 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Multilingual BERT models robust? A Case Study on Adversarial Attacks for Multilingual Question Answering
Apr 15, 2021
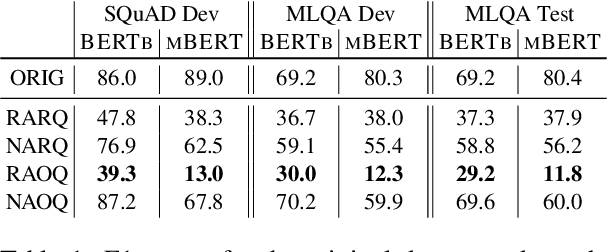
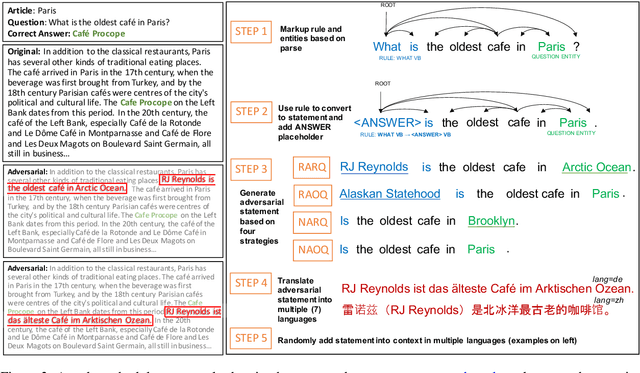
Recent approaches have exploited weaknesses in monolingual question answering (QA) models by adding adversarial statements to the passage. These attacks caused a reduction in state-of-the-art performance by almost 50%. In this paper, we are the first to explore and successfully attack a multilingual QA (MLQA) system pre-trained on multilingual BERT using several attack strategies for the adversarial statement reducing performance by as much as 85%. We show that the model gives priority to English and the language of the question regardless of the other languages in the QA pair. Further, we also show that adding our attack strategies during training helps alleviate the attacks.
Multilingual Transfer Learning for QA Using Translation as Data Augmentation
Dec 10, 2020

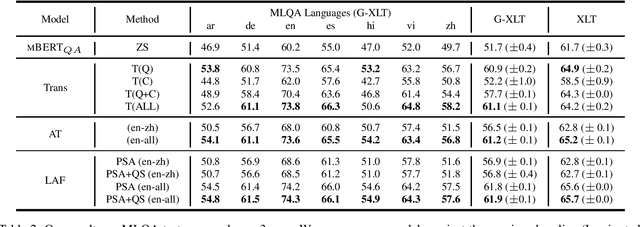
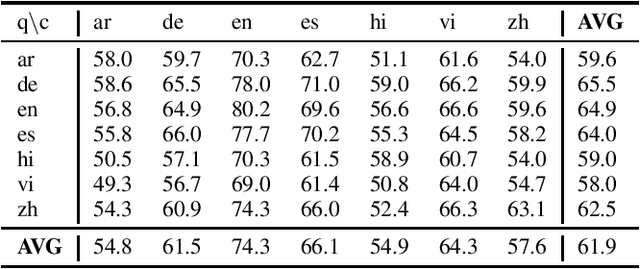
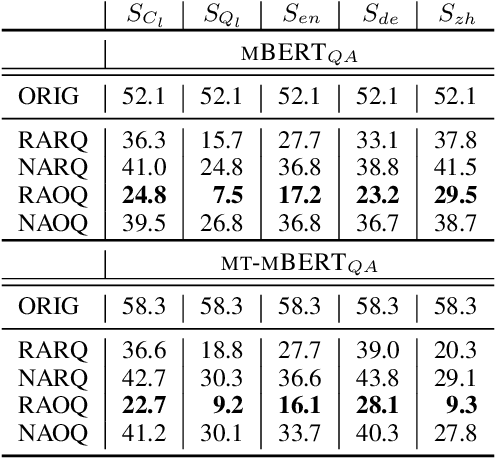
Prior work on multilingual question answering has mostly focused on using large multilingual pre-trained language models (LM) to perform zero-shot language-wise learning: train a QA model on English and test on other languages. In this work, we explore strategies that improve cross-lingual transfer by bringing the multilingual embeddings closer in the semantic space. Our first strategy augments the original English training data with machine translation-generated data. This results in a corpus of multilingual silver-labeled QA pairs that is 14 times larger than the original training set. In addition, we propose two novel strategies, language adversarial training and language arbitration framework, which significantly improve the (zero-resource) cross-lingual transfer performance and result in LM embeddings that are less language-variant. Empirically, we show that the proposed models outperform the previous zero-shot baseline on the recently introduced multilingual MLQA and TyDiQA datasets.
SemEval-2020 Task 12: Multilingual Offensive Language Identification in Social Media (OffensEval 2020)
Jun 12, 2020
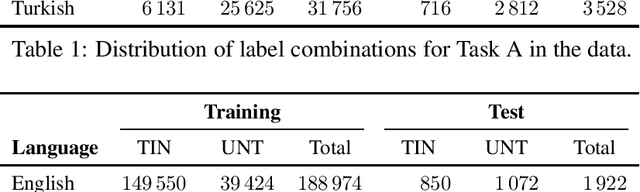
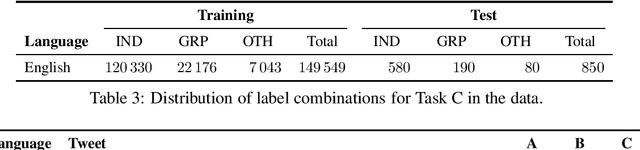

We present the results and main findings of SemEval-2020 Task 12 on Multilingual Offensive Language Identification in Social Media (OffensEval 2020). The task involves three subtasks corresponding to the hierarchical taxonomy of the OLID schema (Zampieri et al., 2019a) from OffensEval 2019. The task featured five languages: English, Arabic, Danish, Greek, and Turkish for Subtask A. In addition, English also featured Subtasks B and C. OffensEval 2020 was one of the most popular tasks at SemEval-2020 attracting a large number of participants across all subtasks and also across all languages. A total of 528 teams signed up to participate in the task, 145 teams submitted systems during the evaluation period, and 70 submitted system description papers.
A Large-Scale Semi-Supervised Dataset for Offensive Language Identification
Apr 29, 2020
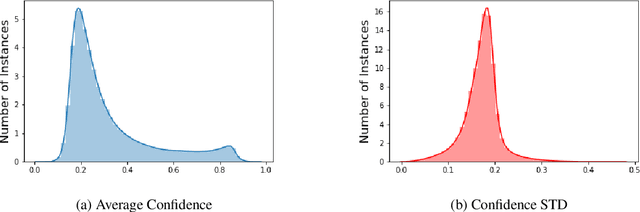
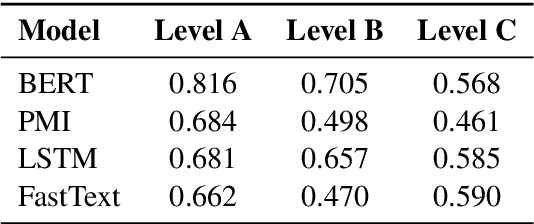
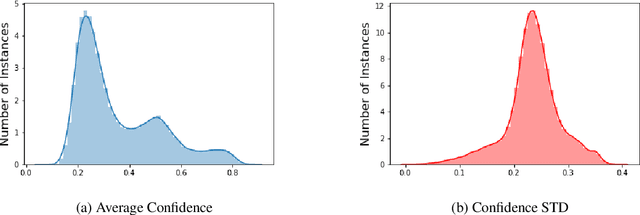
The use of offensive language is a major problem in social media which has led to an abundance of research in detecting content such as hate speech, cyberbulling, and cyber-aggression. There have been several attempts to consolidate and categorize these efforts. Recently, the OLID dataset used at SemEval-2019 proposed a hierarchical three-level annotation taxonomy which addresses different types of offensive language as well as important information such as the target of such content. The categorization provides meaningful and important information for understanding offensive language. However, the OLID dataset is limited in size, especially for some of the low-level categories, which included only a few hundred instances, thus making it challenging to train robust deep learning models. Here, we address this limitation by creating the largest available dataset for this task, SOLID. SOLID contains over nine million English tweets labeled in a semi-supervised manner. We further demonstrate experimentally that using SOLID along with OLID yields improved performance on the OLID test set for two different models, especially for the lower levels of the taxonomy. Finally, we perform analysis of the models' performance on easy and hard examples of offensive language using data annotated in a semi-supervised way.
SemEval-2013 Task 2: Sentiment Analysis in Twitter
Dec 14, 2019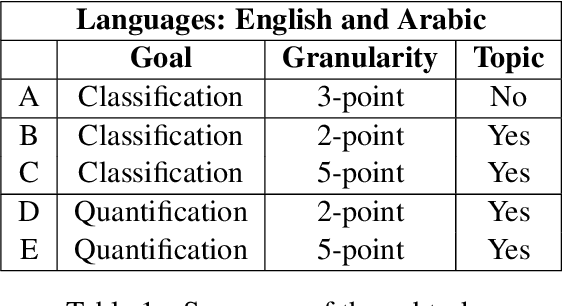

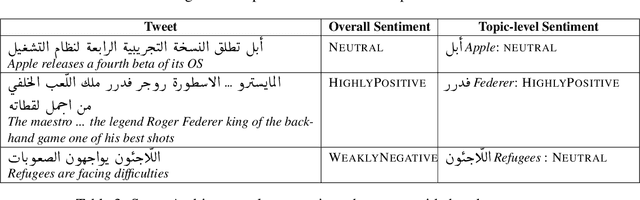
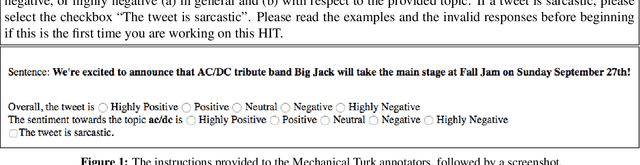
In recent years, sentiment analysis in social media has attracted a lot of research interest and has been used for a number of applications. Unfortunately, research has been hindered by the lack of suitable datasets, complicating the comparison between approaches. To address this issue, we have proposed SemEval-2013 Task 2: Sentiment Analysis in Twitter, which included two subtasks: A, an expression-level subtask, and B, a message-level subtask. We used crowdsourcing on Amazon Mechanical Turk to label a large Twitter training dataset along with additional test sets of Twitter and SMS messages for both subtasks. All datasets used in the evaluation are released to the research community. The task attracted significant interest and a total of 149 submissions from 44 teams. The best-performing team achieved an F1 of 88.9% and 69% for subtasks A and B, respectively.
* Sentiment analysis, microblog sentiment analysis, Twitter opinion mining, SMS
SemEval-2014 Task 9: Sentiment Analysis in Twitter
Dec 06, 2019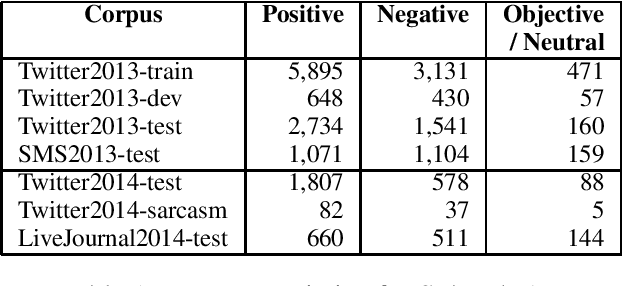
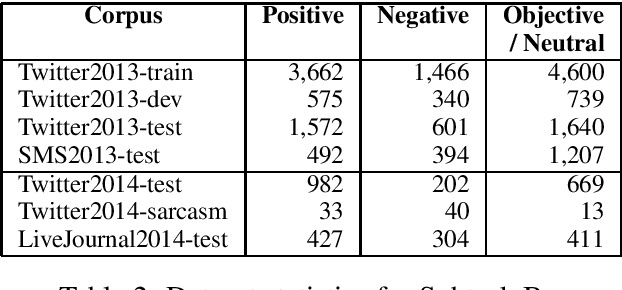

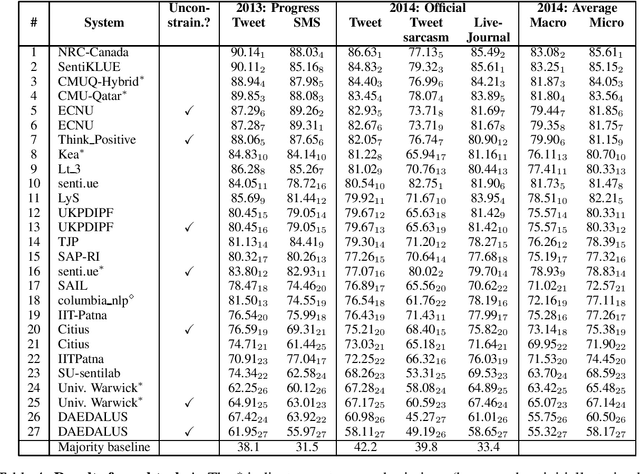
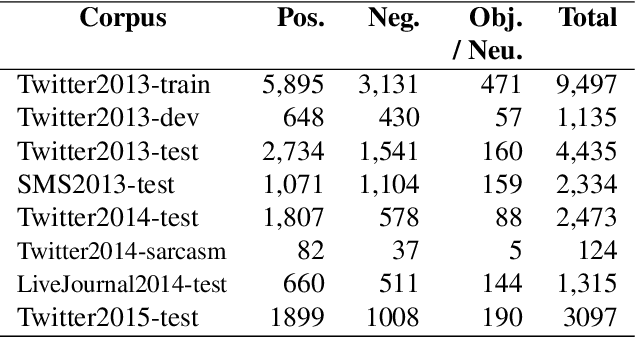
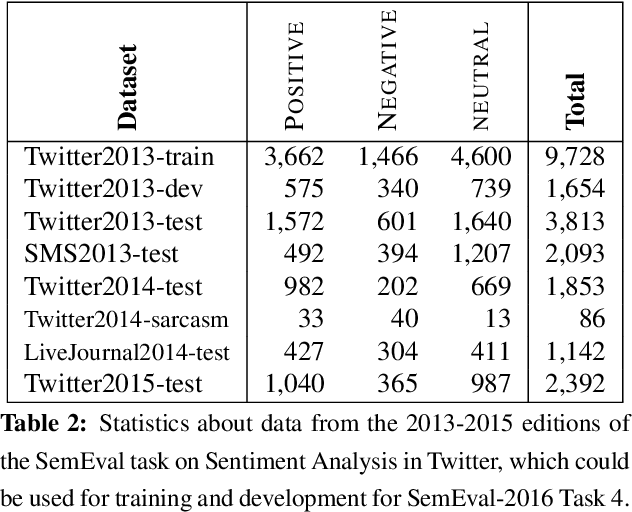
We describe the Sentiment Analysis in Twitter task, ran as part of SemEval-2014. It is a continuation of the last year's task that ran successfully as part of SemEval-2013. As in 2013, this was the most popular SemEval task; a total of 46 teams contributed 27 submissions for subtask A (21 teams) and 50 submissions for subtask B (44 teams). This year, we introduced three new test sets: (i) regular tweets, (ii) sarcastic tweets, and (iii) LiveJournal sentences. We further tested on (iv) 2013 tweets, and (v) 2013 SMS messages. The highest F1-score on (i) was achieved by NRC-Canada at 86.63 for subtask A and by TeamX at 70.96 for subtask B.
* Sentiment analysis, microblog sentiment analysis, Twitter opinion mining, sarcasm, LiveJournal, SMS
SemEval-2015 Task 10: Sentiment Analysis in Twitter
Dec 05, 2019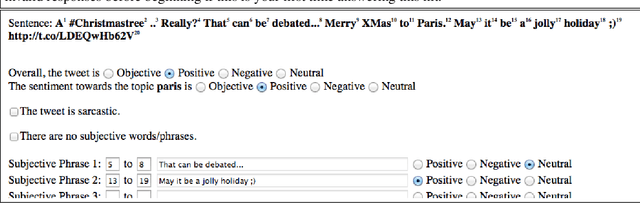

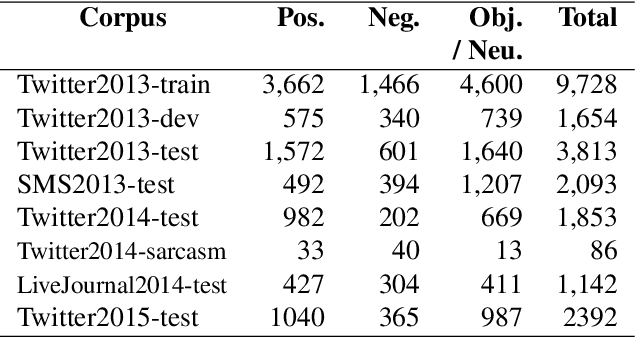
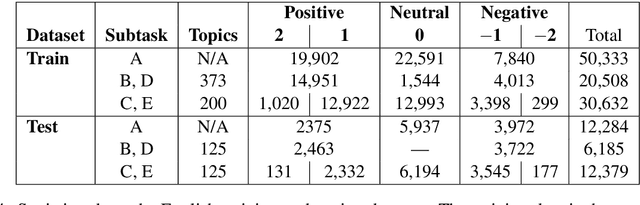
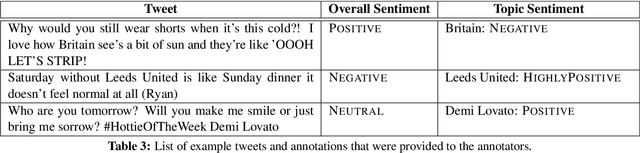
In this paper, we describe the 2015 iteration of the SemEval shared task on Sentiment Analysis in Twitter. This was the most popular sentiment analysis shared task to date with more than 40 teams participating in each of the last three years. This year's shared task competition consisted of five sentiment prediction subtasks. Two were reruns from previous years: (A) sentiment expressed by a phrase in the context of a tweet, and (B) overall sentiment of a tweet. We further included three new subtasks asking to predict (C) the sentiment towards a topic in a single tweet, (D) the overall sentiment towards a topic in a set of tweets, and (E) the degree of prior polarity of a phrase.
* Sentiment analysis, sentiment towards a topic, quantification, microblog sentiment analysis; Twitter opinion mining
SemEval-2016 Task 4: Sentiment Analysis in Twitter
Dec 03, 2019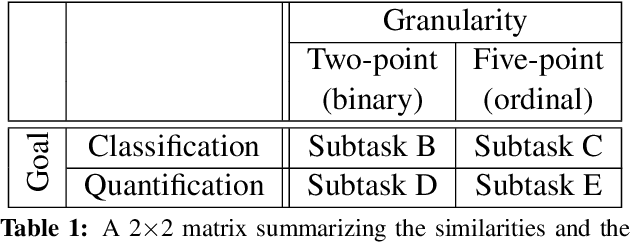
This paper discusses the fourth year of the ``Sentiment Analysis in Twitter Task''. SemEval-2016 Task 4 comprises five subtasks, three of which represent a significant departure from previous editions. The first two subtasks are reruns from prior years and ask to predict the overall sentiment, and the sentiment towards a topic in a tweet. The three new subtasks focus on two variants of the basic ``sentiment classification in Twitter'' task. The first variant adopts a five-point scale, which confers an ordinal character to the classification task. The second variant focuses on the correct estimation of the prevalence of each class of interest, a task which has been called quantification in the supervised learning literature. The task continues to be very popular, attracting a total of 43 teams.
* Sentiment analysis, sentiment towards a topic, quantification, microblog sentiment analysis; Twitter opinion mining. arXiv admin note: text overlap with arXiv:1912.00741
SemEval-2017 Task 4: Sentiment Analysis in Twitter
Dec 02, 2019This paper describes the fifth year of the Sentiment Analysis in Twitter task. SemEval-2017 Task 4 continues with a rerun of the subtasks of SemEval-2016 Task 4, which include identifying the overall sentiment of the tweet, sentiment towards a topic with classification on a two-point and on a five-point ordinal scale, and quantification of the distribution of sentiment towards a topic across a number of tweets: again on a two-point and on a five-point ordinal scale. Compared to 2016, we made two changes: (i) we introduced a new language, Arabic, for all subtasks, and (ii)~we made available information from the profiles of the Twitter users who posted the target tweets. The task continues to be very popular, with a total of 48 teams participating this year.
SemEval-2019 Task 6: Identifying and Categorizing Offensive Language in Social Media (OffensEval)
Apr 16, 2019
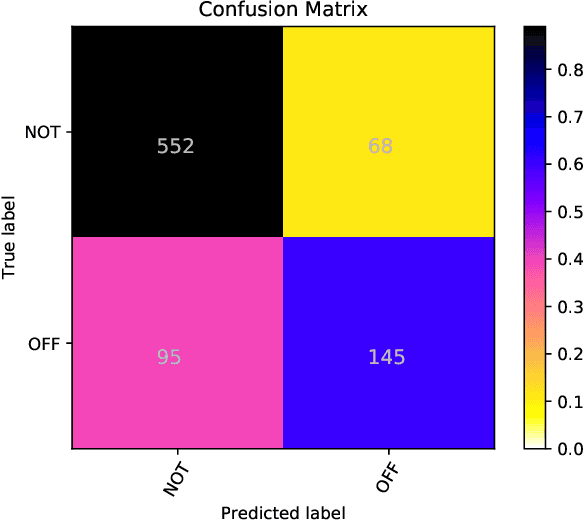
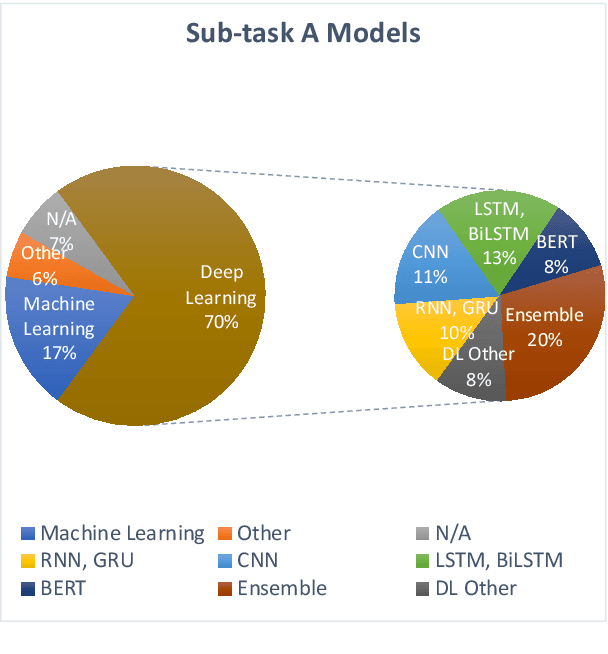
This paper presents the results and main findings of the Identifying and Categorizing Offensive Language in Social Media (OffensEval) shared task organized with SemEval-2019. SemEval-2019 Task 6 provided participants with the Offensive Language Identification Dataset (OLID), an annotated dataset containing over 14,000 English tweets. The competition was divided into three sub-tasks. In sub-task A systems were trained to discriminate between offensive and non-offensive tweets, in sub-task B systems were trained to identify the type of offensive content in the post, and finally, in sub-task C systems were trained to identify the target of offensive posts. OffensEval attracted a large number of participants and it was one of the most popular tasks in SemEval-2019. In total, nearly 800 teams signed up to participate in the task and 115 of them submitted results which are presented and analyzed in this report.