 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIANet: Dense-and-Implicit Attention Network
Paper and Code
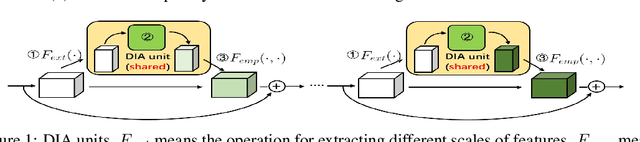

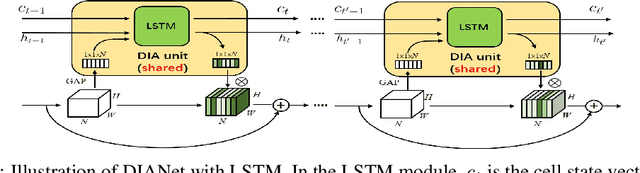
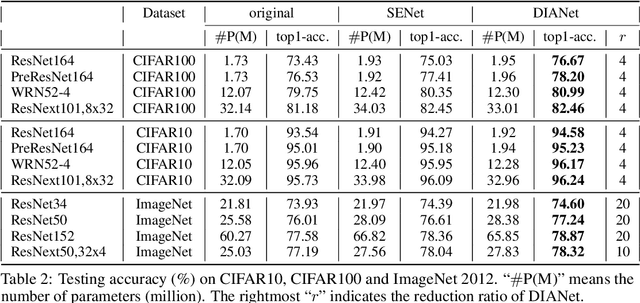
Attention-based deep neural networks (DNNs) that emphasize the informative information in a local receptive field of an input image have successfully boosted the performance of deep learning in various challenging problems. In this paper, we propose a Dense-and-Implicit-Attention (DIA) unit that can be applied universally to different network architectures and enhance their generalization capacity by repeatedly fusing the information throughout different network layers. The communication of information between different layers is carried out via a modified Long Short Term Memory (LSTM) module within the DIA unit that is in parallel with the DNN. The sharing DIA unit links multi-scale features from different depth levels of the network implicitly and densely. Experiments on benchmark datasets show that the DIA unit is capable of emphasizing channel-wise feature interrelation and leads to significant improvement of image classification accuracy. We further empirically show that the DIA unit is a nonlocal normalization tool that enhances the Batch Normalization. The code is released at https://github.com/gbup-group/DIANet.