 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRTP-LX: Can LLMs Evaluate Toxicity in Multilingual Scenarios?
Apr 22, 2024



Large language models (LLMs) and small language models (SLMs) are being adopted at remarkable speed, although their safety still remains a serious concern. With the advent of multilingual S/LLMs, the question now becomes a matter of scale: can we expand multilingual safety evaluations of these models with the same velocity at which they are deployed? To this end we introduce RTP-LX, a human-transcreated and human-annotated corpus of toxic prompts and outputs in 28 languages. RTP-LX follows participatory design practices, and a portion of the corpus is especially designed to detect culturally-specific toxic language. We evaluate seven S/LLMs on their ability to detect toxic content in a culturally-sensitive, multilingual scenario. We find that, although they typically score acceptably in terms of accuracy, they have low agreement with human judges when judging holistically the toxicity of a prompt, and have difficulty discerning harm in context-dependent scenarios, particularly with subtle-yet-harmful content (e.g. microagressions, bias). We release of this dataset to contribute to further reduce harmful uses of these models and improve their safe deployment.
SemEval-2017 Task 4: Sentiment Analysis in Twitter
Dec 02, 2019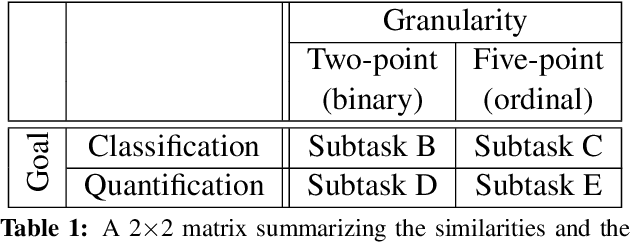
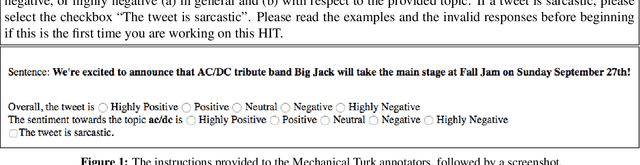
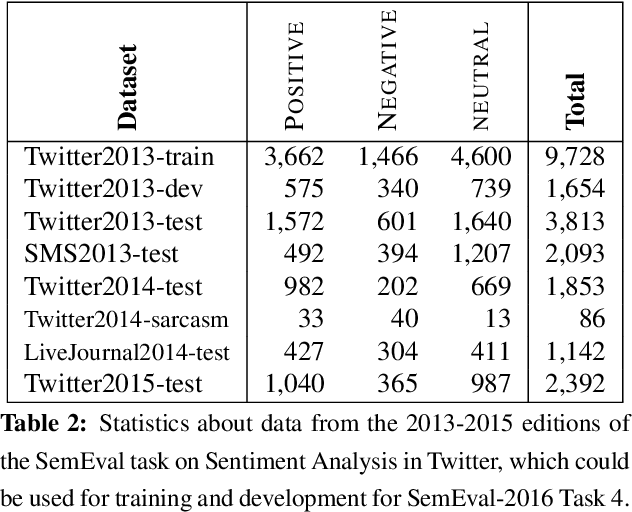
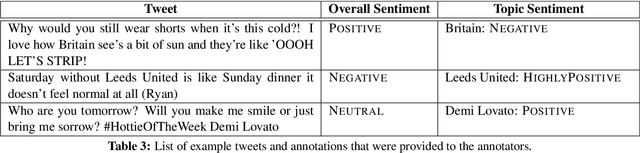
This paper describes the fifth year of the Sentiment Analysis in Twitter task. SemEval-2017 Task 4 continues with a rerun of the subtasks of SemEval-2016 Task 4, which include identifying the overall sentiment of the tweet, sentiment towards a topic with classification on a two-point and on a five-point ordinal scale, and quantification of the distribution of sentiment towards a topic across a number of tweets: again on a two-point and on a five-point ordinal scale. Compared to 2016, we made two changes: (i) we introduced a new language, Arabic, for all subtasks, and (ii)~we made available information from the profiles of the Twitter users who posted the target tweets. The task continues to be very popular, with a total of 48 teams participating this year.
SemEval-2019 Task 6: Identifying and Categorizing Offensive Language in Social Media (OffensEval)
Apr 16, 2019
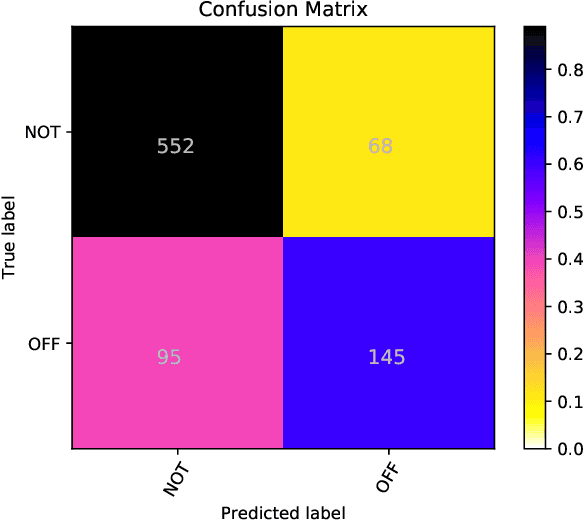
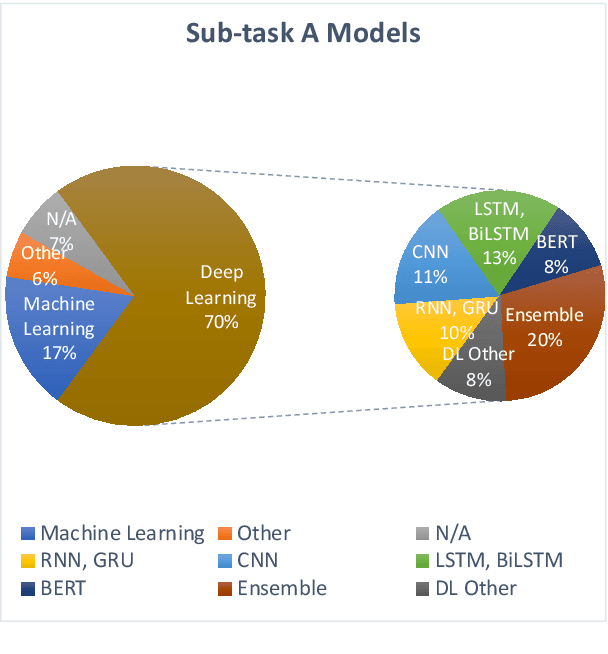
This paper presents the results and main findings of the Identifying and Categorizing Offensive Language in Social Media (OffensEval) shared task organized with SemEval-2019. SemEval-2019 Task 6 provided participants with the Offensive Language Identification Dataset (OLID), an annotated dataset containing over 14,000 English tweets. The competition was divided into three sub-tasks. In sub-task A systems were trained to discriminate between offensive and non-offensive tweets, in sub-task B systems were trained to identify the type of offensive content in the post, and finally, in sub-task C systems were trained to identify the target of offensive posts. OffensEval attracted a large number of participants and it was one of the most popular tasks in SemEval-2019. In total, nearly 800 teams signed up to participate in the task and 115 of them submitted results which are presented and analyzed in this report.
Predicting the Type and Target of Offensive Posts in Social Media
Apr 16, 2019
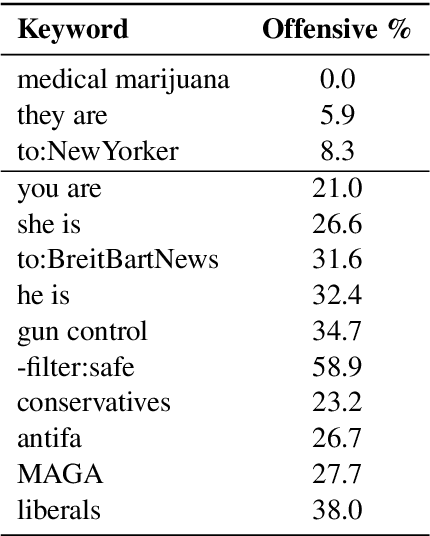
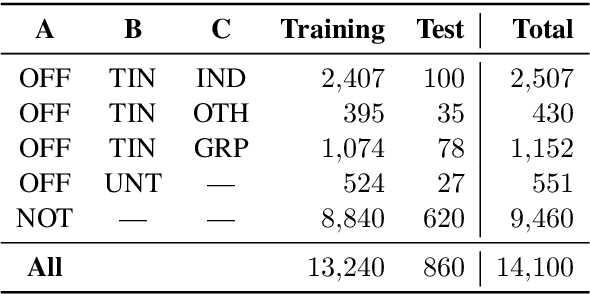
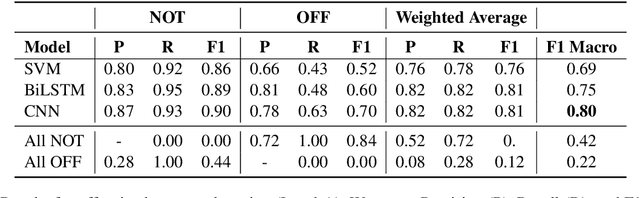
As offensive content has become pervasive in social media, there has been much research in identifying potentially offensive messages. However, previous work on this topic did not consider the problem as a whole, but rather focused on detecting very specific types of offensive content, e.g., hate speech, cyberbulling, or cyber-aggression. In contrast, here we target several different kinds of offensive content. In particular, we model the task hierarchically, identifying the type and the target of offensive messages in social media. For this purpose, we complied the Offensive Language Identification Dataset (OLID), a new dataset with tweets annotated for offensive content using a fine-grained three-layer annotation scheme, which we make publicly available. We discuss the main similarities and differences between OLID and pre-existing datasets for hate speech identification, aggression detection, and similar tasks. We further experiment with and we compare the performance of different machine learning models on OLID.
The ARIEL-CMU Systems for LoReHLT18
Feb 24, 2019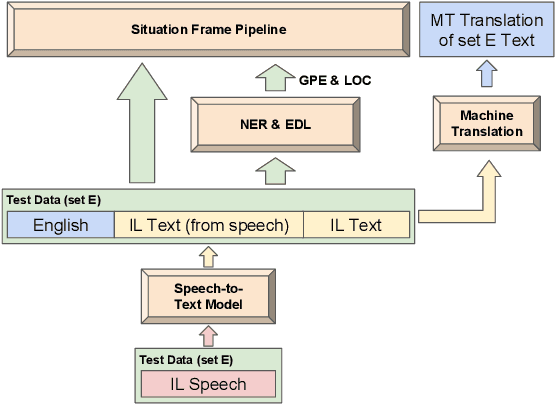
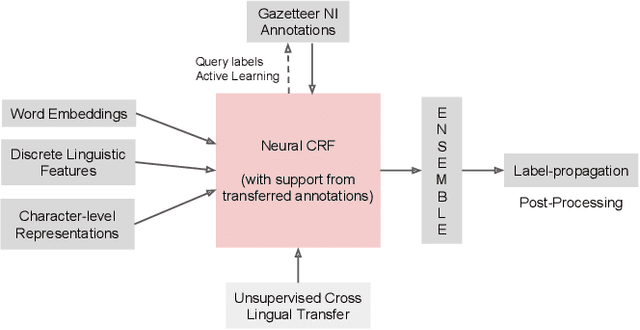
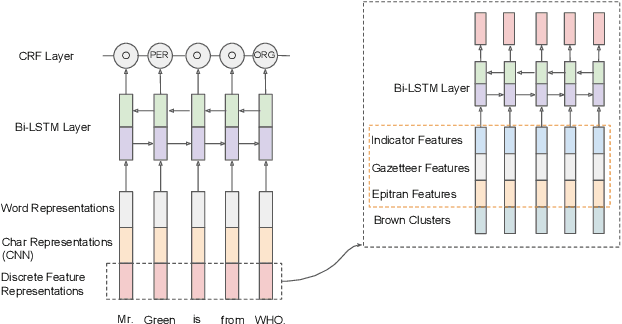
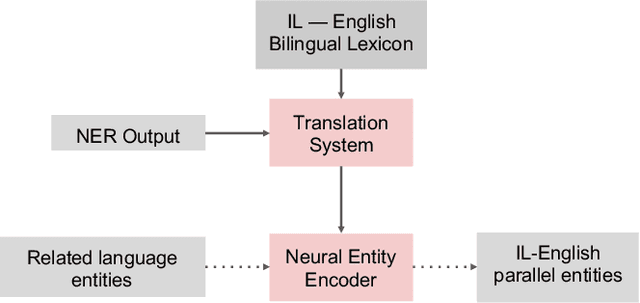
This paper describes the ARIEL-CMU submissions to the Low Resource Human Language Technologies (LoReHLT) 2018 evaluations for the tasks Machine Translation (MT), Entity Discovery and Linking (EDL), and detection of Situation Frames in Text and Speech (SF Text and Speech).
SMARTies: Sentiment Models for Arabic Target Entities
Jan 12, 2017
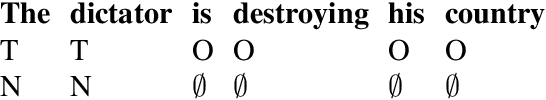

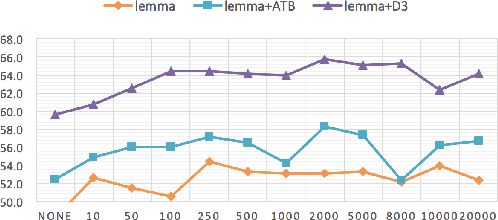
We consider entity-level sentiment analysis in Arabic, a morphologically rich language with increasing resources. We present a system that is applied to complex posts written in response to Arabic newspaper articles. Our goal is to identify important entity "targets" within the post along with the polarity expressed about each target. We achieve significant improvements over multiple baselines, demonstrating that the use of specific morphological representations improves the performance of identifying both important targets and their sentiment, and that the use of distributional semantic clusters further boosts performances for these representations, especially when richer linguistic resources are not available.