 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoing Beyond the Cookie Theft Picture Test: Detecting Cognitive Impairments using Acoustic Features
Jun 10, 2022

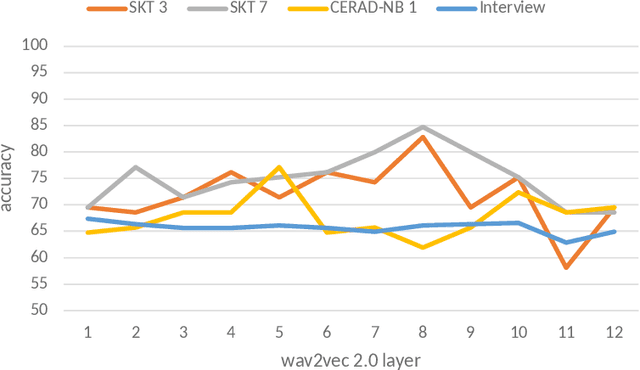
Standardized tests play a crucial role in the detection of cognitive impairment. Previous work demonstrated that automatic detection of cognitive impairment is possible using audio data from a standardized picture description task. The presented study goes beyond that, evaluating our methods on data taken from two standardized neuropsychological tests, namely the German SKT and a German version of the CERAD-NB, and a semi-structured clinical interview between a patient and a psychologist. For the tests, we focus on speech recordings of three sub-tests: reading numbers (SKT 3), interference (SKT 7), and verbal fluency (CERAD-NB 1). We show that acoustic features from standardized tests can be used to reliably discriminate cognitively impaired individuals from non-impaired ones. Furthermore, we provide evidence that even features extracted from random speech samples of the interview can be a discriminator of cognitive impairment. In our baseline experiments, we use OpenSMILE features and Support Vector Machine classifiers. In an improved setup, we show that using wav2vec 2.0 features instead, we can achieve an accuracy of up to 85%.
The Influence of Dataset Partitioning on Dysfluency Detection Systems
Jun 07, 2022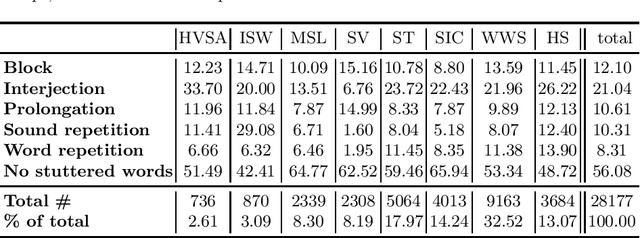

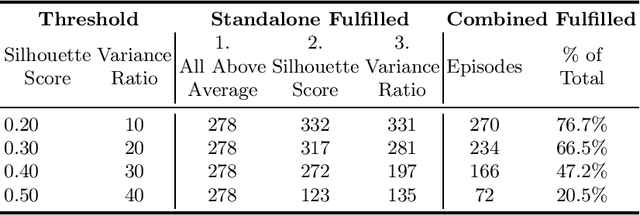
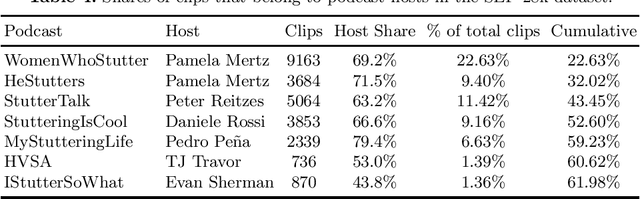
This paper empirically investigates the influence of different data splits and splitting strategies on the performance of dysfluency detection systems. For this, we perform experiments using wav2vec 2.0 models with a classification head as well as support vector machines (SVM) in conjunction with the features extracted from the wav2vec 2.0 model to detect dysfluencies. We train and evaluate the systems with different non-speaker-exclusive and speaker-exclusive splits of the Stuttering Events in Podcasts (SEP-28k) dataset to shed some light on the variability of results w.r.t. to the partition method used. Furthermore, we show that the SEP-28k dataset is dominated by only a few speakers, making it difficult to evaluate. To remedy this problem, we created SEP-28k-Extended (SEP-28k-E), containing semi-automatically generated speaker and gender information for the SEP-28k corpus, and suggest different data splits, each useful for evaluating other aspects of methods for dysfluency detection.
The ACM Multimedia 2022 Computational Paralinguistics Challenge: Vocalisations, Stuttering, Activity, & Mosquitoes
May 13, 2022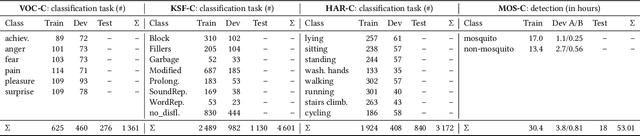

The ACM Multimedia 2022 Computational Paralinguistics Challenge addresses four different problems for the first time in a research competition under well-defined conditions: In the Vocalisations and Stuttering Sub-Challenges, a classification on human non-verbal vocalisations and speech has to be made; the Activity Sub-Challenge aims at beyond-audio human activity recognition from smartwatch sensor data; and in the Mosquitoes Sub-Challenge, mosquitoes need to be detected. We describe the Sub-Challenges, baseline feature extraction, and classifiers based on the usual ComPaRE and BoAW features, the auDeep toolkit, and deep feature extraction from pre-trained CNNs using the DeepSpectRum toolkit; in addition, we add end-to-end sequential modelling, and a log-mel-128-BNN.
Detecting Vocal Fatigue with Neural Embeddings
Apr 07, 2022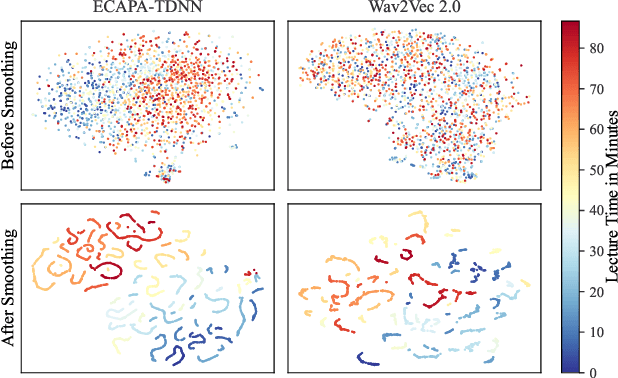
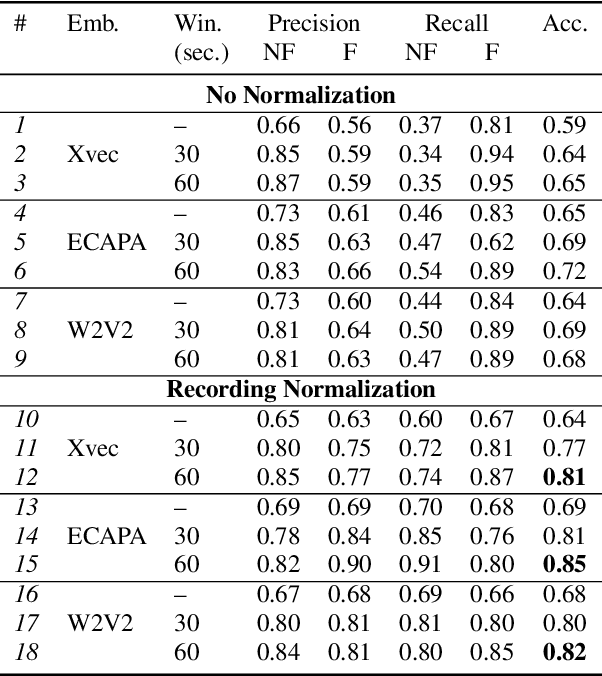
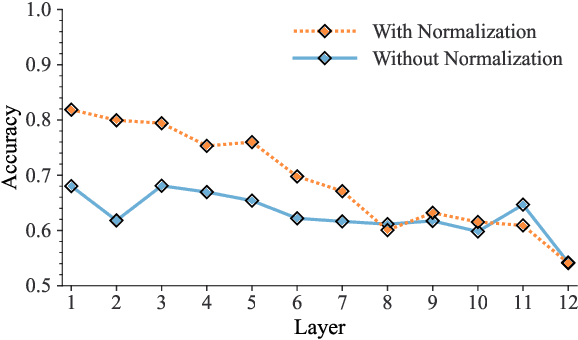
Vocal fatigue refers to the feeling of tiredness and weakness of voice due to extended utilization. This paper investigates the effectiveness of neural embeddings for the detection of vocal fatigue. We compare x-vectors, ECAPA-TDNN, and wav2vec 2.0 embeddings on a corpus of academic spoken English. Low-dimensional mappings of the data reveal that neural embeddings capture information about the change in vocal characteristics of a speaker during prolonged voice usage. We show that vocal fatigue can be reliably predicted using all three kinds of neural embeddings after only 50 minutes of continuous speaking when temporal smoothing and normalization are applied to the extracted embeddings. We employ support vector machines for classification and achieve accuracy scores of 81% using x-vectors, 85% using ECAPA-TDNN embeddings, and 82% using wav2vec 2.0 embeddings as input features. We obtain an accuracy score of 76%, when the trained system is applied to a different speaker and recording environment without any adaptation.
Detecting Dysfluencies in Stuttering Therapy Using wav2vec 2.0
Apr 07, 2022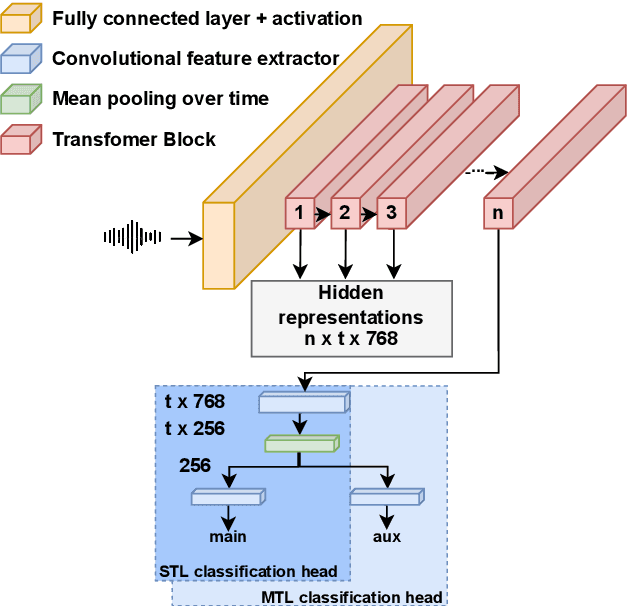
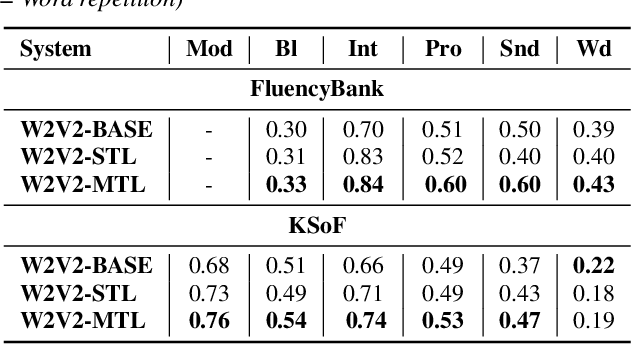

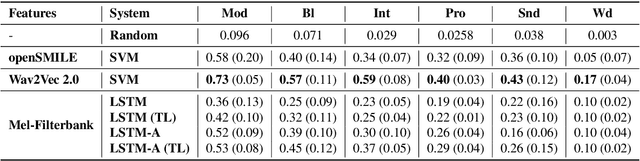
Stuttering is a varied speech disorder that harms an individual's communication ability. Persons who stutter (PWS) often use speech therapy to cope with their condition. Improving speech recognition systems for people with such non-typical speech or tracking the effectiveness of speech therapy would require systems that can detect dysfluencies while at the same time being able to detect speech techniques acquired in therapy. This paper shows that fine-tuning wav2vec 2.0 for the classification of stuttering on a sizeable English corpus containing stuttered speech, in conjunction with multi-task learning, boosts the effectiveness of the general-purpose wav2vec 2.0 features for detecting stuttering in speech; both within and across languages. We evaluate our method on Fluencybank and the German therapy-centric Kassel State of Fluency (KSoF) dataset by training Support Vector Machine classifiers using features extracted from the fine-tuned models for six different stuttering-related events types: blocks, prolongations, sound repetitions, word repetitions, interjections, and - specific to therapy - speech modifications. Using embeddings from the fine-tuned models leads to relative classification performance gains up to 27\% w.r.t. F1-score.
KSoF: The Kassel State of Fluency Dataset -- A Therapy Centered Dataset of Stuttering
Mar 10, 2022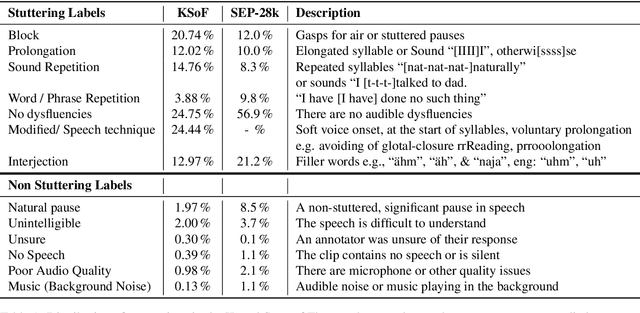
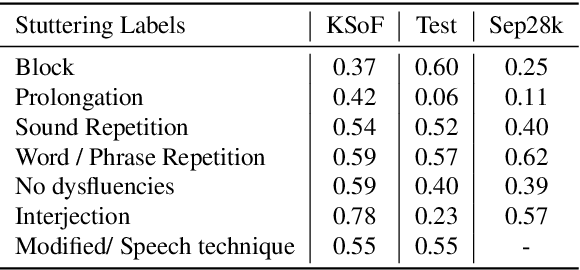
Stuttering is a complex speech disorder that negatively affects an individual's ability to communicate effectively. Persons who stutter (PWS) often suffer considerably under the condition and seek help through therapy. Fluency shaping is a therapy approach where PWSs learn to modify their speech to help them to overcome their stutter. Mastering such speech techniques takes time and practice, even after therapy. Shortly after therapy, success is evaluated highly, but relapse rates are high. To be able to monitor speech behavior over a long time, the ability to detect stuttering events and modifications in speech could help PWSs and speech pathologists to track the level of fluency. Monitoring could create the ability to intervene early by detecting lapses in fluency. To the best of our knowledge, no public dataset is available that contains speech from people who underwent stuttering therapy that changed the style of speaking. This work introduces the Kassel State of Fluency (KSoF), a therapy-based dataset containing over 5500 clips of PWSs. The clips were labeled with six stuttering-related event types: blocks, prolongations, sound repetitions, word repetitions, interjections, and - specific to therapy - speech modifications. The audio was recorded during therapy sessions at the Institut der Kasseler Stottertherapie. The data will be made available for research purposes upon request.
Detecting Emotion Carriers by Combining Acoustic and Lexical Representations
Dec 13, 2021
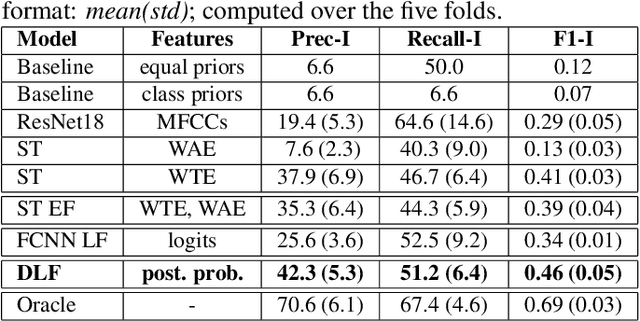
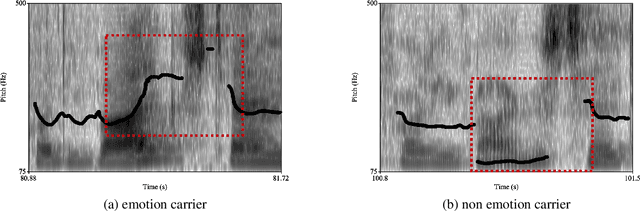
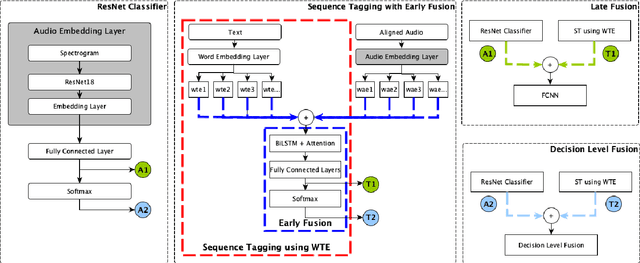
Personal narratives (PN) - spoken or written - are recollections of facts, people, events, and thoughts from one's own experience. Emotion recognition and sentiment analysis tasks are usually defined at the utterance or document level. However, in this work, we focus on Emotion Carriers (EC) defined as the segments (speech or text) that best explain the emotional state of the narrator ("loss of father", "made me choose"). Once extracted, such EC can provide a richer representation of the user state to improve natural language understanding and dialogue modeling. In previous work, it has been shown that EC can be identified using lexical features. However, spoken narratives should provide a richer description of the context and the users' emotional state. In this paper, we leverage word-based acoustic and textual embeddings as well as early and late fusion techniques for the detection of ECs in spoken narratives. For the acoustic word-level representations, we use Residual Neural Networks (ResNet) pretrained on separate speech emotion corpora and fine-tuned to detect EC. Experiments with different fusion and system combination strategies show that late fusion leads to significant improvements for this task.
STAN: A stuttering therapy analysis helper
Jun 15, 2021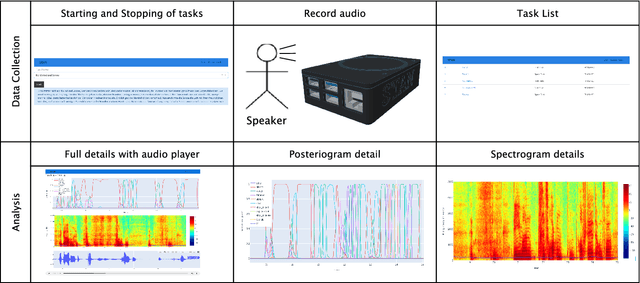
Stuttering is a complex speech disorder identified by repeti-tions, prolongations of sounds, syllables or words and blockswhile speaking. Specific stuttering behaviour differs strongly,thus needing personalized therapy. Therapy sessions requirea high level of concentration by the therapist. We introduceSTAN, a system to aid speech therapists in stuttering therapysessions. Such an automated feedback system can lower thecognitive load on the therapist and thereby enable a more con-sistent therapy as well as allowing analysis of stuttering overthe span of multiple therapy sessions.
Towards Automated Assessment of Stuttering and Stuttering Therapy
Jun 16, 2020
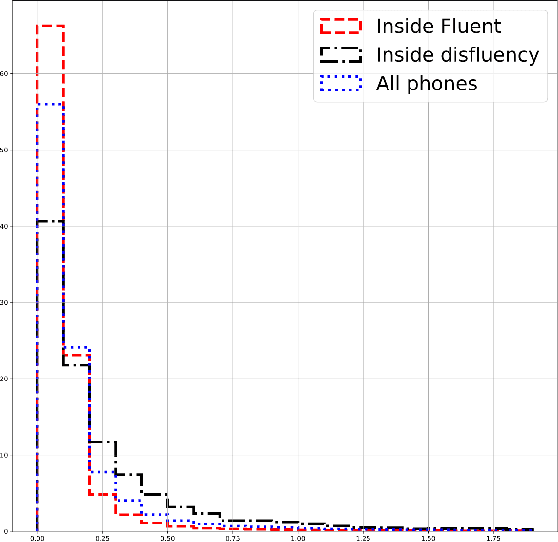
Stuttering is a complex speech disorder that can be identified by repetitions, prolongations of sounds, syllables or words, and blocks while speaking. Severity assessment is usually done by a speech therapist. While attempts at automated assessment were made, it is rarely used in therapy. Common methods for the assessment of stuttering severity include percent stuttered syllables (% SS), the average of the three longest stuttering symptoms during a speech task, or the recently introduced Speech Efficiency Score (SES). This paper introduces the Speech Control Index (SCI), a new method to evaluate the severity of stuttering. Unlike SES, it can also be used to assess therapy success for fluency shaping. We evaluate both SES and SCI on a new comprehensively labeled dataset containing stuttered German speech of clients prior to, during, and after undergoing stuttering therapy. Phone alignments of an automatic speech recognition system are statistically evaluated in relation to their relative position to labeled stuttering events. The results indicate that phone length distributions differ with respect to their position in and around labeled stuttering events
A Comparison of Hybrid and End-to-End Models for Syllable Recognition
Sep 19, 2019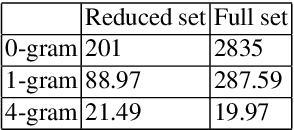
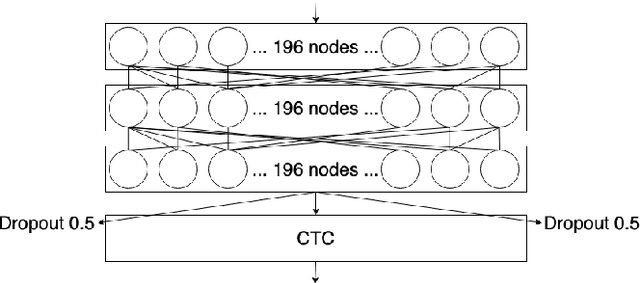
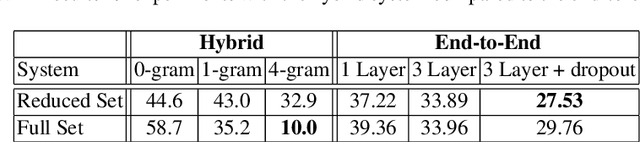
This paper presents a comparison of a traditional hybrid speech recognition system (kaldi using WFST and TDNN with lattice-free MMI) and a lexicon-free end-to-end (TensorFlow implementation of multi-layer LSTM with CTC training) models for German syllable recognition on the Verbmobil corpus. The results show that explicitly modeling prior knowledge is still valuable in building recognition systems. With a strong language model (LM) based on syllables, the structured approach significantly outperforms the end-to-end model. The best word error rate (WER) regarding syllables was achieved using kaldi with a 4-gram LM, modeling all syllables observed in the training set. It achieved 10.0% WER w.r.t. the syllables, compared to the end-to-end approach where the best WER was 27.53%. The work presented here has implications for building future recognition systems that operate independent of a large vocabulary, as typically used in a tasks such as recognition of syllabic or agglutinative languages, out-of-vocabulary techniques, keyword search indexing and medical speech processing.