 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategic Communication under Threat: Learning Information Trade-offs in Pursuit-Evasion Games
Oct 09, 2025


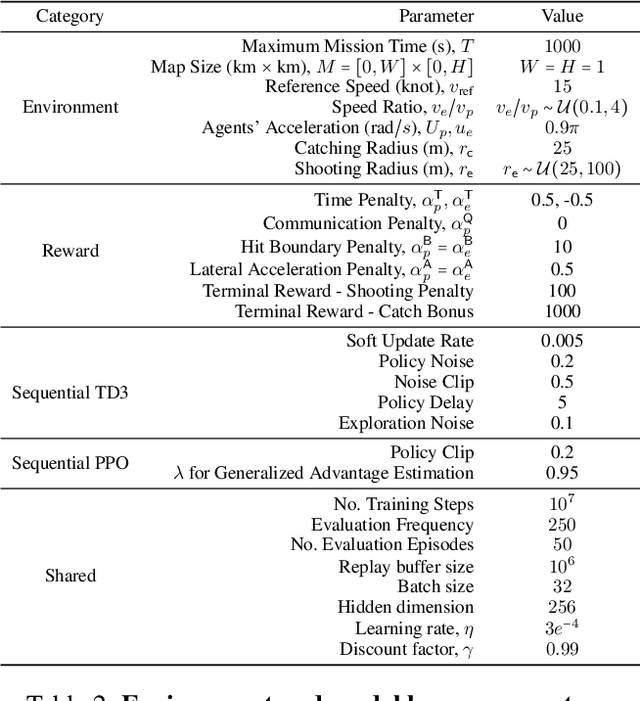
Adversarial environments require agents to navigate a key strategic trade-off: acquiring information enhances situational awareness, but may simultaneously expose them to threats. To investigate this tension, we formulate a PursuitEvasion-Exposure-Concealment Game (PEEC) in which a pursuer agent must decide when to communicate in order to obtain the evader's position. Each communication reveals the pursuer's location, increasing the risk of being targeted. Both agents learn their movement policies via reinforcement learning, while the pursuer additionally learns a communication policy that balances observability and risk. We propose SHADOW (Strategic-communication Hybrid Action Decision-making under partial Observation for Warfare), a multi-headed sequential reinforcement learning framework that integrates continuous navigation control, discrete communication actions, and opponent modeling for behavior prediction. Empirical evaluations show that SHADOW pursuers achieve higher success rates than six competitive baselines. Our ablation study confirms that temporal sequence modeling and opponent modeling are critical for effective decision-making. Finally, our sensitivity analysis reveals that the learned policies generalize well across varying communication risks and physical asymmetries between agents.
Automating AI Failure Tracking: Semantic Association of Reports in AI Incident Database
Jul 31, 2025



Artificial Intelligence (AI) systems are transforming critical sectors such as healthcare, finance, and transportation, enhancing operational efficiency and decision-making processes. However, their deployment in high-stakes domains has exposed vulnerabilities that can result in significant societal harm. To systematically study and mitigate these risk, initiatives like the AI Incident Database (AIID) have emerged, cataloging over 3,000 real-world AI failure reports. Currently, associating a new report with the appropriate AI Incident relies on manual expert intervention, limiting scalability and delaying the identification of emerging failure patterns. To address this limitation, we propose a retrieval-based framework that automates the association of new reports with existing AI Incidents through semantic similarity modeling. We formalize the task as a ranking problem, where each report-comprising a title and a full textual description-is compared to previously documented AI Incidents based on embedding cosine similarity. Benchmarking traditional lexical methods, cross-encoder architectures, and transformer-based sentence embedding models, we find that the latter consistently achieve superior performance. Our analysis further shows that combining titles and descriptions yields substantial improvements in ranking accuracy compared to using titles alone. Moreover, retrieval performance remains stable across variations in description length, highlighting the robustness of the framework. Finally, we find that retrieval performance consistently improves as the training set expands. Our approach provides a scalable and efficient solution for supporting the maintenance of the AIID.
Assessing the Potential of Generative Agents in Crowdsourced Fact-Checking
Apr 24, 2025



The growing spread of online misinformation has created an urgent need for scalable, reliable fact-checking solutions. Crowdsourced fact-checking - where non-experts evaluate claim veracity - offers a cost-effective alternative to expert verification, despite concerns about variability in quality and bias. Encouraged by promising results in certain contexts, major platforms such as X (formerly Twitter), Facebook, and Instagram have begun shifting from centralized moderation to decentralized, crowd-based approaches. In parallel, advances in Large Language Models (LLMs) have shown strong performance across core fact-checking tasks, including claim detection and evidence evaluation. However, their potential role in crowdsourced workflows remains unexplored. This paper investigates whether LLM-powered generative agents - autonomous entities that emulate human behavior and decision-making - can meaningfully contribute to fact-checking tasks traditionally reserved for human crowds. Using the protocol of La Barbera et al. (2024), we simulate crowds of generative agents with diverse demographic and ideological profiles. Agents retrieve evidence, assess claims along multiple quality dimensions, and issue final veracity judgments. Our results show that agent crowds outperform human crowds in truthfulness classification, exhibit higher internal consistency, and show reduced susceptibility to social and cognitive biases. Compared to humans, agents rely more systematically on informative criteria such as Accuracy, Precision, and Informativeness, suggesting a more structured decision-making process. Overall, our findings highlight the potential of generative agents as scalable, consistent, and less biased contributors to crowd-based fact-checking systems.
Few-shot Named Entity Recognition with Cloze Questions
Nov 24, 2021


Despite the huge and continuous advances in computational linguistics, the lack of annotated data for Named Entity Recognition (NER) is still a challenging issue, especially in low-resource languages and when domain knowledge is required for high-quality annotations. Recent findings in NLP show the effectiveness of cloze-style questions in enabling language models to leverage the knowledge they acquired during the pre-training phase. In our work, we propose a simple and intuitive adaptation of Pattern-Exploiting Training (PET), a recent approach which combines the cloze-questions mechanism and fine-tuning for few-shot learning: the key idea is to rephrase the NER task with patterns. Our approach achieves considerably better performance than standard fine-tuning and comparable or improved results with respect to other few-shot baselines without relying on manually annotated data or distant supervision on three benchmark datasets: NCBI-disease, BC2GM and a private Italian biomedical corpus.