 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoubly-stochastic mining for heterogeneous retrieval
Apr 23, 2020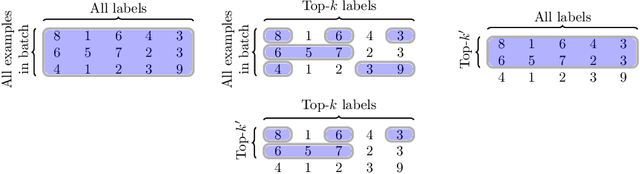


Modern retrieval problems are characterised by training sets with potentially billions of labels, and heterogeneous data distributions across subpopulations (e.g., users of a retrieval system may be from different countries), each of which poses a challenge. The first challenge concerns scalability: with a large number of labels, standard losses are difficult to optimise even on a single example. The second challenge concerns uniformity: one ideally wants good performance on each subpopulation. While several solutions have been proposed to address the first challenge, the second challenge has received relatively less attention. In this paper, we propose doubly-stochastic mining (S2M ), a stochastic optimization technique that addresses both challenges. In each iteration of S2M, we compute a per-example loss based on a subset of hardest labels, and then compute the minibatch loss based on the hardest examples. We show theoretically and empirically that by focusing on the hardest examples, S2M ensures that all data subpopulations are modelled well.
Low-Rank Bottleneck in Multi-head Attention Models
Feb 17, 2020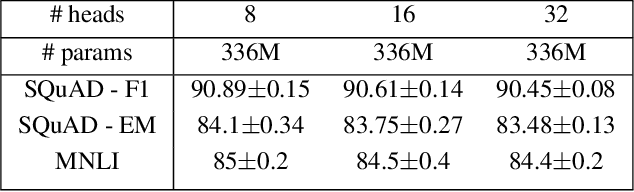
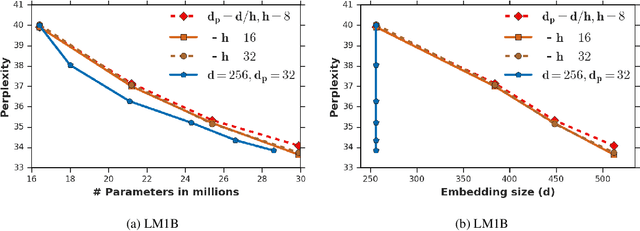
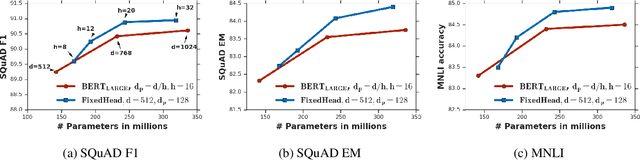
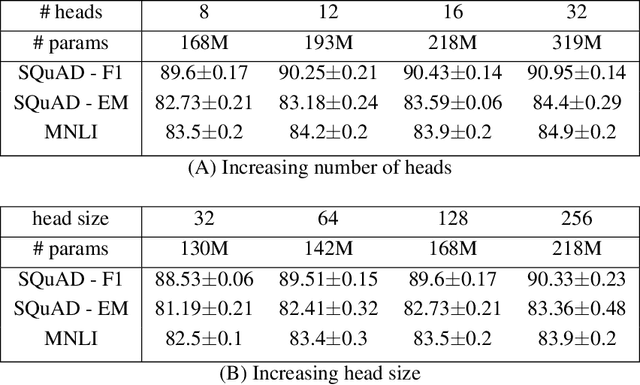
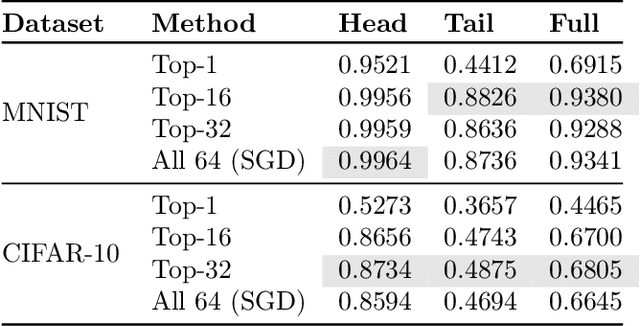
Attention based Transformer architecture has enabled significant advances in the field of natural language processing. In addition to new pre-training techniques, recent improvements crucially rely on working with a relatively larger embedding dimension for tokens. Unfortunately, this leads to models that are prohibitively large to be employed in the downstream tasks. In this paper we identify one of the important factors contributing to the large embedding size requirement. In particular, our analysis highlights that the scaling between the number of heads and the size of each head in the current architecture gives rise to a low-rank bottleneck in attention heads, causing this limitation. We further validate this in our experiments. As a solution we propose to set the head size of an attention unit to input sequence length, and independent of the number of heads, resulting in multi-head attention layers with provably more expressive power. We empirically show that this allows us to train models with a relatively smaller embedding dimension and with better performance scaling.
Are Transformers universal approximators of sequence-to-sequence functions?
Dec 20, 2019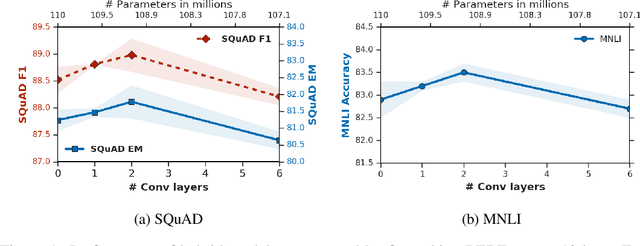

Despite the widespread adoption of Transformer models for NLP tasks, the expressive power of these models is not well-understood. In this paper, we establish that Transformer models are universal approximators of continuous permutation equivariant sequence-to-sequence functions with compact support, which is quite surprising given the amount of shared parameters in these models. Furthermore, using positional encodings, we circumvent the restriction of permutation equivariance, and show that Transformer models can universally approximate arbitrary continuous sequence-to-sequence functions on a compact domain. Interestingly, our proof techniques clearly highlight the different roles of the self-attention and the feed-forward layers in Transformers. In particular, we prove that fixed width self-attention layers can compute contextual mappings of the input sequences, playing a key role in the universal approximation property of Transformers. Based on this insight from our analysis, we consider other simpler alternatives to self-attention layers and empirically evaluate them.
SCAFFOLD: Stochastic Controlled Averaging for On-Device Federated Learning
Oct 14, 2019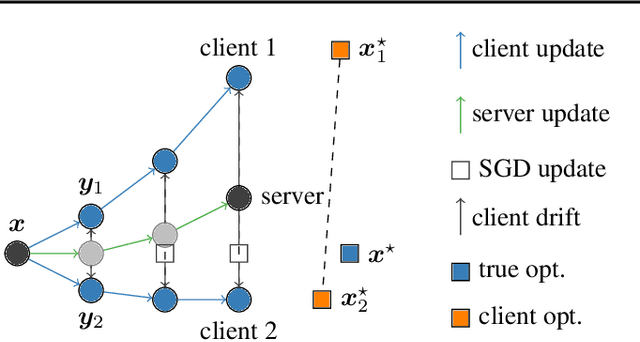
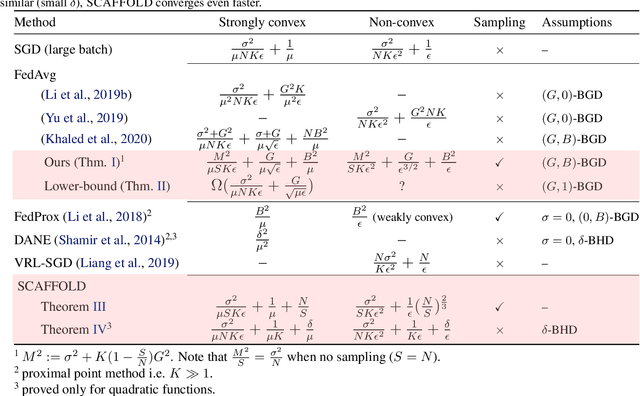
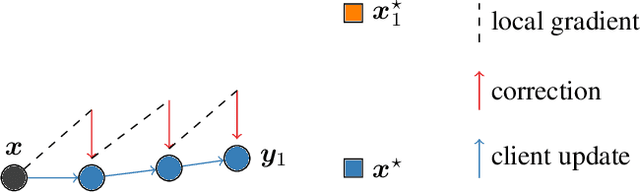
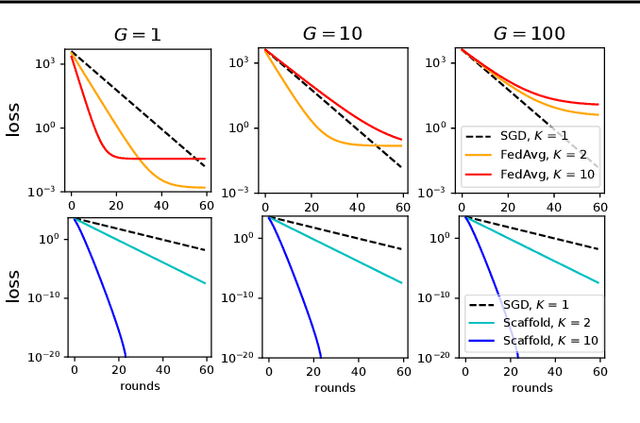
Federated learning is a key scenario in modern large-scale machine learning. In that scenario, the training data remains distributed over a large number of clients, which may be phones, other mobile devices, or network sensors and a centralized model is learned without ever transmitting client data over the network. The standard optimization algorithm used in this scenario is Federated Averaging (FedAvg). However, when client data is heterogeneous, which is typical in applications, FedAvg does not admit a favorable convergence guarantee. This is because local updates on clients can drift apart, which also explains the slow convergence and hard-to-tune nature of FedAvg in practice. This paper presents a new Stochastic Controlled Averaging algorithm (SCAFFOLD) which uses control variates to reduce the drift between different clients. We prove that the algorithm requires significantly fewer rounds of communication and benefits from favorable convergence guarantees.
AdaCliP: Adaptive Clipping for Private SGD
Aug 20, 2019
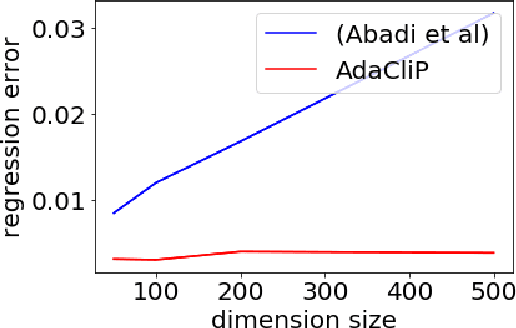
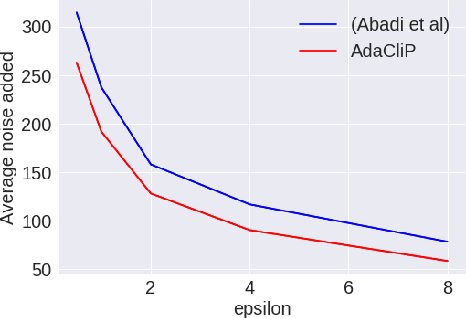

Privacy preserving machine learning algorithms are crucial for learning models over user data to protect sensitive information. Motivated by this, differentially private stochastic gradient descent (SGD) algorithms for training machine learning models have been proposed. At each step, these algorithms modify the gradients and add noise proportional to the sensitivity of the modified gradients. Under this framework, we propose AdaCliP, a theoretically motivated differentially private SGD algorithm that provably adds less noise compared to the previous methods, by using coordinate-wise adaptive clipping of the gradient. We empirically demonstrate that AdaCliP reduces the amount of added noise and produces models with better accuracy.
On the Convergence of Adam and Beyond
Apr 19, 2019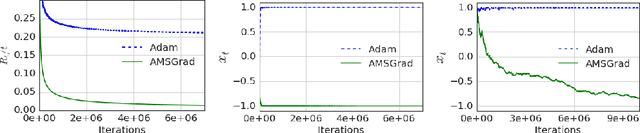
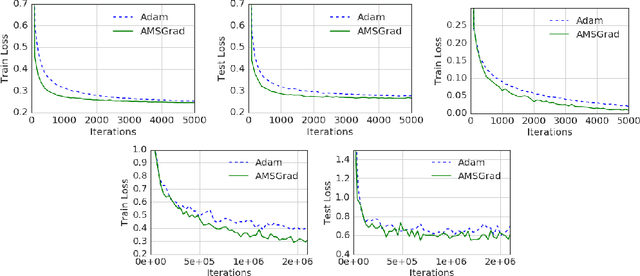
Several recently proposed stochastic optimization methods that have been successfully used in training deep networks such as RMSProp, Adam, Adadelta, Nadam are based on using gradient updates scaled by square roots of exponential moving averages of squared past gradients. In many applications, e.g. learning with large output spaces, it has been empirically observed that these algorithms fail to converge to an optimal solution (or a critical point in nonconvex settings). We show that one cause for such failures is the exponential moving average used in the algorithms. We provide an explicit example of a simple convex optimization setting where Adam does not converge to the optimal solution, and describe the precise problems with the previous analysis of Adam algorithm. Our analysis suggests that the convergence issues can be fixed by endowing such algorithms with `long-term memory' of past gradients, and propose new variants of the Adam algorithm which not only fix the convergence issues but often also lead to improved empirical performance.
Escaping Saddle Points with Adaptive Gradient Methods
Jan 26, 2019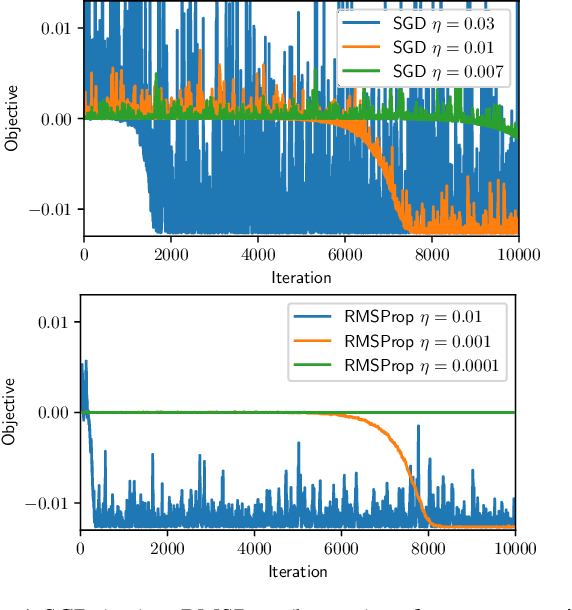
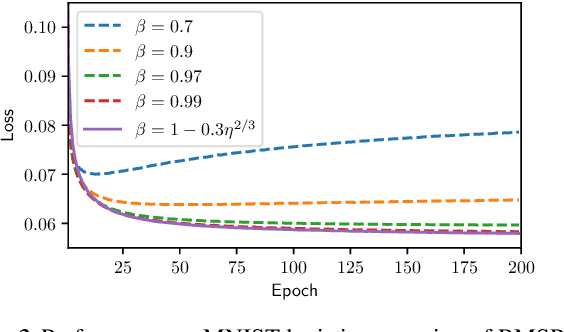
Adaptive methods such as Adam and RMSProp are widely used in deep learning but are not well understood. In this paper, we seek a crisp, clean and precise characterization of their behavior in nonconvex settings. To this end, we first provide a novel view of adaptive methods as preconditioned SGD, where the preconditioner is estimated in an online manner. By studying the preconditioner on its own, we elucidate its purpose: it rescales the stochastic gradient noise to be isotropic near stationary points, which helps escape saddle points. Furthermore, we show that adaptive methods can efficiently estimate the aforementioned preconditioner. By gluing together these two components, we provide the first (to our knowledge) second-order convergence result for any adaptive method. The key insight from our analysis is that, compared to SGD, adaptive methods escape saddle points faster, and can converge faster overall to second-order stationary points.
Stochastic Negative Mining for Learning with Large Output Spaces
Oct 16, 2018
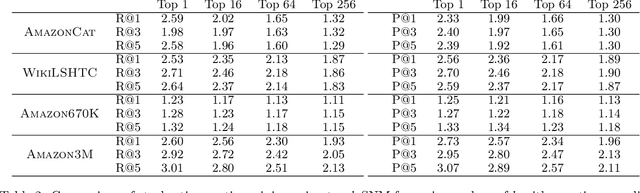
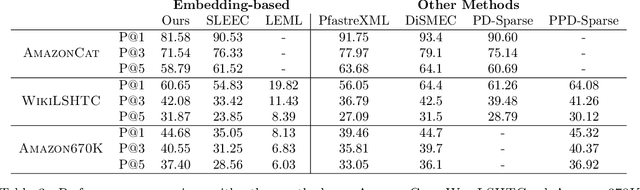
We consider the problem of retrieving the most relevant labels for a given input when the size of the output space is very large. Retrieval methods are modeled as set-valued classifiers which output a small set of classes for each input, and a mistake is made if the label is not in the output set. Despite its practical importance, a statistically principled, yet practical solution to this problem is largely missing. To this end, we first define a family of surrogate losses and show that they are calibrated and convex under certain conditions on the loss parameters and data distribution, thereby establishing a statistical and analytical basis for using these losses. Furthermore, we identify a particularly intuitive class of loss functions in the aforementioned family and show that they are amenable to practical implementation in the large output space setting (i.e. computation is possible without evaluating scores of all labels) by developing a technique called Stochastic Negative Mining. We also provide generalization error bounds for the losses in the family. Finally, we conduct experiments which demonstrate that Stochastic Negative Mining yields benefits over commonly used negative sampling approaches.
Riemannian SVRG: Fast Stochastic Optimization on Riemannian Manifolds
Apr 07, 2017
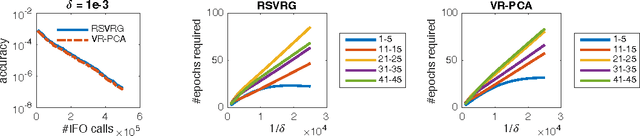

We study optimization of finite sums of geodesically smooth functions on Riemannian manifolds. Although variance reduction techniques for optimizing finite-sums have witnessed tremendous attention in the recent years, existing work is limited to vector space problems. We introduce Riemannian SVRG (RSVRG), a new variance reduced Riemannian optimization method. We analyze RSVRG for both geodesically convex and nonconvex (smooth) functions. Our analysis reveals that RSVRG inherits advantages of the usual SVRG method, but with factors depending on curvature of the manifold that influence its convergence. To our knowledge, RSVRG is the first provably fast stochastic Riemannian method. Moreover, our paper presents the first non-asymptotic complexity analysis (novel even for the batch setting) for nonconvex Riemannian optimization. Our results have several implications; for instance, they offer a Riemannian perspective on variance reduced PCA, which promises a short, transparent convergence analysis.
* This is the final version that appeared in NIPS 2016. Our proof of Lemma 2 was incorrect in the previous arXiv version. (9 pages paper + 6 pages appendix)
AIDE: Fast and Communication Efficient Distributed Optimization
Aug 24, 2016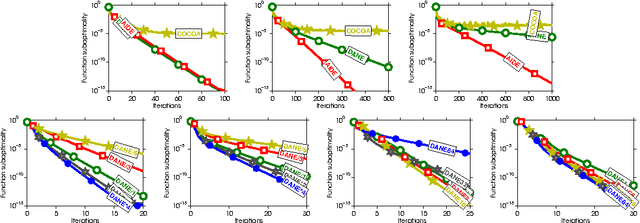
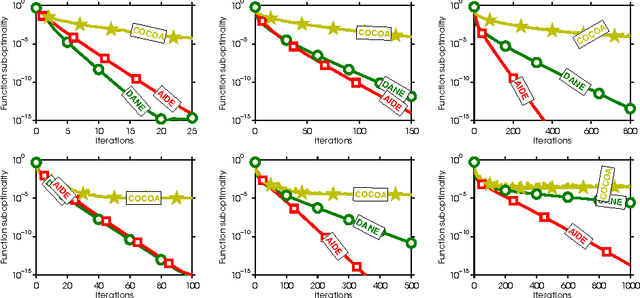
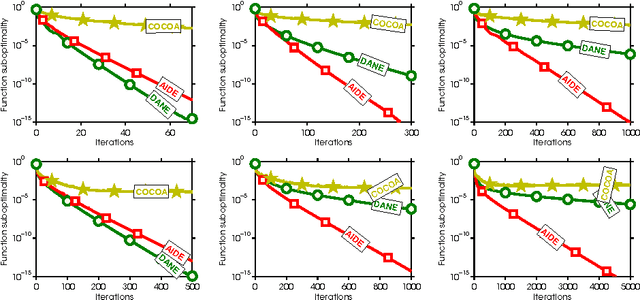
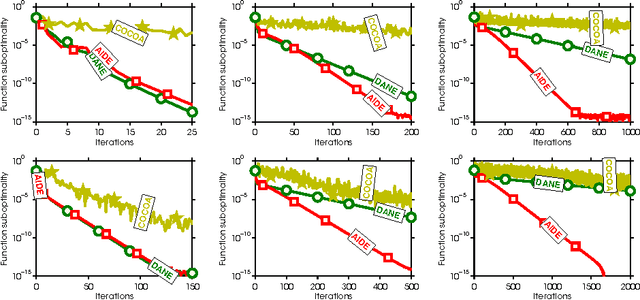
In this paper, we present two new communication-efficient methods for distributed minimization of an average of functions. The first algorithm is an inexact variant of the DANE algorithm that allows any local algorithm to return an approximate solution to a local subproblem. We show that such a strategy does not affect the theoretical guarantees of DANE significantly. In fact, our approach can be viewed as a robustification strategy since the method is substantially better behaved than DANE on data partition arising in practice. It is well known that DANE algorithm does not match the communication complexity lower bounds. To bridge this gap, we propose an accelerated variant of the first method, called AIDE, that not only matches the communication lower bounds but can also be implemented using a purely first-order oracle. Our empirical results show that AIDE is superior to other communication efficient algorithms in settings that naturally arise in machine learning applications.