 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Attention Network: Accelerate Attention by Searching Where to Plug
Paper and Code
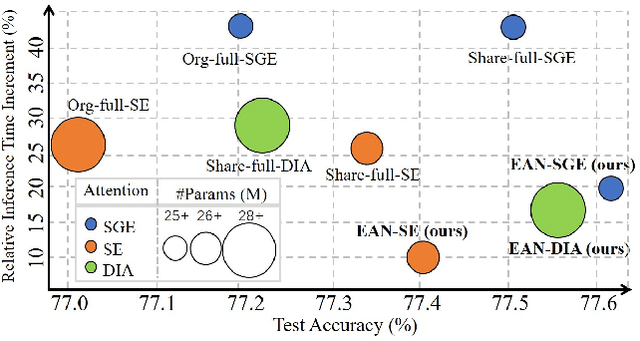
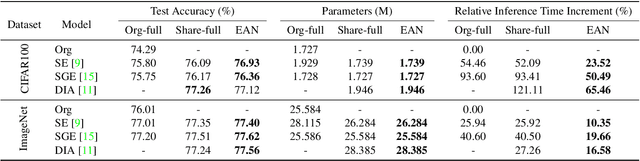
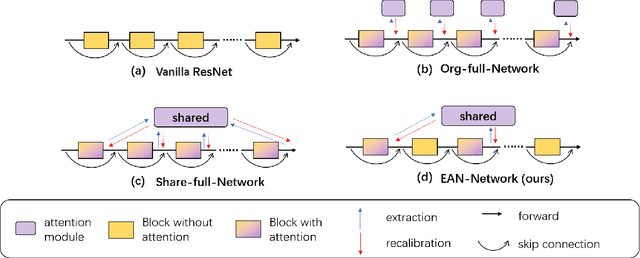
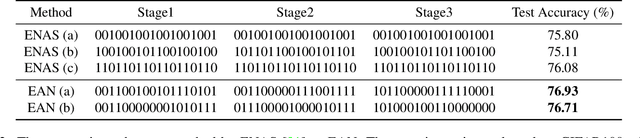
Recently, many plug-and-play self-attention modules are proposed to enhance the model generalization by exploiting the internal information of deep convolutional neural networks (CNNs). Previous works lay an emphasis on the design of attention module for specific functionality, e.g., light-weighted or task-oriented attention. However, they ignore the importance of where to plug in the attention module since they connect the modules individually with each block of the entire CNN backbone for granted, leading to incremental computational cost and number of parameters with the growth of network depth. Thus, we propose a framework called Efficient Attention Network (EAN) to improve the efficiency for the existing attention modules. In EAN, we leverage the sharing mechanism (Huang et al. 2020) to share the attention module within the backbone and search where to connect the shared attention module via reinforcement learning. Finally, we obtain the attention network with sparse connections between the backbone and modules, while (1) maintaining accuracy (2) reducing extra parameter increment and (3) accelerating inference. Extensive experiments on widely-used benchmarks and popular attention networks show the effectiveness of EAN. Furthermore, we empirically illustrate that our EAN has the capacity of transferring to other tasks and capturing the informative features. The code is available at https://github.com/gbup-group/EAN-efficient-attention-network