 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Approximation for Bayesian Inference in Neural Networks
Nov 11, 2022



Bayesian inference has theoretical attractions as a principled framework for reasoning about beliefs. However, the motivations of Bayesian inference which claim it to be the only 'rational' kind of reasoning do not apply in practice. They create a binary split in which all approximate inference is equally 'irrational'. Instead, we should ask ourselves how to define a spectrum of more- and less-rational reasoning that explains why we might prefer one Bayesian approximation to another. I explore approximate inference in Bayesian neural networks and consider the unintended interactions between the probabilistic model, approximating distribution, optimization algorithm, and dataset. The complexity of these interactions highlights the difficulty of any strategy for evaluating Bayesian approximations which focuses entirely on the method, outside the context of specific datasets and decision-problems. For given applications, the expected utility of the approximate posterior can measure inference quality. To assess a model's ability to incorporate different parts of the Bayesian framework we can identify desirable characteristic behaviours of Bayesian reasoning and pick decision-problems that make heavy use of those behaviours. Here, we use continual learning (testing the ability to update sequentially) and active learning (testing the ability to represent credence). But existing continual and active learning set-ups pose challenges that have nothing to do with posterior quality which can distort their ability to evaluate Bayesian approximations. These unrelated challenges can be removed or reduced, allowing better evaluation of approximate inference methods.
Do Bayesian Neural Networks Need To Be Fully Stochastic?
Nov 11, 2022



We investigate the efficacy of treating all the parameters in a Bayesian neural network stochastically and find compelling theoretical and empirical evidence that this standard construction may be unnecessary. To this end, we prove that expressive predictive distributions require only small amounts of stochasticity. In particular, partially stochastic networks with only $n$ stochastic biases are universal probabilistic predictors for $n$-dimensional predictive problems. In empirical investigations, we find no systematic benefit of full stochasticity across four different inference modalities and eight datasets; partially stochastic networks can match and sometimes even outperform fully stochastic networks, despite their reduced memory costs.
Discovering Agents
Aug 24, 2022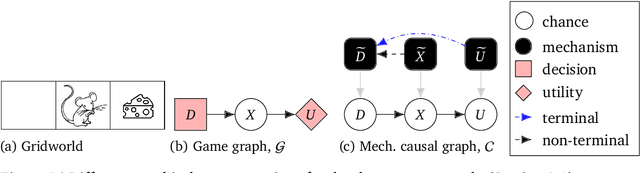
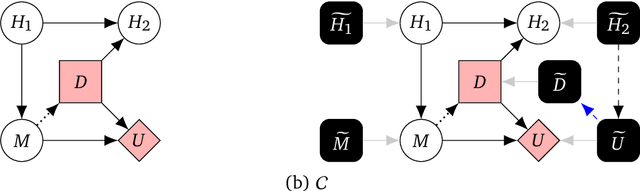
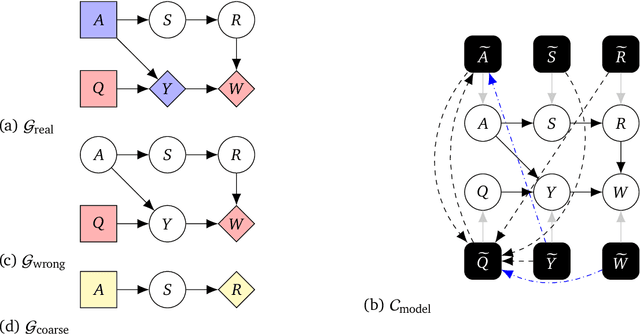
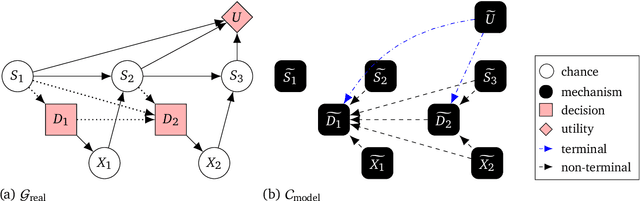
Causal models of agents have been used to analyse the safety aspects of machine learning systems. But identifying agents is non-trivial -- often the causal model is just assumed by the modeler without much justification -- and modelling failures can lead to mistakes in the safety analysis. This paper proposes the first formal causal definition of agents -- roughly that agents are systems that would adapt their policy if their actions influenced the world in a different way. From this we derive the first causal discovery algorithm for discovering agents from empirical data, and give algorithms for translating between causal models and game-theoretic influence diagrams. We demonstrate our approach by resolving some previous confusions caused by incorrect causal modelling of agents.
Prioritized Training on Points that are Learnable, Worth Learning, and Not Yet Learnt
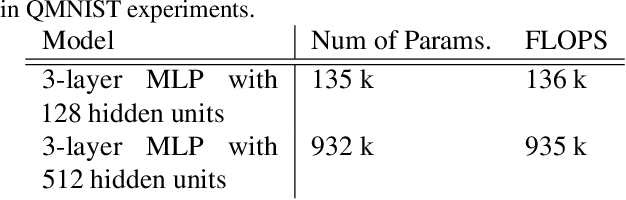
Jun 16, 2022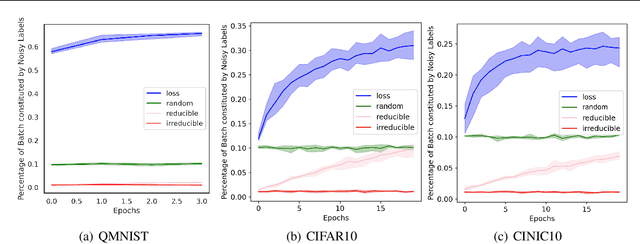
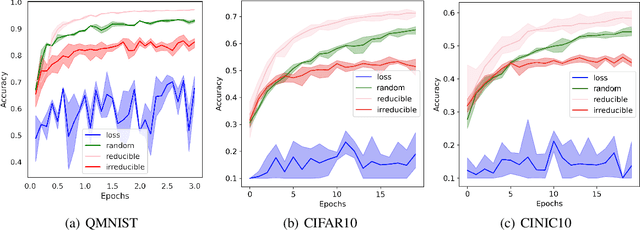
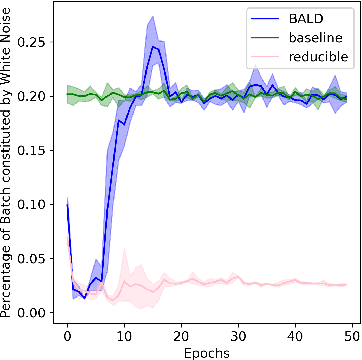
Training on web-scale data can take months. But most computation and time is wasted on redundant and noisy points that are already learnt or not learnable. To accelerate training, we introduce Reducible Holdout Loss Selection (RHO-LOSS), a simple but principled technique which selects approximately those points for training that most reduce the model's generalization loss. As a result, RHO-LOSS mitigates the weaknesses of existing data selection methods: techniques from the optimization literature typically select 'hard' (e.g. high loss) points, but such points are often noisy (not learnable) or less task-relevant. Conversely, curriculum learning prioritizes 'easy' points, but such points need not be trained on once learned. In contrast, RHO-LOSS selects points that are learnable, worth learning, and not yet learnt. RHO-LOSS trains in far fewer steps than prior art, improves accuracy, and speeds up training on a wide range of datasets, hyperparameters, and architectures (MLPs, CNNs, and BERT). On the large web-scraped image dataset Clothing-1M, RHO-LOSS trains in 18x fewer steps and reaches 2% higher final accuracy than uniform data shuffling.
Path-Specific Objectives for Safer Agent Incentives
Apr 21, 2022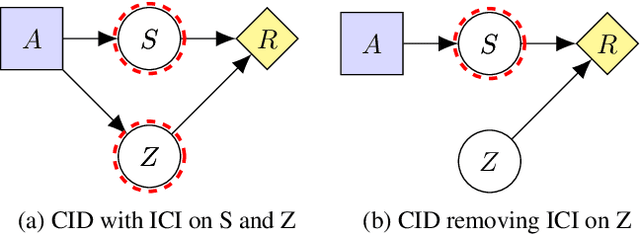

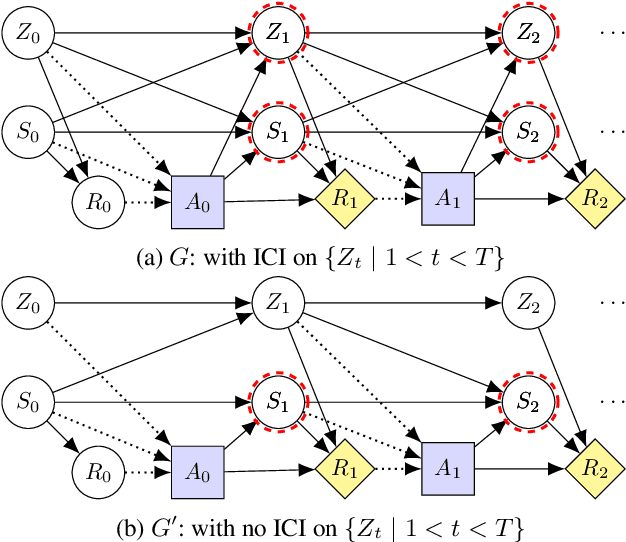
We present a general framework for training safe agents whose naive incentives are unsafe. As an example, manipulative or deceptive behaviour can improve rewards but should be avoided. Most approaches fail here: agents maximize expected return by any means necessary. We formally describe settings with 'delicate' parts of the state which should not be used as a means to an end. We then train agents to maximize the causal effect of actions on the expected return which is not mediated by the delicate parts of state, using Causal Influence Diagram analysis. The resulting agents have no incentive to control the delicate state. We further show how our framework unifies and generalizes existing proposals.
Prospect Pruning: Finding Trainable Weights at Initialization using Meta-Gradients
Feb 16, 2022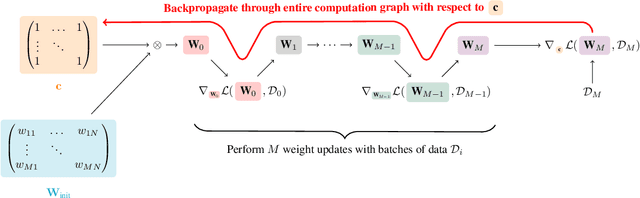
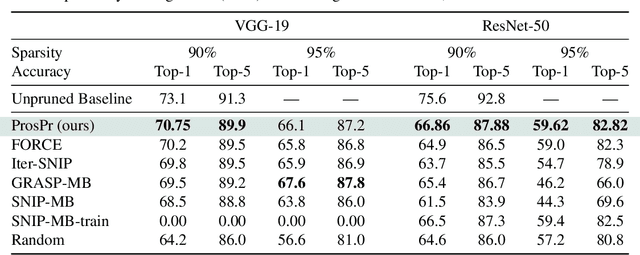
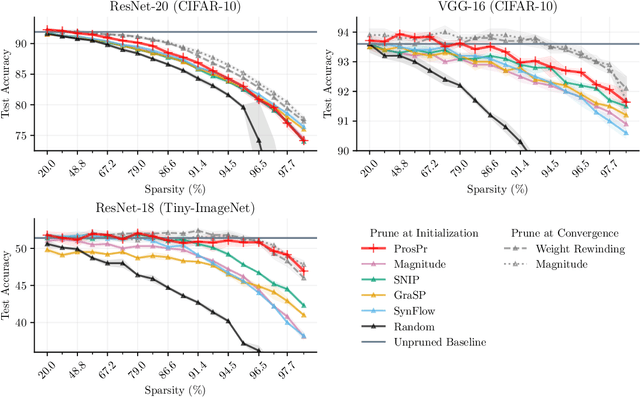
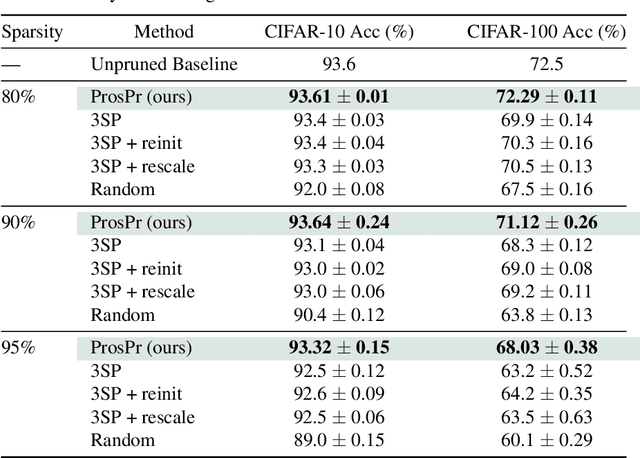
Pruning neural networks at initialization would enable us to find sparse models that retain the accuracy of the original network while consuming fewer computational resources for training and inference. However, current methods are insufficient to enable this optimization and lead to a large degradation in model performance. In this paper, we identify a fundamental limitation in the formulation of current methods, namely that their saliency criteria look at a single step at the start of training without taking into account the trainability of the network. While pruning iteratively and gradually has been shown to improve pruning performance, explicit consideration of the training stage that will immediately follow pruning has so far been absent from the computation of the saliency criterion. To overcome the short-sightedness of existing methods, we propose Prospect Pruning (ProsPr), which uses meta-gradients through the first few steps of optimization to determine which weights to prune. ProsPr combines an estimate of the higher-order effects of pruning on the loss and the optimization trajectory to identify the trainable sub-network. Our method achieves state-of-the-art pruning performance on a variety of vision classification tasks, with less data and in a single shot compared to existing pruning-at-initialization methods.
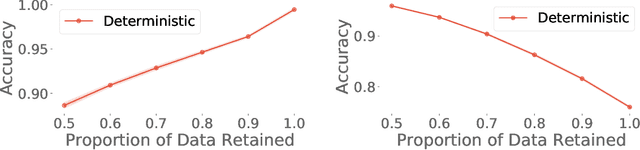
Active Surrogate Estimators: An Active Learning Approach to Label-Efficient Model Evaluation
Feb 14, 2022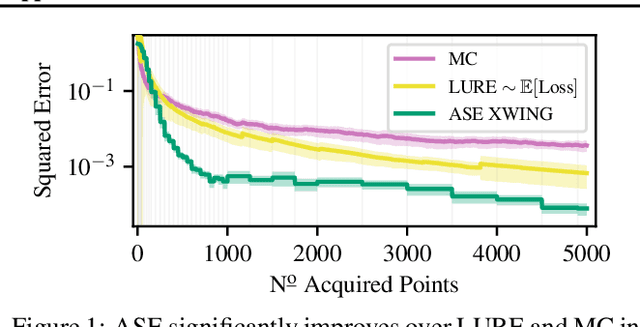
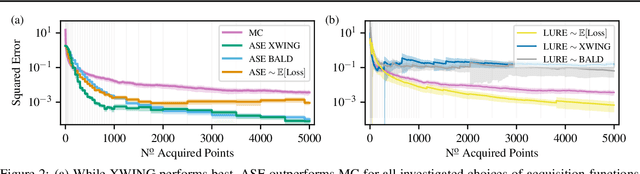
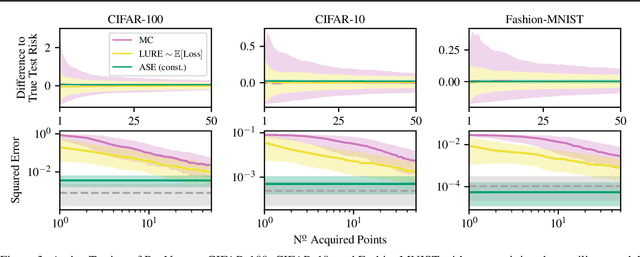
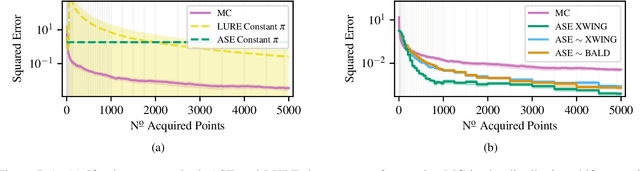
We propose Active Surrogate Estimators (ASEs), a new method for label-efficient model evaluation. Evaluating model performance is a challenging and important problem when labels are expensive. ASEs address this active testing problem using a surrogate-based estimation approach, whereas previous methods have focused on Monte Carlo estimates. ASEs actively learn the underlying surrogate, and we propose a novel acquisition strategy, XWING, that tailors this learning to the final estimation task. We find that ASEs offer greater label-efficiency than the current state-of-the-art when applied to challenging model evaluation problems for deep neural networks. We further theoretically analyze ASEs' errors.
Prioritized training on points that are learnable, worth learning, and not yet learned
Jul 06, 2021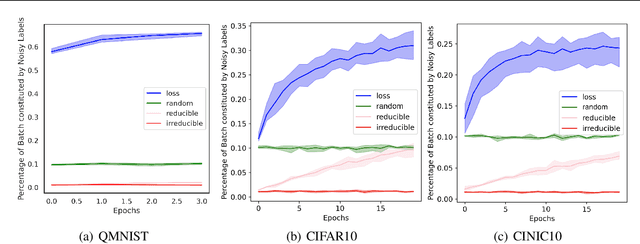
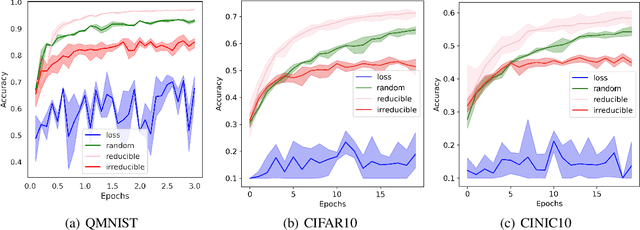
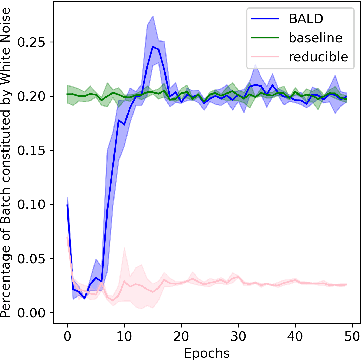
We introduce Goldilocks Selection, a technique for faster model training which selects a sequence of training points that are "just right". We propose an information-theoretic acquisition function -- the reducible validation loss -- and compute it with a small proxy model -- GoldiProx -- to efficiently choose training points that maximize information about a validation set. We show that the "hard" (e.g. high loss) points usually selected in the optimization literature are typically noisy, while the "easy" (e.g. low noise) samples often prioritized for curriculum learning confer less information. Further, points with uncertain labels, typically targeted by active learning, tend to be less relevant to the task. In contrast, Goldilocks Selection chooses points that are "just right" and empirically outperforms the above approaches. Moreover, the selected sequence can transfer to other architectures; practitioners can share and reuse it without the need to recreate it.
A Simple Baseline for Batch Active Learning with Stochastic Acquisition Functions
Jun 22, 2021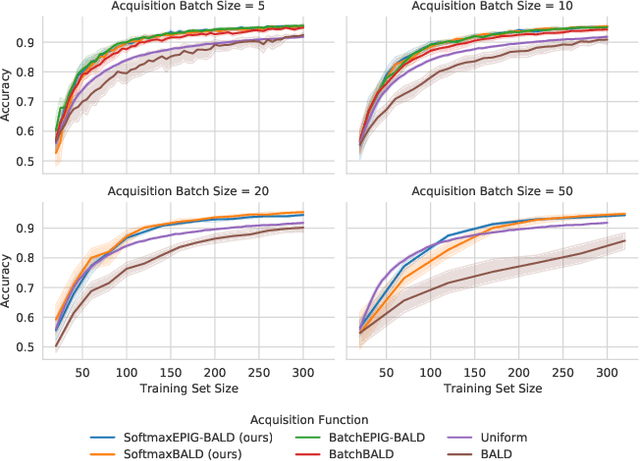
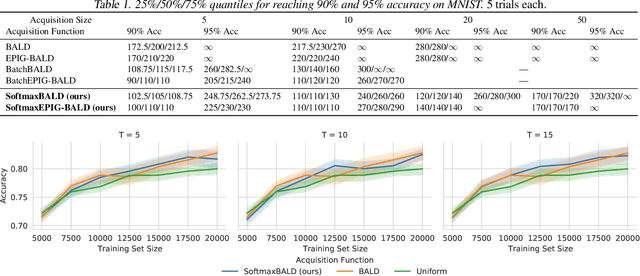
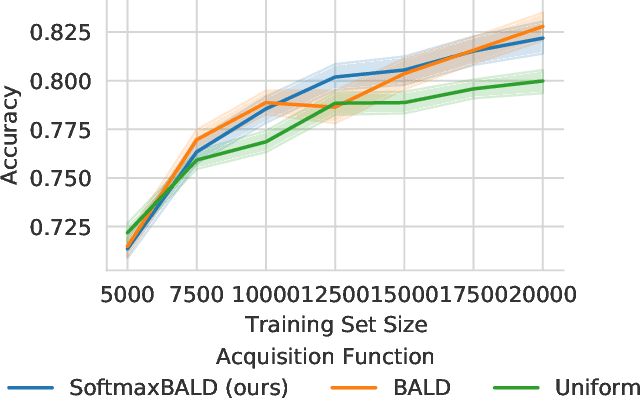
In active learning, new labels are commonly acquired in batches. However, common acquisition functions are only meant for one-sample acquisition rounds at a time, and when their scores are used naively for batch acquisition, they result in batches lacking diversity, which deteriorates performance. On the other hand, state-of-the-art batch acquisition functions are costly to compute. In this paper, we present a novel class of stochastic acquisition functions that extend one-sample acquisition functions to the batch setting by observing how one-sample acquisition scores change as additional samples are acquired and modelling this difference for additional batch samples. We simply acquire new samples by sampling from the pool set using a Gibbs distribution based on the acquisition scores. Our acquisition functions are both vastly cheaper to compute and out-perform other batch acquisition functions.
Uncertainty Baselines: Benchmarks for Uncertainty & Robustness in Deep Learning
Jun 07, 2021
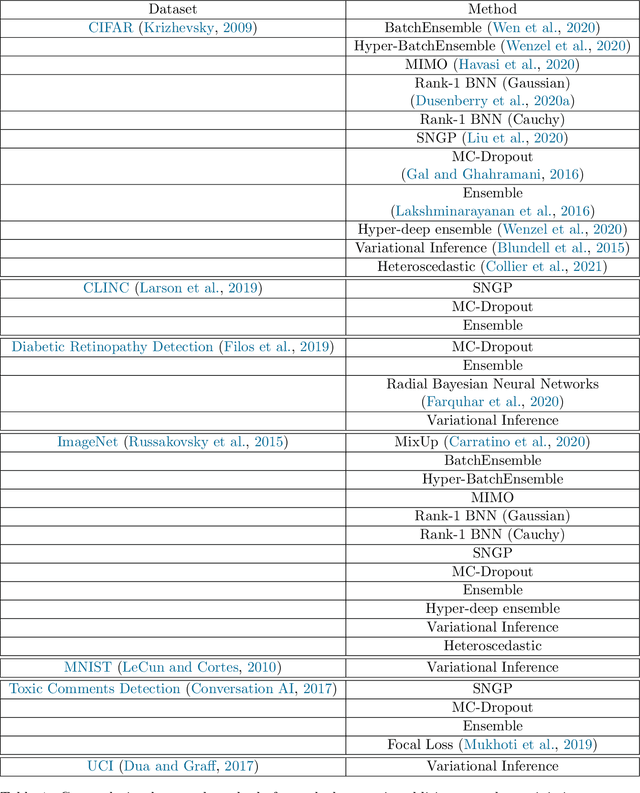
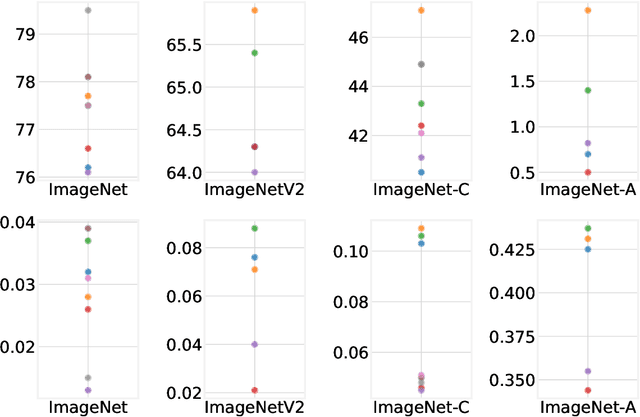
High-quality estimates of uncertainty and robustness are crucial for numerous real-world applications, especially for deep learning which underlies many deployed ML systems. The ability to compare techniques for improving these estimates is therefore very important for research and practice alike. Yet, competitive comparisons of methods are often lacking due to a range of reasons, including: compute availability for extensive tuning, incorporation of sufficiently many baselines, and concrete documentation for reproducibility. In this paper we introduce Uncertainty Baselines: high-quality implementations of standard and state-of-the-art deep learning methods on a variety of tasks. As of this writing, the collection spans 19 methods across 9 tasks, each with at least 5 metrics. Each baseline is a self-contained experiment pipeline with easily reusable and extendable components. Our goal is to provide immediate starting points for experimentation with new methods or applications. Additionally we provide model checkpoints, experiment outputs as Python notebooks, and leaderboards for comparing results. Code available at https://github.com/google/uncertainty-baselines.