 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALF: Advertiser Large Foundation Model for Multi-Modal Advertiser Understanding
Apr 26, 2025



We present ALF (Advertiser Large Foundation model), a multi-modal transformer architecture for understanding advertiser behavior and intent across text, image, video and structured data modalities. Through contrastive learning and multi-task optimization, ALF creates unified advertiser representations that capture both content and behavioral patterns. Our model achieves state-of-the-art performance on critical tasks including fraud detection, policy violation identification, and advertiser similarity matching. In production deployment, ALF reduces false positives by 90% while maintaining 99.8% precision on abuse detection tasks. The architecture's effectiveness stems from its novel combination of multi-modal transformations, inter-sample attention mechanism, spectrally normalized projections, and calibrated probabilistic outputs.
Magic Pyramid: Accelerating Inference with Early Exiting and Token Pruning
Oct 30, 2021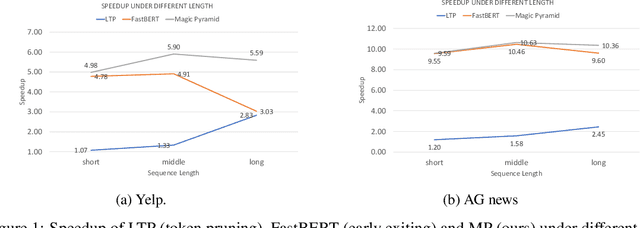
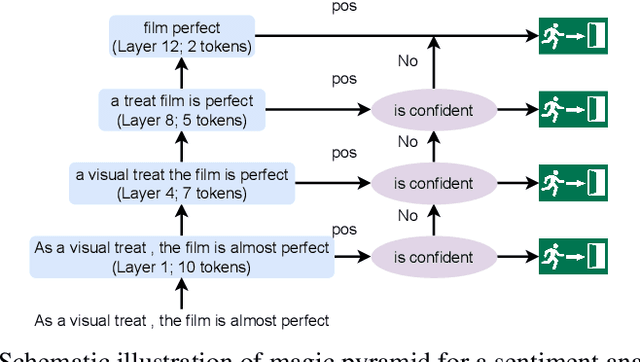
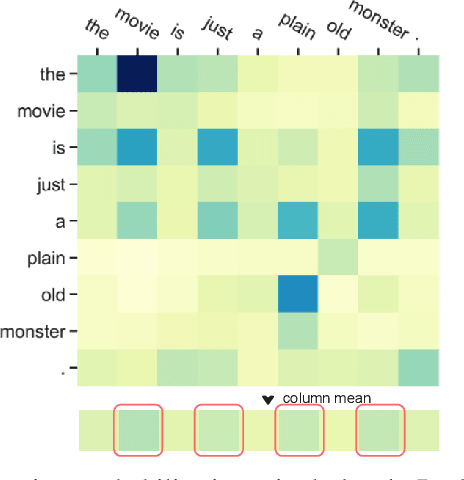
Pre-training and then fine-tuning large language models is commonly used to achieve state-of-the-art performance in natural language processing (NLP) tasks. However, most pre-trained models suffer from low inference speed. Deploying such large models to applications with latency constraints is challenging. In this work, we focus on accelerating the inference via conditional computations. To achieve this, we propose a novel idea, Magic Pyramid (MP), to reduce both width-wise and depth-wise computation via token pruning and early exiting for Transformer-based models, particularly BERT. The former manages to save the computation via removing non-salient tokens, while the latter can fulfill the computation reduction by terminating the inference early before reaching the final layer, if the exiting condition is met. Our empirical studies demonstrate that compared to previous state of arts, MP is not only able to achieve a speed-adjustable inference but also to surpass token pruning and early exiting by reducing up to 70% giga floating point operations (GFLOPs) with less than 0.5% accuracy drop. Token pruning and early exiting express distinctive preferences to sequences with different lengths. However, MP is capable of achieving an average of 8.06x speedup on two popular text classification tasks, regardless of the sizes of the inputs.