 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLARE: Conservative Model-Based Reward Learning for Offline Inverse Reinforcement Learning
Feb 21, 2023



This work aims to tackle a major challenge in offline Inverse Reinforcement Learning (IRL), namely the reward extrapolation error, where the learned reward function may fail to explain the task correctly and misguide the agent in unseen environments due to the intrinsic covariate shift. Leveraging both expert data and lower-quality diverse data, we devise a principled algorithm (namely CLARE) that solves offline IRL efficiently via integrating "conservatism" into a learned reward function and utilizing an estimated dynamics model. Our theoretical analysis provides an upper bound on the return gap between the learned policy and the expert policy, based on which we characterize the impact of covariate shift by examining subtle two-tier tradeoffs between the exploitation (on both expert and diverse data) and exploration (on the estimated dynamics model). We show that CLARE can provably alleviate the reward extrapolation error by striking the right exploitation-exploration balance therein. Extensive experiments corroborate the significant performance gains of CLARE over existing state-of-the-art algorithms on MuJoCo continuous control tasks (especially with a small offline dataset), and the learned reward is highly instructive for further learning.
Theory on Forgetting and Generalization of Continual Learning
Feb 12, 2023



Continual learning (CL), which aims to learn a sequence of tasks, has attracted significant recent attention. However, most work has focused on the experimental performance of CL, and theoretical studies of CL are still limited. In particular, there is a lack of understanding on what factors are important and how they affect "catastrophic forgetting" and generalization performance. To fill this gap, our theoretical analysis, under overparameterized linear models, provides the first-known explicit form of the expected forgetting and generalization error. Further analysis of such a key result yields a number of theoretical explanations about how overparameterization, task similarity, and task ordering affect both forgetting and generalization error of CL. More interestingly, by conducting experiments on real datasets using deep neural networks (DNNs), we show that some of these insights even go beyond the linear models and can be carried over to practical setups. In particular, we use concrete examples to show that our results not only explain some interesting empirical observations in recent studies, but also motivate better practical algorithm designs of CL.
Algorithm Design for Online Meta-Learning with Task Boundary Detection
Feb 02, 2023Online meta-learning has recently emerged as a marriage between batch meta-learning and online learning, for achieving the capability of quick adaptation on new tasks in a lifelong manner. However, most existing approaches focus on the restrictive setting where the distribution of the online tasks remains fixed with known task boundaries. In this work, we relax these assumptions and propose a novel algorithm for task-agnostic online meta-learning in non-stationary environments. More specifically, we first propose two simple but effective detection mechanisms of task switches and distribution shift based on empirical observations, which serve as a key building block for more elegant online model updates in our algorithm: the task switch detection mechanism allows reusing of the best model available for the current task at hand, and the distribution shift detection mechanism differentiates the meta model update in order to preserve the knowledge for in-distribution tasks and quickly learn the new knowledge for out-of-distribution tasks. In particular, our online meta model updates are based only on the current data, which eliminates the need of storing previous data as required in most existing methods. We further show that a sublinear task-averaged regret can be achieved for our algorithm under mild conditions. Empirical studies on three different benchmarks clearly demonstrate the significant advantage of our algorithm over related baseline approaches.
Beyond Not-Forgetting: Continual Learning with Backward Knowledge Transfer
Nov 01, 2022



By learning a sequence of tasks continually, an agent in continual learning (CL) can improve the learning performance of both a new task and `old' tasks by leveraging the forward knowledge transfer and the backward knowledge transfer, respectively. However, most existing CL methods focus on addressing catastrophic forgetting in neural networks by minimizing the modification of the learnt model for old tasks. This inevitably limits the backward knowledge transfer from the new task to the old tasks, because judicious model updates could possibly improve the learning performance of the old tasks as well. To tackle this problem, we first theoretically analyze the conditions under which updating the learnt model of old tasks could be beneficial for CL and also lead to backward knowledge transfer, based on the gradient projection onto the input subspaces of old tasks. Building on the theoretical analysis, we next develop a ContinUal learning method with Backward knowlEdge tRansfer (CUBER), for a fixed capacity neural network without data replay. In particular, CUBER first characterizes the task correlation to identify the positively correlated old tasks in a layer-wise manner, and then selectively modifies the learnt model of the old tasks when learning the new task. Experimental studies show that CUBER can even achieve positive backward knowledge transfer on several existing CL benchmarks for the first time without data replay, where the related baselines still suffer from catastrophic forgetting (negative backward knowledge transfer). The superior performance of CUBER on the backward knowledge transfer also leads to higher accuracy accordingly.
TRGP: Trust Region Gradient Projection for Continual Learning
Feb 07, 2022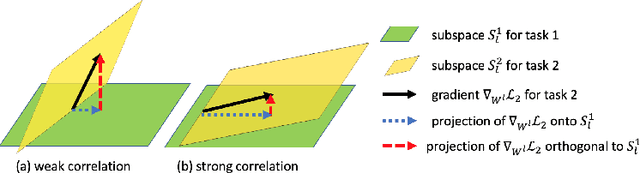
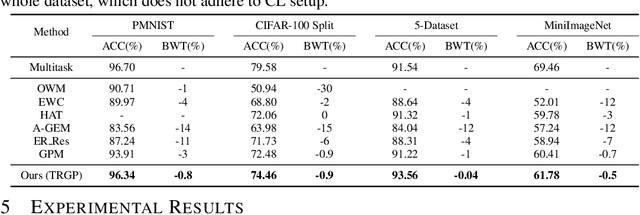

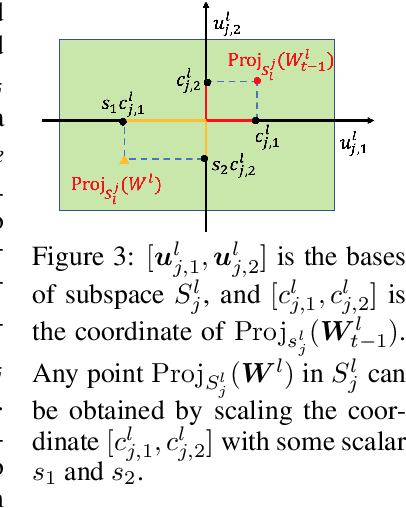
Catastrophic forgetting is one of the major challenges in continual learning. To address this issue, some existing methods put restrictive constraints on the optimization space of the new task for minimizing the interference to old tasks. However, this may lead to unsatisfactory performance for the new task, especially when the new task is strongly correlated with old tasks. To tackle this challenge, we propose Trust Region Gradient Projection (TRGP) for continual learning to facilitate the forward knowledge transfer based on an efficient characterization of task correlation. Particularly, we introduce a notion of `trust region' to select the most related old tasks for the new task in a layer-wise and single-shot manner, using the norm of gradient projection onto the subspace spanned by task inputs. Then, a scaled weight projection is proposed to cleverly reuse the frozen weights of the selected old tasks in the trust region through a layer-wise scaling matrix. By jointly optimizing the scaling matrices and the model, where the model is updated along the directions orthogonal to the subspaces of old tasks, TRGP can effectively prompt knowledge transfer without forgetting. Extensive experiments show that our approach achieves significant improvement over related state-of-the-art methods.
Model-Based Offline Meta-Reinforcement Learning with Regularization
Feb 07, 2022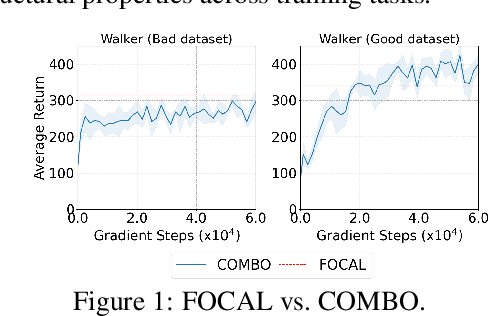
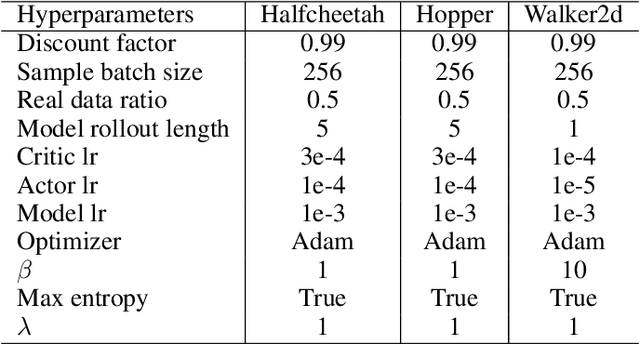
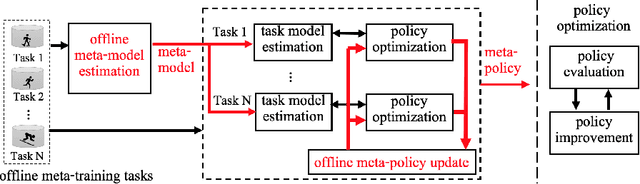
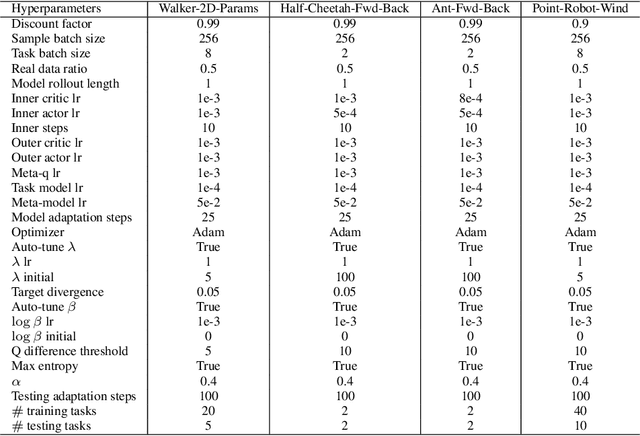
Existing offline reinforcement learning (RL) methods face a few major challenges, particularly the distributional shift between the learned policy and the behavior policy. Offline Meta-RL is emerging as a promising approach to address these challenges, aiming to learn an informative meta-policy from a collection of tasks. Nevertheless, as shown in our empirical studies, offline Meta-RL could be outperformed by offline single-task RL methods on tasks with good quality of datasets, indicating that a right balance has to be delicately calibrated between "exploring" the out-of-distribution state-actions by following the meta-policy and "exploiting" the offline dataset by staying close to the behavior policy. Motivated by such empirical analysis, we explore model-based offline Meta-RL with regularized Policy Optimization (MerPO), which learns a meta-model for efficient task structure inference and an informative meta-policy for safe exploration of out-of-distribution state-actions. In particular, we devise a new meta-Regularized model-based Actor-Critic (RAC) method for within-task policy optimization, as a key building block of MerPO, using conservative policy evaluation and regularized policy improvement; and the intrinsic tradeoff therein is achieved via striking the right balance between two regularizers, one based on the behavior policy and the other on the meta-policy. We theoretically show that the learnt policy offers guaranteed improvement over both the behavior policy and the meta-policy, thus ensuring the performance improvement on new tasks via offline Meta-RL. Experiments corroborate the superior performance of MerPO over existing offline Meta-RL methods.
Approximation of Images via Generalized Higher Order Singular Value Decomposition over Finite-dimensional Commutative Semisimple Algebra
Feb 03, 2022


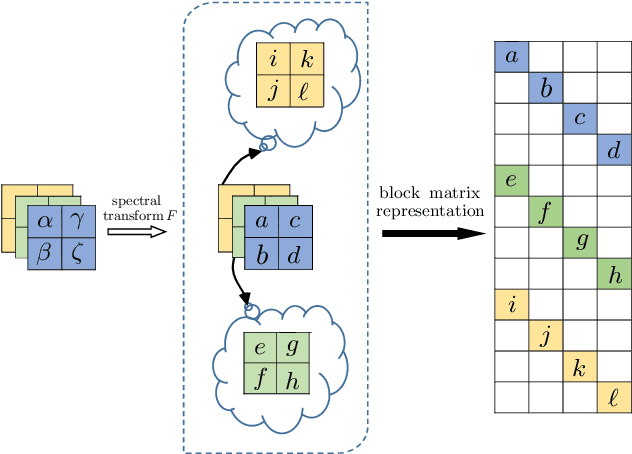
Low-rank approximation of images via singular value decomposition is well-received in the era of big data. However, singular value decomposition (SVD) is only for order-two data, i.e., matrices. It is necessary to flatten a higher order input into a matrix or break it into a series of order-two slices to tackle higher order data such as multispectral images and videos with the SVD. Higher order singular value decomposition (HOSVD) extends the SVD and can approximate higher order data using sums of a few rank-one components. We consider the problem of generalizing HOSVD over a finite dimensional commutative algebra. This algebra, referred to as a t-algebra, generalizes the field of complex numbers. The elements of the algebra, called t-scalars, are fix-sized arrays of complex numbers. One can generalize matrices and tensors over t-scalars and then extend many canonical matrix and tensor algorithms, including HOSVD, to obtain higher-performance versions. The generalization of HOSVD is called THOSVD. Its performance of approximating multi-way data can be further improved by an alternating algorithm. THOSVD also unifies a wide range of principal component analysis algorithms. To exploit the potential of generalized algorithms using t-scalars for approximating images, we use a pixel neighborhood strategy to convert each pixel to "deeper-order" t-scalar. Experiments on publicly available images show that the generalized algorithm over t-scalars, namely THOSVD, compares favorably with its canonical counterparts.
GROWN: GRow Only When Necessary for Continual Learning
Oct 03, 2021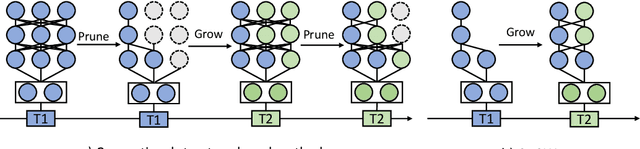
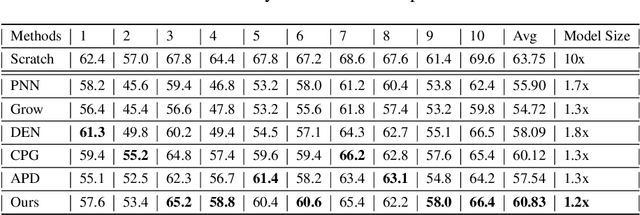

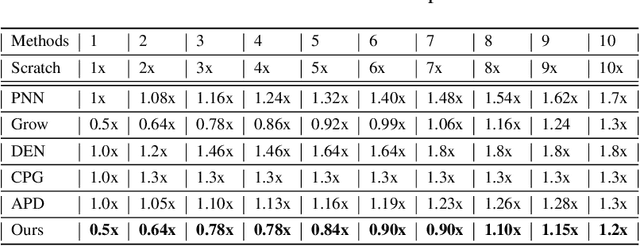
Catastrophic forgetting is a notorious issue in deep learning, referring to the fact that Deep Neural Networks (DNN) could forget the knowledge about earlier tasks when learning new tasks. To address this issue, continual learning has been developed to learn new tasks sequentially and perform knowledge transfer from the old tasks to the new ones without forgetting. While recent structure-based learning methods show the capability of alleviating the forgetting problem, these methods start from a redundant full-size network and require a complex learning process to gradually grow-and-prune or search the network structure for each task, which is inefficient. To address this problem and enable efficient network expansion for new tasks, we first develop a learnable sparse growth method eliminating the additional pruning/searching step in previous structure-based methods. Building on this learnable sparse growth method, we then propose GROWN, a novel end-to-end continual learning framework to dynamically grow the model only when necessary. Different from all previous structure-based methods, GROWN starts from a small seed network, instead of a full-sized one. We validate GROWN on multiple datasets against state-of-the-art methods, which shows superior performance in both accuracy and model size. For example, we achieve 1.0\% accuracy gain on average compared to the current SOTA results on CIFAR-100 Superclass 20 tasks setting.
Continual Learning of Generative Models with Limited Data: From Wasserstein-1 Barycenter to Adaptive Coalescence
Jan 22, 2021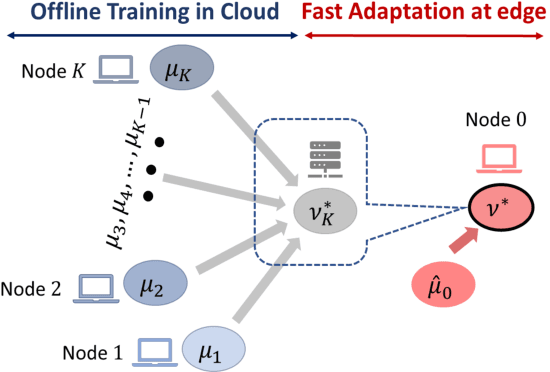

Learning generative models is challenging for a network edge node with limited data and computing power. Since tasks in similar environments share model similarity, it is plausible to leverage pre-trained generative models from the cloud or other edge nodes. Appealing to optimal transport theory tailored towards Wasserstein-1 generative adversarial networks (WGAN), this study aims to develop a framework which systematically optimizes continual learning of generative models using local data at the edge node while exploiting adaptive coalescence of pre-trained generative models. Specifically, by treating the knowledge transfer from other nodes as Wasserstein balls centered around their pre-trained models, continual learning of generative models is cast as a constrained optimization problem, which is further reduced to a Wasserstein-1 barycenter problem. A two-stage approach is devised accordingly: 1) The barycenters among the pre-trained models are computed offline, where displacement interpolation is used as the theoretic foundation for finding adaptive barycenters via a "recursive" WGAN configuration; 2) the barycenter computed offline is used as meta-model initialization for continual learning and then fast adaptation is carried out to find the generative model using the local samples at the target edge node. Finally, a weight ternarization method, based on joint optimization of weights and threshold for quantization, is developed to compress the generative model further.
Generalized Image Reconstruction over T-Algebra
Jan 20, 2021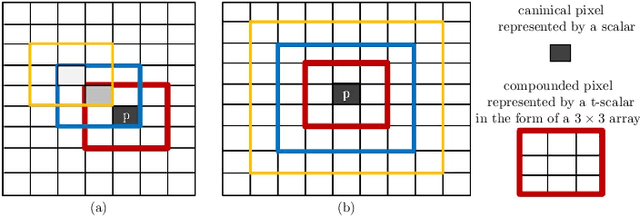
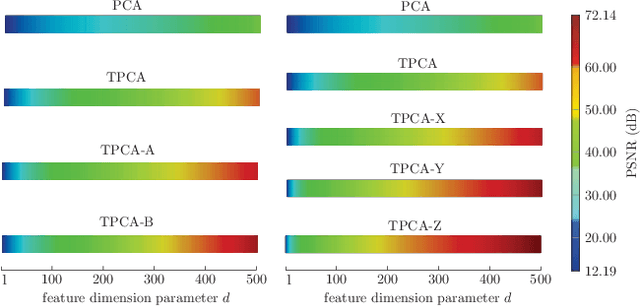
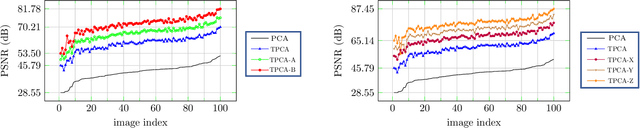
Principal Component Analysis (PCA) is well known for its capability of dimension reduction and data compression. However, when using PCA for compressing/reconstructing images, images need to be recast to vectors. The vectorization of images makes some correlation constraints of neighboring pixels and spatial information lost. To deal with the drawbacks of the vectorizations adopted by PCA, we used small neighborhoods of each pixel to form compounded pixels and use a tensorial version of PCA, called TPCA (Tensorial Principal Component Analysis), to compress and reconstruct a compounded image of compounded pixels. Our experiments on public data show that TPCA compares favorably with PCA in compressing and reconstructing images. We also show in our experiments that the performance of TPCA increases when the order of compounded pixels increases.