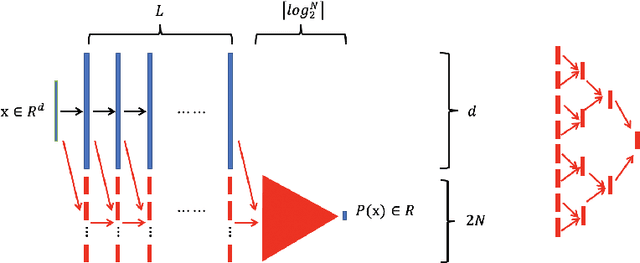
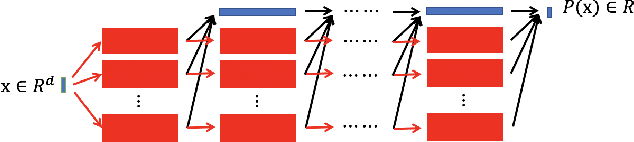

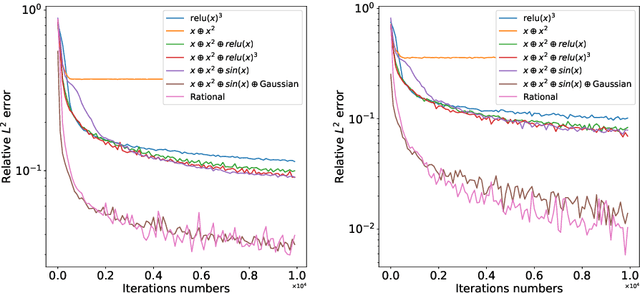
In this paper, we propose the reproducing activation function to improve deep learning accuracy for various applications ranging from computer vision problems to scientific computing problems. The idea of reproducing activation functions is to employ several basic functions and their learnable linear combination to construct neuron-wise data-driven activation functions for each neuron. Armed with such activation functions, deep neural networks can reproduce traditional approximation tools and, therefore, approximate target functions with a smaller number of parameters than traditional neural networks. In terms of training dynamics of deep learning, reproducing activation functions can generate neural tangent kernels with a better condition number than traditional activation functions lessening the spectral bias of deep learning. As demonstrated by extensive numerical tests, the proposed activation function can facilitate the convergence of deep learning optimization for a solution with higher accuracy than existing deep learning solvers for audio/image/video reconstruction, PDEs, and eigenvalue problems.
Quantifying spatial homogeneity of urban road networks via graph neural networks
Jan 01, 2021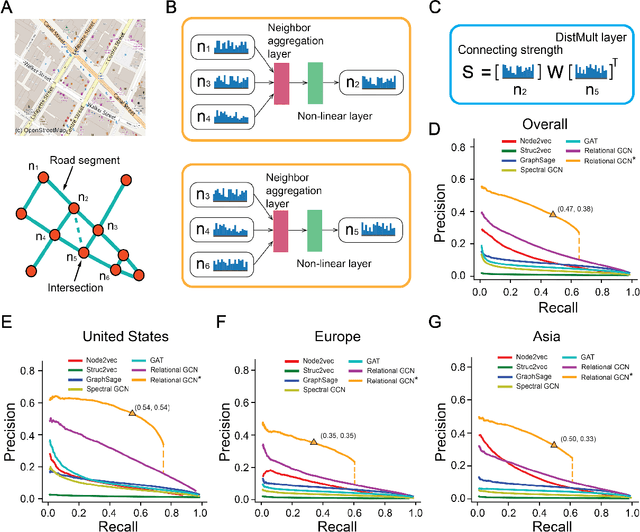
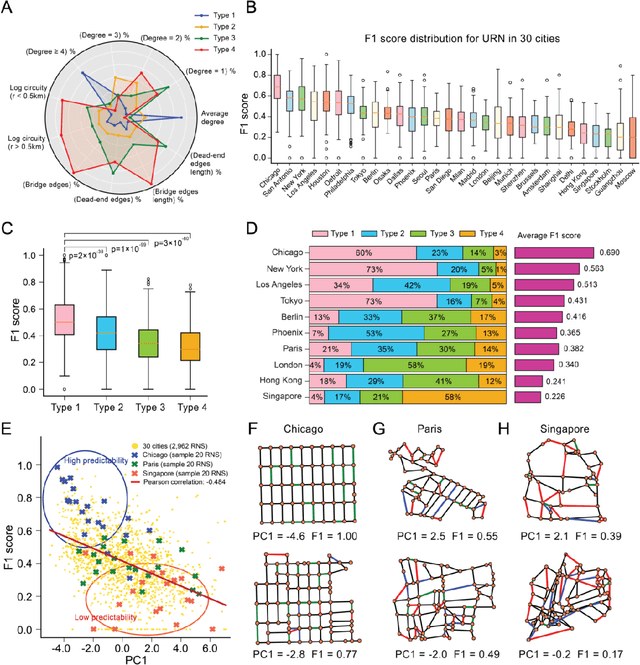
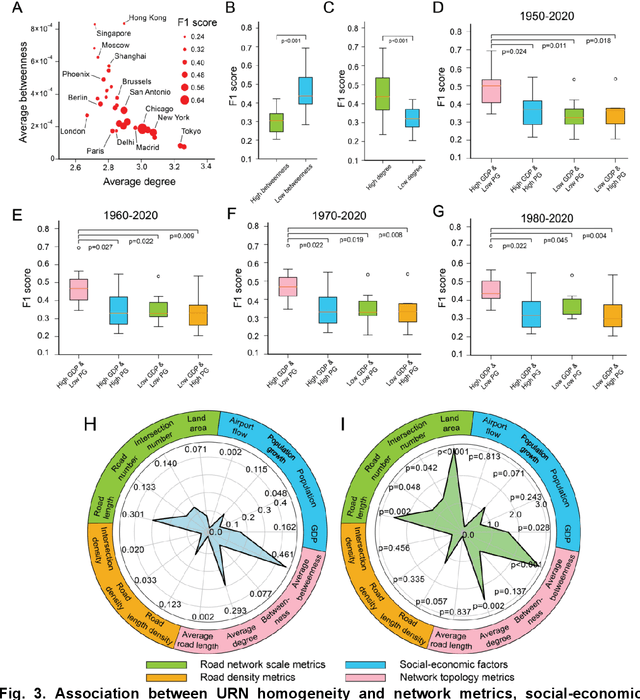
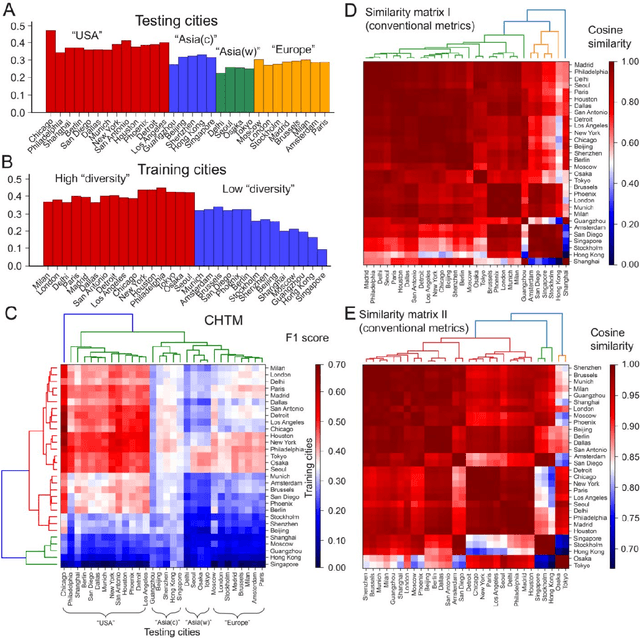
The spatial homogeneity of an urban road network (URN) measures whether each distinct component is analogous to the whole network and can serve as a quantitative manner bridging network structure and dynamics. However, given the complexity of cities, it is challenging to quantify spatial homogeneity simply based on conventional network statistics. In this work, we use Graph Neural Networks to model the 11,790 URN samples across 30 cities worldwide and use its predictability to define the spatial homogeneity. The proposed measurement can be viewed as a non-linear integration of multiple geometric properties, such as degree, betweenness, road network type, and a strong indicator of mixed socio-economic events, such as GDP and population growth. City clusters derived from transferring spatial homogeneity can be interpreted well by continental urbanization histories. We expect this novel metric supports various subsequent tasks in transportation, urban planning, and geography.
Efficient Attention Network: Accelerate Attention by Searching Where to Plug
Nov 28, 2020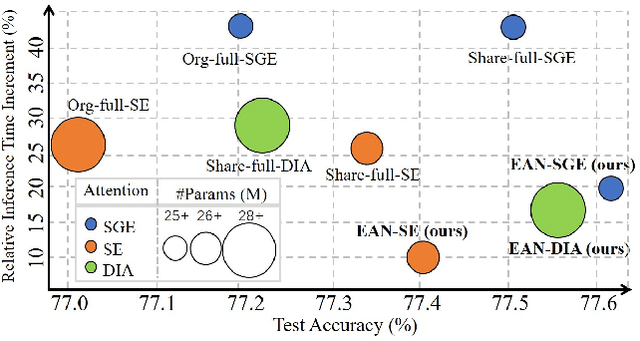
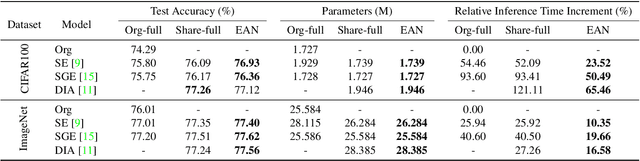
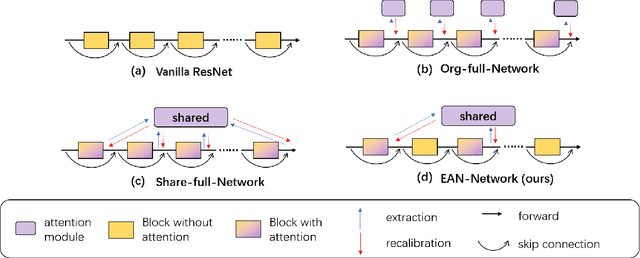
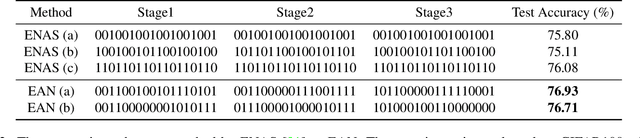
Recently, many plug-and-play self-attention modules are proposed to enhance the model generalization by exploiting the internal information of deep convolutional neural networks (CNNs). Previous works lay an emphasis on the design of attention module for specific functionality, e.g., light-weighted or task-oriented attention. However, they ignore the importance of where to plug in the attention module since they connect the modules individually with each block of the entire CNN backbone for granted, leading to incremental computational cost and number of parameters with the growth of network depth. Thus, we propose a framework called Efficient Attention Network (EAN) to improve the efficiency for the existing attention modules. In EAN, we leverage the sharing mechanism (Huang et al. 2020) to share the attention module within the backbone and search where to connect the shared attention module via reinforcement learning. Finally, we obtain the attention network with sparse connections between the backbone and modules, while (1) maintaining accuracy (2) reducing extra parameter increment and (3) accelerating inference. Extensive experiments on widely-used benchmarks and popular attention networks show the effectiveness of EAN. Furthermore, we empirically illustrate that our EAN has the capacity of transferring to other tasks and capturing the informative features. The code is available at https://github.com/gbup-group/EAN-efficient-attention-network
Machine Learning for Prediction with Missing Dynamics
Oct 13, 2019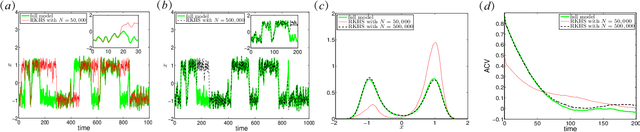

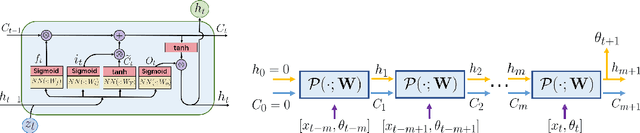
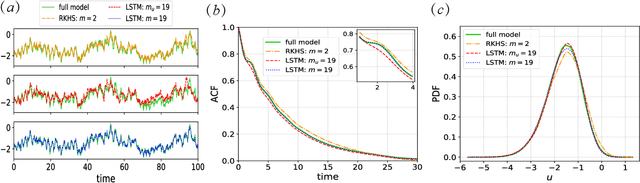
This article presents a general framework for recovering missing dynamical systems using available data and machine learning techniques. The proposed framework reformulates the prediction problem as a supervised learning problem to approximate a map that takes the memories of the resolved and identifiable unresolved variables to the missing components in the resolved dynamics. We demonstrate the effectiveness of the proposed framework with a theoretical guarantee of a path-wise convergence of the resolved variables up to finite time and numerical tests on prototypical models in various scientific domains. These include the 57-mode barotropic stress models with multiscale interactions that mimic the blocked and unblocked patterns observed in the atmosphere, the nonlinear Schr\"{o}dinger equation which found many applications in physics such as optics and Bose-Einstein-Condense, the Kuramoto-Sivashinsky equation which spatiotemporal chaotic pattern formation models trapped ion mode in plasma and phase dynamics in reaction-diffusion systems. While many machine learning techniques can be used to validate the proposed framework, we found that recurrent neural networks outperform kernel regression methods in terms of recovering the trajectory of the resolved components and the equilibrium one-point and two-point statistics. This superb performance suggests that recurrent neural networks are an effective tool for recovering the missing dynamics that involves approximation of high-dimensional functions.
Instance Enhancement Batch Normalization: an Adaptive Regulator of Batch Noise
Aug 12, 2019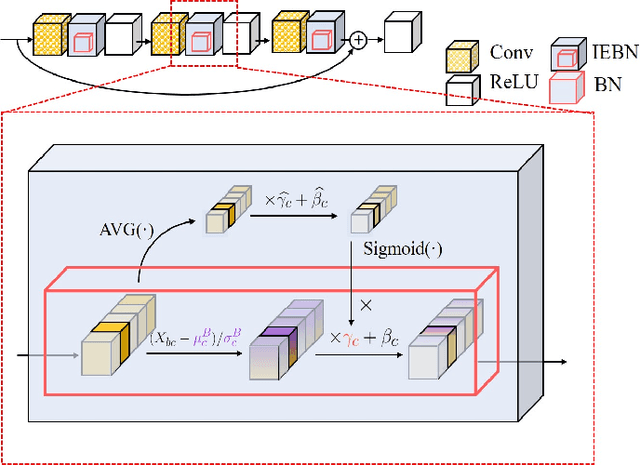
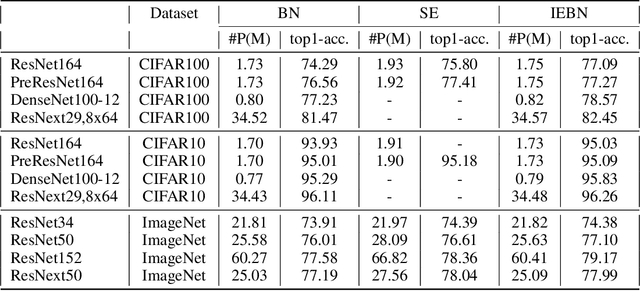

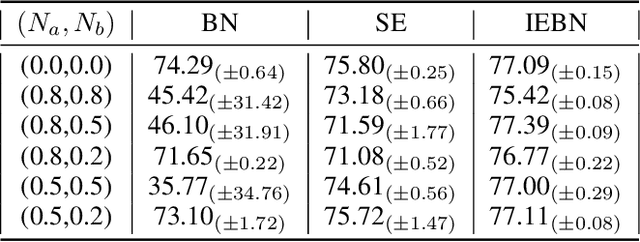
Batch Normalization (BN) (Ioffe and Szegedy 2015) normalizes the features of an input image via statistics of a batch of images and this batch information is considered as batch noise that will be brought to the features of an instance by BN. We offer a point of view that self-attention mechanism can help regulate the batch noise by enhancing instance-specific information. Based on this view, we propose combining BN with a self-attention mechanism to adjust the batch noise and give an attention-based version of BN called Instance Enhancement Batch Normalization (IEBN) which recalibrates channel information by a simple linear transformation. IEBN outperforms BN with a light parameter increment in various visual tasks universally for different network structures and benchmark data sets. Besides, even if under the attack of synthetic noise, IEBN can still stabilize network training with good generalization. The code of IEBN is available at https://github.com/gbup-group/IEBN