 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Visuals Aren't the Problem: Evaluating Vision-Language Models on Misleading Data Visualizations
Mar 23, 2026Visualizations help communicate data insights, but deceptive data representations can distort their interpretation and propagate misinformation. While recent Vision Language Models (VLMs) perform well on many chart understanding tasks, their ability to detect misleading visualizations, especially when deception arises from subtle reasoning errors in captions, remains poorly understood. Here, we evaluate VLMs on misleading visualization-caption pairs grounded in a fine-grained taxonomy of reasoning errors (e.g., Cherry-picking, Causal inference) and visualization design errors (e.g., Truncated axis, Dual axis, inappropriate encodings). To this end, we develop a benchmark that combines real-world visualization with human-authored, curated misleading captions designed to elicit specific reasoning and visualization error types, enabling controlled analysis across error categories and modalities of misleadingness. Evaluating many commercial and open-source VLMs, we find that models detect visual design errors substantially more reliably than reasoning-based misinformation, and frequently misclassify non-misleading visualizations as deceptive. Overall, our work fills a gap between coarse detection of misleading content and the attribution of the specific reasoning or visualization errors that give rise to it.
Are More Tokens Rational? Inference-Time Scaling in Language Models as Adaptive Resource Rationality
Feb 10, 2026Human reasoning is shaped by resource rationality -- optimizing performance under constraints. Recently, inference-time scaling has emerged as a powerful paradigm to improve the reasoning performance of Large Language Models by expanding test-time computation. Specifically, instruction-tuned (IT) models explicitly generate long reasoning steps during inference, whereas Large Reasoning Models (LRMs) are trained by reinforcement learning to discover reasoning paths that maximize accuracy. However, it remains unclear whether resource-rationality can emerge from such scaling without explicit reward related to computational costs. We introduce a Variable Attribution Task in which models infer which variables determine outcomes given candidate variables, input-output trials, and predefined logical functions. By varying the number of candidate variables and trials, we systematically manipulate task complexity. Both models exhibit a transition from brute-force to analytic strategies as complexity increases. IT models degrade on XOR and XNOR functions, whereas LRMs remain robust. These findings suggest that models can adjust their reasoning behavior in response to task complexity, even without explicit cost-based reward. It provides compelling evidence that resource rationality is an emergent property of inference-time scaling itself.
The Representational Geometry of Number
Feb 06, 2026A central question in cognitive science is whether conceptual representations converge onto a shared manifold to support generalization, or diverge into orthogonal subspaces to minimize task interference. While prior work has discovered evidence for both, a mechanistic account of how these properties coexist and transform across tasks remains elusive. We propose that representational sharing lies not in the concepts themselves, but in the geometric relations between them. Using number concepts as a testbed and language models as high-dimensional computational substrates, we show that number representations preserve a stable relational structure across tasks. Task-specific representations are embedded in distinct subspaces, with low-level features like magnitude and parity encoded along separable linear directions. Crucially, we find that these subspaces are largely transformable into one another via linear mappings, indicating that representations share relational structure despite being located in distinct subspaces. Together, these results provide a mechanistic lens of how language models balance the shared structure of number representation with functional flexibility. It suggests that understanding arises when task-specific transformations are applied to a shared underlying relational structure of conceptual representations.
Computer Vision Modeling of the Development of Geometric and Numerical Concepts in Humans
Nov 19, 2025Mathematical thinking is a fundamental aspect of human cognition. Cognitive scientists have investigated the mechanisms that underlie our ability to thinking geometrically and numerically, to take two prominent examples, and developmental scientists have documented the trajectories of these abilities over the lifespan. Prior research has shown that computer vision (CV) models trained on the unrelated task of image classification nevertheless learn latent representations of geometric and numerical concepts similar to those of adults. Building on this demonstrated cognitive alignment, the current study investigates whether CV models also show developmental alignment: whether their performance improvements across training to match the developmental progressions observed in children. In a detailed case study of the ResNet-50 model, we show that this is the case. For the case of geometry and topology, we find developmental alignment for some classes of concepts (Euclidean Geometry, Geometrical Figures, Metric Properties, Topology) but not others (Chiral Figures, Geometric Transformations, Symmetrical Figures). For the case of number, we find developmental alignment in the emergence of a human-like ``mental number line'' representation with experience. These findings show the promise of computer vision models for understanding the development of mathematical understanding in humans. They point the way to future research exploring additional model architectures and building larger benchmarks.
* 11 pages, 7 figures
The World According to LLMs: How Geographic Origin Influences LLMs' Entity Deduction Capabilities
Aug 07, 2025Large Language Models (LLMs) have been extensively tuned to mitigate explicit biases, yet they often exhibit subtle implicit biases rooted in their pre-training data. Rather than directly probing LLMs with human-crafted questions that may trigger guardrails, we propose studying how models behave when they proactively ask questions themselves. The 20 Questions game, a multi-turn deduction task, serves as an ideal testbed for this purpose. We systematically evaluate geographic performance disparities in entity deduction using a new dataset, Geo20Q+, consisting of both notable people and culturally significant objects (e.g., foods, landmarks, animals) from diverse regions. We test popular LLMs across two gameplay configurations (canonical 20-question and unlimited turns) and in seven languages (English, Hindi, Mandarin, Japanese, French, Spanish, and Turkish). Our results reveal geographic disparities: LLMs are substantially more successful at deducing entities from the Global North than the Global South, and the Global West than the Global East. While Wikipedia pageviews and pre-training corpus frequency correlate mildly with performance, they fail to fully explain these disparities. Notably, the language in which the game is played has minimal impact on performance gaps. These findings demonstrate the value of creative, free-form evaluation frameworks for uncovering subtle biases in LLMs that remain hidden in standard prompting setups. By analyzing how models initiate and pursue reasoning goals over multiple turns, we find geographic and cultural disparities embedded in their reasoning processes. We release the dataset (Geo20Q+) and code at https://sites.google.com/view/llmbias20q/home.
A Neural Network Model of Complementary Learning Systems: Pattern Separation and Completion for Continual Learning
Jul 15, 2025Learning new information without forgetting prior knowledge is central to human intelligence. In contrast, neural network models suffer from catastrophic forgetting: a significant degradation in performance on previously learned tasks when acquiring new information. The Complementary Learning Systems (CLS) theory offers an explanation for this human ability, proposing that the brain has distinct systems for pattern separation (encoding distinct memories) and pattern completion (retrieving complete memories from partial cues). To capture these complementary functions, we leverage the representational generalization capabilities of variational autoencoders (VAEs) and the robust memory storage properties of Modern Hopfield networks (MHNs), combining them into a neurally plausible continual learning model. We evaluate this model on the Split-MNIST task, a popular continual learning benchmark, and achieve close to state-of-the-art accuracy (~90%), substantially reducing forgetting. Representational analyses empirically confirm the functional dissociation: the VAE underwrites pattern completion, while the MHN drives pattern separation. By capturing pattern separation and completion in scalable architectures, our work provides a functional template for modeling memory consolidation, generalization, and continual learning in both biological and artificial systems.
Computer Vision Models Show Human-Like Sensitivity to Geometric and Topological Concepts
May 19, 2025
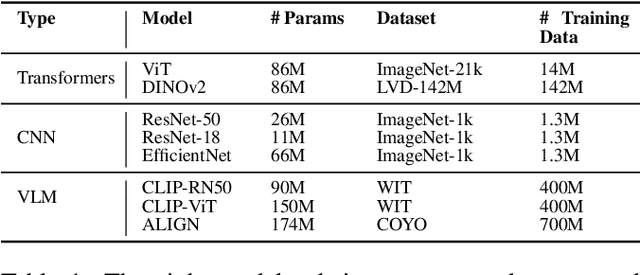
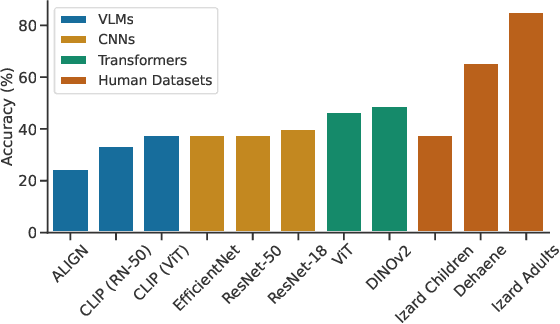
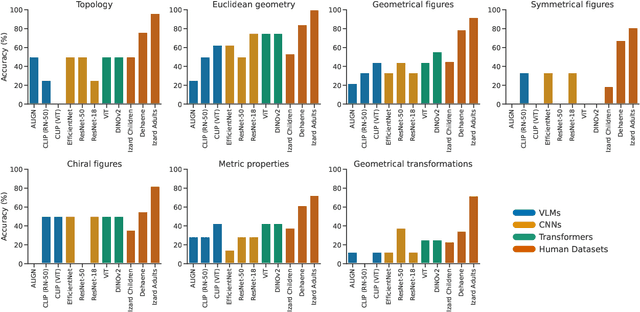
With the rapid improvement of machine learning (ML) models, cognitive scientists are increasingly asking about their alignment with how humans think. Here, we ask this question for computer vision models and human sensitivity to geometric and topological (GT) concepts. Under the core knowledge account, these concepts are innate and supported by dedicated neural circuitry. In this work, we investigate an alternative explanation, that GT concepts are learned ``for free'' through everyday interaction with the environment. We do so using computer visions models, which are trained on large image datasets. We build on prior studies to investigate the overall performance and human alignment of three classes of models -- convolutional neural networks (CNNs), transformer-based models, and vision-language models -- on an odd-one-out task testing 43 GT concepts spanning seven classes. Transformer-based models achieve the highest overall accuracy, surpassing that of young children. They also show strong alignment with children's performance, finding the same classes of concepts easy vs. difficult. By contrast, vision-language models underperform their vision-only counterparts and deviate further from human profiles, indicating that na\"ive multimodality might compromise abstract geometric sensitivity. These findings support the use of computer vision models to evaluate the sufficiency of the learning account for explaining human sensitivity to GT concepts, while also suggesting that integrating linguistic and visual representations might have unpredicted deleterious consequences.
* 10 pages, 4 figures, CosSci 2025
Understanding Graphical Perception in Data Visualization through Zero-shot Prompting of Vision-Language Models
Oct 31, 2024Vision Language Models (VLMs) have been successful at many chart comprehension tasks that require attending to both the images of charts and their accompanying textual descriptions. However, it is not well established how VLM performance profiles map to human-like behaviors. If VLMs can be shown to have human-like chart comprehension abilities, they can then be applied to a broader range of tasks, such as designing and evaluating visualizations for human readers. This paper lays the foundations for such applications by evaluating the accuracy of zero-shot prompting of VLMs on graphical perception tasks with established human performance profiles. Our findings reveal that VLMs perform similarly to humans under specific task and style combinations, suggesting that they have the potential to be used for modeling human performance. Additionally, variations to the input stimuli show that VLM accuracy is sensitive to stylistic changes such as fill color and chart contiguity, even when the underlying data and data mappings are the same.
Development of Cognitive Intelligence in Pre-trained Language Models
Jul 01, 2024Recent studies show evidence for emergent cognitive abilities in Large Pre-trained Language Models (PLMs). The increasing cognitive alignment of these models has made them candidates for cognitive science theories. Prior research into the emergent cognitive abilities of PLMs has largely been path-independent to model training, i.e., has focused on the final model weights and not the intermediate steps. However, building plausible models of human cognition using PLMs would benefit from considering the developmental alignment of their performance during training to the trajectories of children's thinking. Guided by psychometric tests of human intelligence, we choose four sets of tasks to investigate the alignment of ten popular families of PLMs and evaluate their available intermediate and final training steps. These tasks are Numerical ability, Linguistic abilities, Conceptual understanding, and Fluid reasoning. We find a striking regularity: regardless of model size, the developmental trajectories of PLMs consistently exhibit a window of maximal alignment to human cognitive development. Before that window, training appears to endow "blank slate" models with the requisite structure to be poised to rapidly learn from experience. After that window, training appears to serve the engineering goal of reducing loss but not the scientific goal of increasing alignment with human cognition.
Incremental Comprehension of Garden-Path Sentences by Large Language Models: Semantic Interpretation, Syntactic Re-Analysis, and Attention
May 25, 2024



When reading temporarily ambiguous garden-path sentences, misinterpretations sometimes linger past the point of disambiguation. This phenomenon has traditionally been studied in psycholinguistic experiments using online measures such as reading times and offline measures such as comprehension questions. Here, we investigate the processing of garden-path sentences and the fate of lingering misinterpretations using four large language models (LLMs): GPT-2, LLaMA-2, Flan-T5, and RoBERTa. The overall goal is to evaluate whether humans and LLMs are aligned in their processing of garden-path sentences and in the lingering misinterpretations past the point of disambiguation, especially when extra-syntactic information (e.g., a comma delimiting a clause boundary) is present to guide processing. We address this goal using 24 garden-path sentences that have optional transitive and reflexive verbs leading to temporary ambiguities. For each sentence, there are a pair of comprehension questions corresponding to the misinterpretation and the correct interpretation. In three experiments, we (1) measure the dynamic semantic interpretations of LLMs using the question-answering task; (2) track whether these models shift their implicit parse tree at the point of disambiguation (or by the end of the sentence); and (3) visualize the model components that attend to disambiguating information when processing the question probes. These experiments show promising alignment between humans and LLMs in the processing of garden-path sentences, especially when extra-syntactic information is available to guide processing.