 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCritical Parameters for Scalable Distributed Learning with Large Batches and Asynchronous Updates
Mar 03, 2021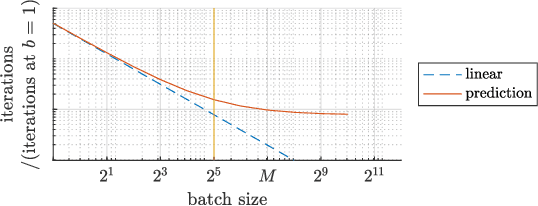

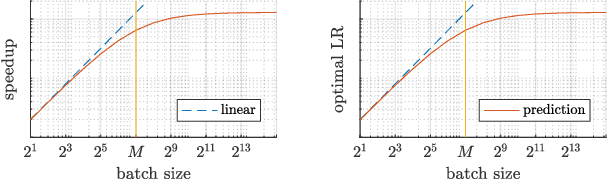
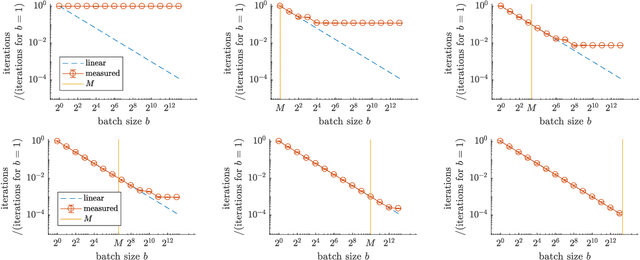
It has been experimentally observed that the efficiency of distributed training with stochastic gradient (SGD) depends decisively on the batch size and -- in asynchronous implementations -- on the gradient staleness. Especially, it has been observed that the speedup saturates beyond a certain batch size and/or when the delays grow too large. We identify a data-dependent parameter that explains the speedup saturation in both these settings. Our comprehensive theoretical analysis, for strongly convex, convex and non-convex settings, unifies and generalized prior work directions that often focused on only one of these two aspects. In particular, our approach allows us to derive improved speedup results under frequently considered sparsity assumptions. Our insights give rise to theoretically based guidelines on how the learning rates can be adjusted in practice. We show that our results are tight and illustrate key findings in numerical experiments.
Consensus Control for Decentralized Deep Learning
Feb 09, 2021
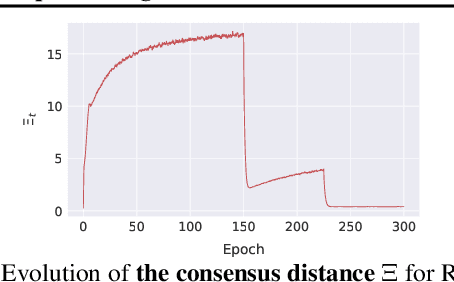
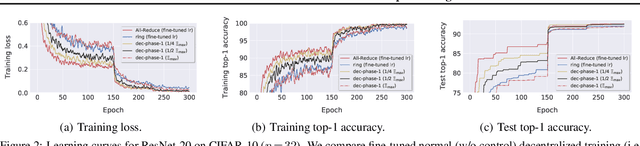

Decentralized training of deep learning models enables on-device learning over networks, as well as efficient scaling to large compute clusters. Experiments in earlier works reveal that, even in a data-center setup, decentralized training often suffers from the degradation in the quality of the model: the training and test performance of models trained in a decentralized fashion is in general worse than that of models trained in a centralized fashion, and this performance drop is impacted by parameters such as network size, communication topology and data partitioning. We identify the changing consensus distance between devices as a key parameter to explain the gap between centralized and decentralized training. We show in theory that when the training consensus distance is lower than a critical quantity, decentralized training converges as fast as the centralized counterpart. We empirically validate that the relation between generalization performance and consensus distance is consistent with this theoretical observation. Our empirical insights allow the principled design of better decentralized training schemes that mitigate the performance drop. To this end, we propose practical training guidelines for the data-center setup as the important first step.
Quasi-Global Momentum: Accelerating Decentralized Deep Learning on Heterogeneous Data
Feb 09, 2021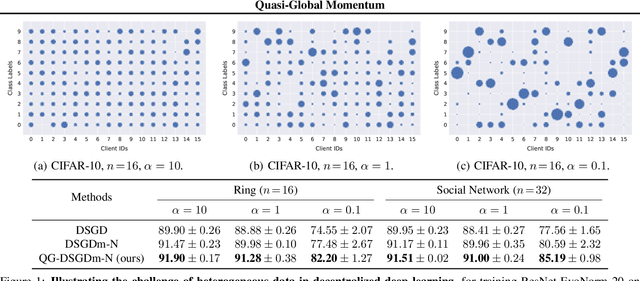
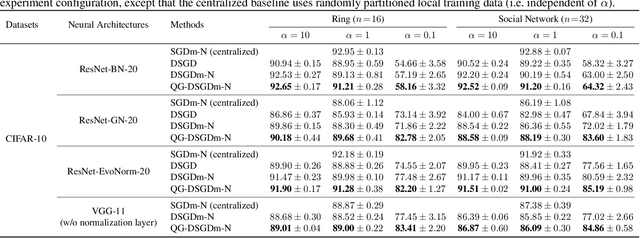
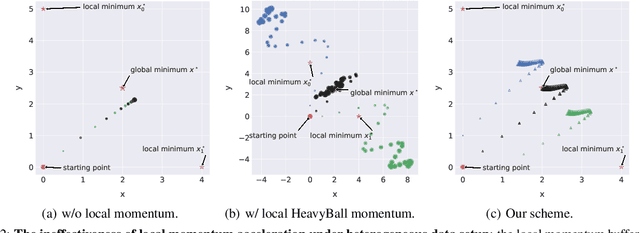
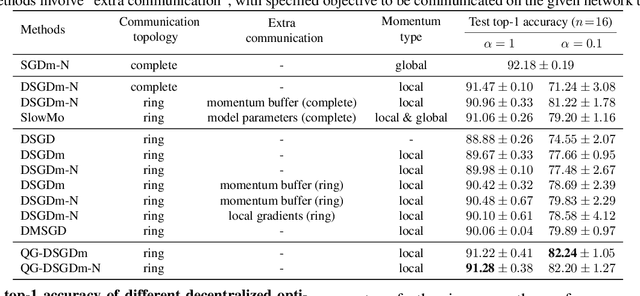
Decentralized training of deep learning models is a key element for enabling data privacy and on-device learning over networks. In realistic learning scenarios, the presence of heterogeneity across different clients' local datasets poses an optimization challenge and may severely deteriorate the generalization performance. In this paper, we investigate and identify the limitation of several decentralized optimization algorithms for different degrees of data heterogeneity. We propose a novel momentum-based method to mitigate this decentralized training difficulty. We show in extensive empirical experiments on various CV/NLP datasets (CIFAR-10, ImageNet, AG News, and SST2) and several network topologies (Ring and Social Network) that our method is much more robust to the heterogeneity of clients' data than other existing methods, by a significant improvement in test performance ($1\% \!-\! 20\%$).
A Linearly Convergent Algorithm for Decentralized Optimization: Sending Less Bits for Free!
Nov 03, 2020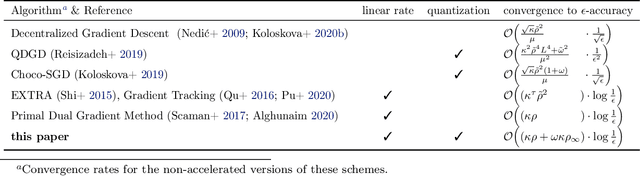
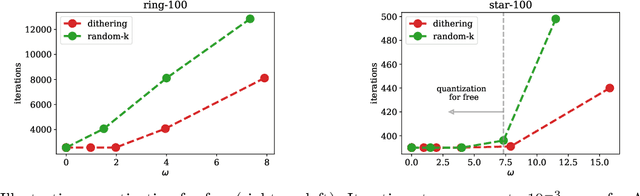

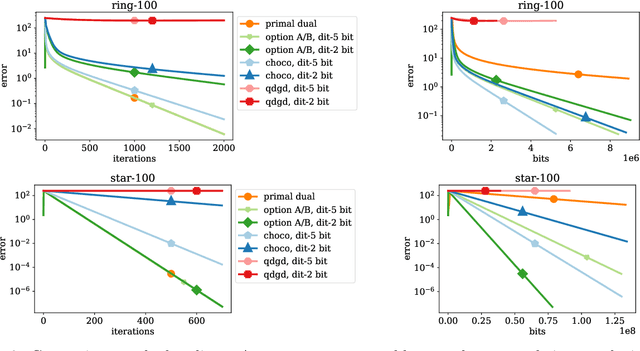
Decentralized optimization methods enable on-device training of machine learning models without a central coordinator. In many scenarios communication between devices is energy demanding and time consuming and forms the bottleneck of the entire system. We propose a new randomized first-order method which tackles the communication bottleneck by applying randomized compression operators to the communicated messages. By combining our scheme with a new variance reduction technique that progressively throughout the iterations reduces the adverse effect of the injected quantization noise, we obtain the first scheme that converges linearly on strongly convex decentralized problems while using compressed communication only. We prove that our method can solve the problems without any increase in the number of communications compared to the baseline which does not perform any communication compression while still allowing for a significant compression factor which depends on the conditioning of the problem and the topology of the network. Our key theoretical findings are supported by numerical experiments.
On Communication Compression for Distributed Optimization on Heterogeneous Data
Sep 04, 2020
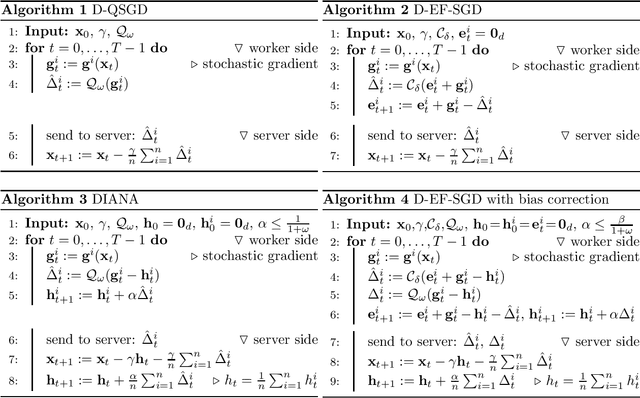

Lossy gradient compression, with either unbiased or biased compressors, has become a key tool to avoid the communication bottleneck in centrally coordinated distributed training of machine learning models. We analyze the performance of two standard and general types of methods: (i) distributed quantized SGD (D-QSGD) with arbitrary unbiased quantizers and (ii) distributed SGD with error-feedback and biased compressors (D-EF-SGD) in the heterogeneous (non-iid) data setting. Our results indicate that D-EF-SGD is much less affected than D-QSGD by non-iid data, but both methods can suffer a slowdown if data-skewness is high. We propose two alternatives that are not (or much less) affected by heterogenous data distributions: a new method that is only applicable to strongly convex problems, and we point out a more general approach that is applicable to linear compressors.
Mime: Mimicking Centralized Stochastic Algorithms in Federated Learning
Aug 08, 2020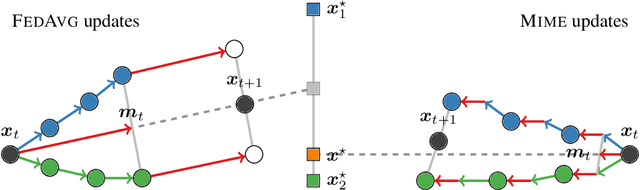

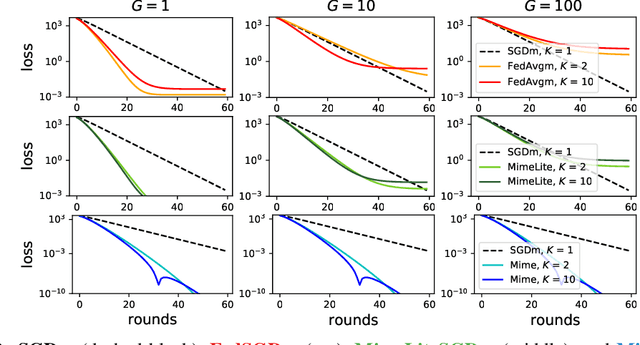

Federated learning is a challenging optimization problem due to the heterogeneity of the data across different clients. Such heterogeneity has been observed to induce client drift and significantly degrade the performance of algorithms designed for this setting. In contrast, centralized learning with centrally collected data does not experience such drift, and has seen great empirical and theoretical progress with innovations such as momentum, adaptivity, etc. In this work, we propose a general framework Mime which mitigates client-drift and adapts arbitrary centralized optimization algorithms (e.g.\ SGD, Adam, etc.) to federated learning. Mime uses a combination of control-variates and server-level statistics (e.g. momentum) at every client-update step to ensure that each local update mimics that of the centralized method. Our thorough theoretical and empirical analyses strongly establish Mime's superiority over other baselines.
Analysis of SGD with Biased Gradient Estimators
Jul 31, 2020
We analyze the complexity of biased stochastic gradient methods (SGD), where individual updates are corrupted by deterministic, i.e. biased error terms. We derive convergence results for smooth (non-convex) functions and give improved rates under the Polyak-Lojasiewicz condition. We quantify how the magnitude of the bias impacts the attainable accuracy and convergence rates. Our framework covers many applications where either only biased gradient updates are available or preferred over unbiased ones for performance reasons. For instance, in the domain of distributed learning, biased gradient compression techniques such as top-k compression have been proposed as a tool to alleviate the communication bottleneck and in derivative-free optimization, only biased gradient estimators can be queried. We discuss a few guiding examples that show the broad applicability of our analysis.
Dynamic Model Pruning with Feedback
Jun 12, 2020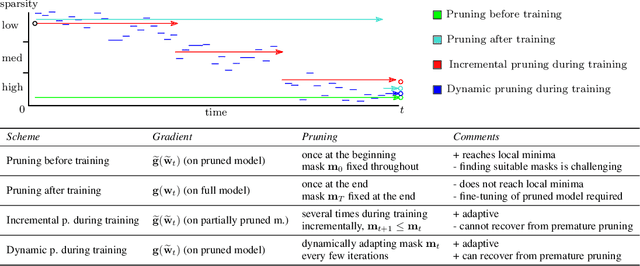
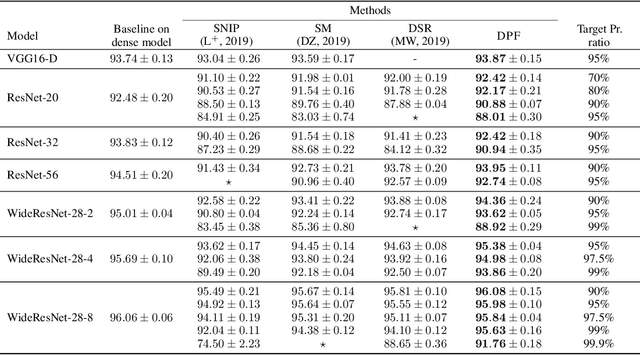
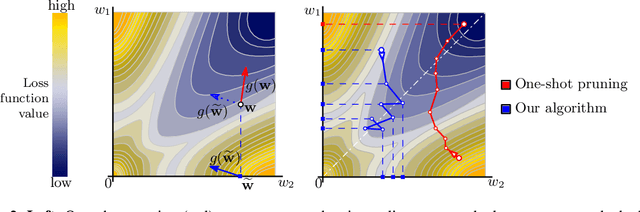
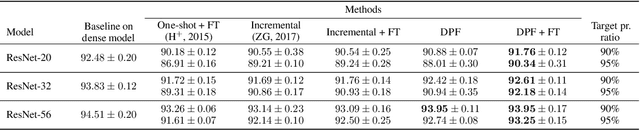
Deep neural networks often have millions of parameters. This can hinder their deployment to low-end devices, not only due to high memory requirements but also because of increased latency at inference. We propose a novel model compression method that generates a sparse trained model without additional overhead: by allowing (i) dynamic allocation of the sparsity pattern and (ii) incorporating feedback signal to reactivate prematurely pruned weights we obtain a performant sparse model in one single training pass (retraining is not needed, but can further improve the performance). We evaluate our method on CIFAR-10 and ImageNet, and show that the obtained sparse models can reach the state-of-the-art performance of dense models. Moreover, their performance surpasses that of models generated by all previously proposed pruning schemes.
Ensemble Distillation for Robust Model Fusion in Federated Learning
Jun 12, 2020
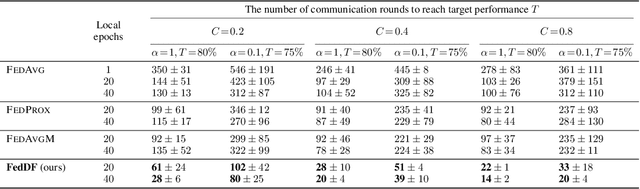

Federated Learning (FL) is a machine learning setting where many devices collaboratively train a machine learning model while keeping the training data decentralized. In most of the current training schemes the central model is refined by averaging the parameters of the server model and the updated parameters from the client side. However, directly averaging model parameters is only possible if all models have the same structure and size, which could be a restrictive constraint in many scenarios. In this work we investigate more powerful and more flexible aggregation schemes for FL. Specifically, we propose ensemble distillation for model fusion, i.e. training the central classifier through unlabeled data on the outputs of the models from the clients. This knowledge distillation technique mitigates privacy risk and cost to the same extent as the baseline FL algorithms, but allows flexible aggregation over heterogeneous client models that can differ e.g. in size, numerical precision or structure. We show in extensive empirical experiments on various CV/NLP datasets (CIFAR-10/100, ImageNet, AG News, SST2) and settings (heterogeneous models/data) that the server model can be trained much faster, requiring fewer communication rounds than any existing FL technique so far.
Extrapolation for Large-batch Training in Deep Learning
Jun 10, 2020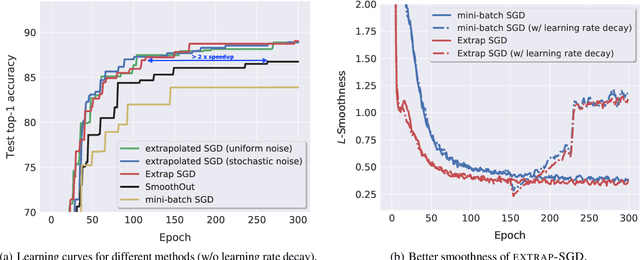

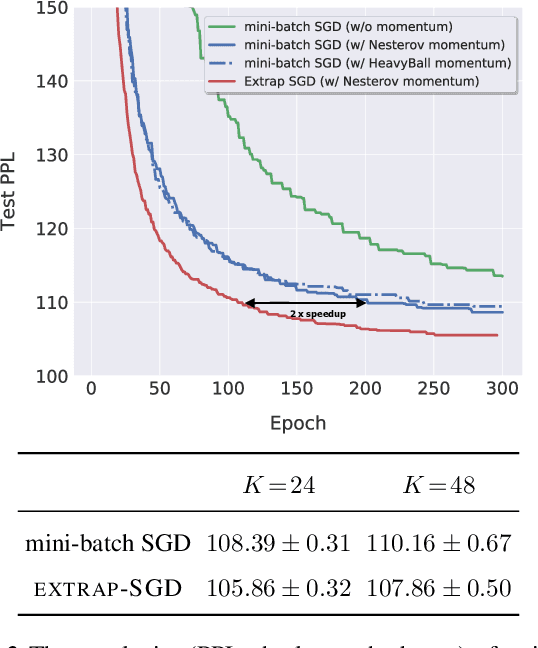

Deep learning networks are typically trained by Stochastic Gradient Descent (SGD) methods that iteratively improve the model parameters by estimating a gradient on a very small fraction of the training data. A major roadblock faced when increasing the batch size to a substantial fraction of the training data for improving training time is the persistent degradation in performance (generalization gap). To address this issue, recent work propose to add small perturbations to the model parameters when computing the stochastic gradients and report improved generalization performance due to smoothing effects. However, this approach is poorly understood; it requires often model-specific noise and fine-tuning. To alleviate these drawbacks, we propose to use instead computationally efficient extrapolation (extragradient) to stabilize the optimization trajectory while still benefiting from smoothing to avoid sharp minima. This principled approach is well grounded from an optimization perspective and we show that a host of variations can be covered in a unified framework that we propose. We prove the convergence of this novel scheme and rigorously evaluate its empirical performance on ResNet, LSTM, and Transformer. We demonstrate that in a variety of experiments the scheme allows scaling to much larger batch sizes than before whilst reaching or surpassing SOTA accuracy.