 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteuerLLM: Local specialized large language model for German tax law analysis
Feb 11, 2026Large language models (LLMs) demonstrate strong general reasoning and language understanding, yet their performance degrades in domains governed by strict formal rules, precise terminology, and legally binding structure. Tax law exemplifies these challenges, as correct answers require exact statutory citation, structured legal argumentation, and numerical accuracy under rigid grading schemes. We algorithmically generate SteuerEx, the first open benchmark derived from authentic German university tax law examinations. SteuerEx comprises 115 expert-validated examination questions spanning six core tax law domains and multiple academic levels, and employs a statement-level, partial-credit evaluation framework that closely mirrors real examination practice. We further present SteuerLLM, a domain-adapted LLM for German tax law trained on a large-scale synthetic dataset generated from authentic examination material using a controlled retrieval-augmented pipeline. SteuerLLM (28B parameters) consistently outperforms general-purpose instruction-tuned models of comparable size and, in several cases, substantially larger systems, demonstrating that domain-specific data and architectural adaptation are more decisive than parameter scale for performance on realistic legal reasoning tasks. All benchmark data, training datasets, model weights, and evaluation code are released openly to support reproducible research in domain-specific legal artificial intelligence. A web-based demo of SteuerLLM is available at https://steuerllm.i5.ai.fau.de.
Semantic Interactive Learning for Text Classification: A Constructive Approach for Contextual Interactions
Sep 07, 2022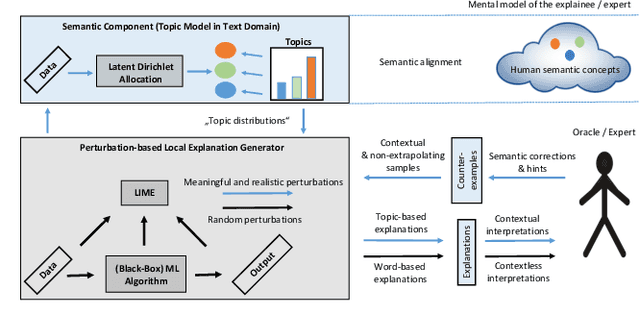
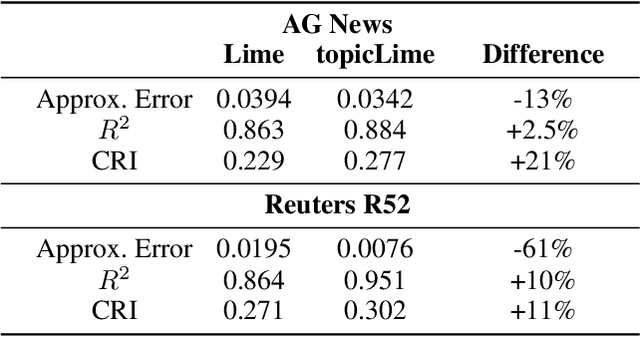
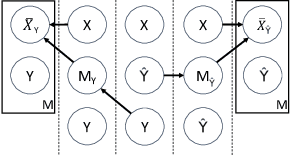
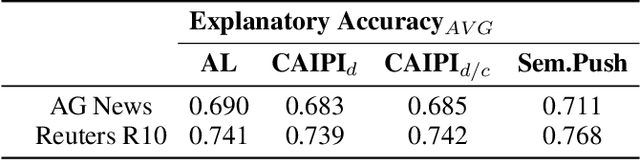
Interactive Machine Learning (IML) shall enable intelligent systems to interactively learn from their end-users, and is quickly becoming more and more important. Although it puts the human in the loop, interactions are mostly performed via mutual explanations that miss contextual information. Furthermore, current model-agnostic IML strategies like CAIPI are limited to 'destructive' feedback, meaning they solely allow an expert to prevent a learner from using irrelevant features. In this work, we propose a novel interaction framework called Semantic Interactive Learning for the text domain. We frame the problem of incorporating constructive and contextual feedback into the learner as a task to find an architecture that (a) enables more semantic alignment between humans and machines and (b) at the same time helps to maintain statistical characteristics of the input domain when generating user-defined counterexamples based on meaningful corrections. Therefore, we introduce a technique called SemanticPush that is effective for translating conceptual corrections of humans to non-extrapolating training examples such that the learner's reasoning is pushed towards the desired behavior. In several experiments, we show that our method clearly outperforms CAIPI, a state of the art IML strategy, in terms of Predictive Performance as well as Local Explanation Quality in downstream multi-class classification tasks.