 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Techniques for Data Reduction of Climate Applications
May 01, 2024Scientists conduct large-scale simulations to compute derived quantities-of-interest (QoI) from primary data. Often, QoI are linked to specific features, regions, or time intervals, such that data can be adaptively reduced without compromising the integrity of QoI. For many spatiotemporal applications, these QoI are binary in nature and represent presence or absence of a physical phenomenon. We present a pipelined compression approach that first uses neural-network-based techniques to derive regions where QoI are highly likely to be present. Then, we employ a Guaranteed Autoencoder (GAE) to compress data with differential error bounds. GAE uses QoI information to apply low-error compression to only these regions. This results in overall high compression ratios while still achieving downstream goals of simulation or data collections. Experimental results are presented for climate data generated from the E3SM Simulation model for downstream quantities such as tropical cyclone and atmospheric river detection and tracking. These results show that our approach is superior to comparable methods in the literature.
Graph Attention Network for Lane-Wise and Topology-Invariant Intersection Traffic Simulation
Apr 11, 2024Traffic congestion has significant economic, environmental, and social ramifications. Intersection traffic flow dynamics are influenced by numerous factors. While microscopic traffic simulators are valuable tools, they are computationally intensive and challenging to calibrate. Moreover, existing machine-learning approaches struggle to provide lane-specific waveforms or adapt to intersection topology and traffic patterns. In this study, we propose two efficient and accurate "Digital Twin" models for intersections, leveraging Graph Attention Neural Networks (GAT). These attentional graph auto-encoder digital twins capture temporal, spatial, and contextual aspects of traffic within intersections, incorporating various influential factors such as high-resolution loop detector waveforms, signal state records, driving behaviors, and turning-movement counts. Trained on diverse counterfactual scenarios across multiple intersections, our models generalize well, enabling the estimation of detailed traffic waveforms for any intersection approach and exit lanes. Multi-scale error metrics demonstrate that our models perform comparably to microsimulations. The primary application of our study lies in traffic signal optimization, a pivotal area in transportation systems research. These lightweight digital twins can seamlessly integrate into corridor and network signal timing optimization frameworks. Furthermore, our study's applications extend to lane reconfiguration, driving behavior analysis, and facilitating informed decisions regarding intersection safety and efficiency enhancements. A promising avenue for future research involves extending this approach to urban freeway corridors and integrating it with measures of effectiveness metrics.
MGARD: A multigrid framework for high-performance, error-controlled data compression and refactoring
Jan 11, 2024We describe MGARD, a software providing MultiGrid Adaptive Reduction for floating-point scientific data on structured and unstructured grids. With exceptional data compression capability and precise error control, MGARD addresses a wide range of requirements, including storage reduction, high-performance I/O, and in-situ data analysis. It features a unified application programming interface (API) that seamlessly operates across diverse computing architectures. MGARD has been optimized with highly-tuned GPU kernels and efficient memory and device management mechanisms, ensuring scalable and rapid operations.
* 20 pages, 8 figures
Spatiotemporally adaptive compression for scientific dataset with feature preservation -- a case study on simulation data with extreme climate events analysis
Jan 06, 2024



Scientific discoveries are increasingly constrained by limited storage space and I/O capacities. For time-series simulations and experiments, their data often need to be decimated over timesteps to accommodate storage and I/O limitations. In this paper, we propose a technique that addresses storage costs while improving post-analysis accuracy through spatiotemporal adaptive, error-controlled lossy compression. We investigate the trade-off between data precision and temporal output rates, revealing that reducing data precision and increasing timestep frequency lead to more accurate analysis outcomes. Additionally, we integrate spatiotemporal feature detection with data compression and demonstrate that performing adaptive error-bounded compression in higher dimensional space enables greater compression ratios, leveraging the error propagation theory of a transformation-based compressor. To evaluate our approach, we conduct experiments using the well-known E3SM climate simulation code and apply our method to compress variables used for cyclone tracking. Our results show a significant reduction in storage size while enhancing the quality of cyclone tracking analysis, both quantitatively and qualitatively, in comparison to the prevalent timestep decimation approach. Compared to three state-of-the-art lossy compressors lacking feature preservation capabilities, our adaptive compression framework improves perfectly matched cases in TC tracking by 26.4-51.3% at medium compression ratios and by 77.3-571.1% at large compression ratios, with a merely 5-11% computational overhead.
* 10 pages, 13 figures, 2023 IEEE International Conference on e-Science and Grid Computing
A Spatiotemporal Correspondence Approach to Unsupervised LiDAR Segmentation with Traffic Applications
Aug 23, 2023



We address the problem of unsupervised semantic segmentation of outdoor LiDAR point clouds in diverse traffic scenarios. The key idea is to leverage the spatiotemporal nature of a dynamic point cloud sequence and introduce drastically stronger augmentation by establishing spatiotemporal correspondences across multiple frames. We dovetail clustering and pseudo-label learning in this work. Essentially, we alternate between clustering points into semantic groups and optimizing models using point-wise pseudo-spatiotemporal labels with a simple learning objective. Therefore, our method can learn discriminative features in an unsupervised learning fashion. We show promising segmentation performance on Semantic-KITTI, SemanticPOSS, and FLORIDA benchmark datasets covering scenarios in autonomous vehicle and intersection infrastructure, which is competitive when compared against many existing fully supervised learning methods. This general framework can lead to a unified representation learning approach for LiDAR point clouds incorporating domain knowledge.
An Efficient Semi-Automated Scheme for Infrastructure LiDAR Annotation
Jan 25, 2023



Most existing perception systems rely on sensory data acquired from cameras, which perform poorly in low light and adverse weather conditions. To resolve this limitation, we have witnessed advanced LiDAR sensors become popular in perception tasks in autonomous driving applications. Nevertheless, their usage in traffic monitoring systems is less ubiquitous. We identify two significant obstacles in cost-effectively and efficiently developing such a LiDAR-based traffic monitoring system: (i) public LiDAR datasets are insufficient for supporting perception tasks in infrastructure systems, and (ii) 3D annotations on LiDAR point clouds are time-consuming and expensive. To fill this gap, we present an efficient semi-automated annotation tool that automatically annotates LiDAR sequences with tracking algorithms while offering a fully annotated infrastructure LiDAR dataset -- FLORIDA (Florida LiDAR-based Object Recognition and Intelligent Data Annotation) -- which will be made publicly available. Our advanced annotation tool seamlessly integrates multi-object tracking (MOT), single-object tracking (SOT), and suitable trajectory post-processing techniques. Specifically, we introduce a human-in-the-loop schema in which annotators recursively fix and refine annotations imperfectly predicted by our tool and incrementally add them to the training dataset to obtain better SOT and MOT models. By repeating the process, we significantly increase the overall annotation speed by three to four times and obtain better qualitative annotations than a state-of-the-art annotation tool. The human annotation experiments verify the effectiveness of our annotation tool. In addition, we provide detailed statistics and object detection evaluation results for our dataset in serving as a benchmark for perception tasks at traffic intersections.
Scalable Hybrid Learning Techniques for Scientific Data Compression
Dec 21, 2022



Data compression is becoming critical for storing scientific data because many scientific applications need to store large amounts of data and post process this data for scientific discovery. Unlike image and video compression algorithms that limit errors to primary data, scientists require compression techniques that accurately preserve derived quantities of interest (QoIs). This paper presents a physics-informed compression technique implemented as an end-to-end, scalable, GPU-based pipeline for data compression that addresses this requirement. Our hybrid compression technique combines machine learning techniques and standard compression methods. Specifically, we combine an autoencoder, an error-bounded lossy compressor to provide guarantees on raw data error, and a constraint satisfaction post-processing step to preserve the QoIs within a minimal error (generally less than floating point error). The effectiveness of the data compression pipeline is demonstrated by compressing nuclear fusion simulation data generated by a large-scale fusion code, XGC, which produces hundreds of terabytes of data in a single day. Our approach works within the ADIOS framework and results in compression by a factor of more than 150 while requiring only a few percent of the computational resources necessary for generating the data, making the overall approach highly effective for practical scenarios.
Expressing linear equality constraints in feedforward neural networks
Nov 08, 2022


We seek to impose linear, equality constraints in feedforward neural networks. As top layer predictors are usually nonlinear, this is a difficult task if we seek to deploy standard convex optimization methods and strong duality. To overcome this, we introduce a new saddle-point Lagrangian with auxiliary predictor variables on which constraints are imposed. Elimination of the auxiliary variables leads to a dual minimization problem on the Lagrange multipliers introduced to satisfy the linear constraints. This minimization problem is combined with the standard learning problem on the weight matrices. From this theoretical line of development, we obtain the surprising interpretation of Lagrange parameters as additional, penultimate layer hidden units with fixed weights stemming from the constraints. Consequently, standard minimization approaches can be used despite the inclusion of Lagrange parameters -- a very satisfying, albeit unexpected, discovery. Examples ranging from multi-label classification to constrained autoencoders are envisaged in the future.
Learning Canonical Embeddings for Unsupervised Shape Correspondence with Locally Linear Transformations
Sep 07, 2022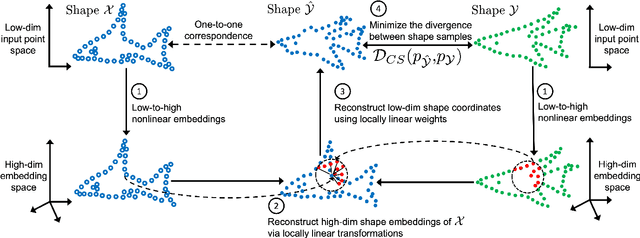
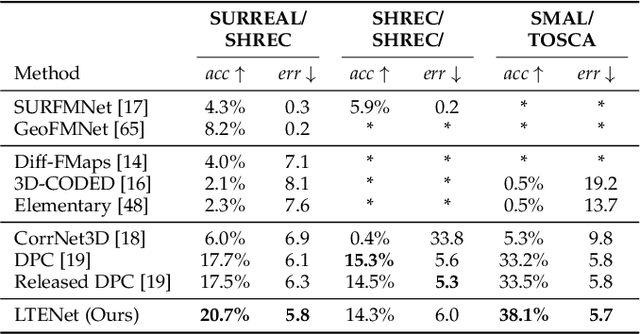
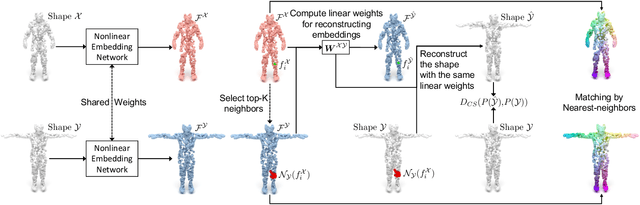

We present a new approach to unsupervised shape correspondence learning between pairs of point clouds. We make the first attempt to adapt the classical locally linear embedding algorithm (LLE) -- originally designed for nonlinear dimensionality reduction -- for shape correspondence. The key idea is to find dense correspondences between shapes by first obtaining high-dimensional neighborhood-preserving embeddings of low-dimensional point clouds and subsequently aligning the source and target embeddings using locally linear transformations. We demonstrate that learning the embedding using a new LLE-inspired point cloud reconstruction objective results in accurate shape correspondences. More specifically, the approach comprises an end-to-end learnable framework of extracting high-dimensional neighborhood-preserving embeddings, estimating locally linear transformations in the embedding space, and reconstructing shapes via divergence measure-based alignment of probabilistic density functions built over reconstructed and target shapes. Our approach enforces embeddings of shapes in correspondence to lie in the same universal/canonical embedding space, which eventually helps regularize the learning process and leads to a simple nearest neighbors approach between shape embeddings for finding reliable correspondences. Comprehensive experiments show that the new method makes noticeable improvements over state-of-the-art approaches on standard shape correspondence benchmark datasets covering both human and nonhuman shapes.
Slot Order Matters for Compositional Scene Understanding
Jun 03, 2022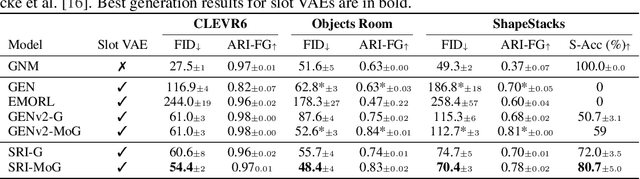
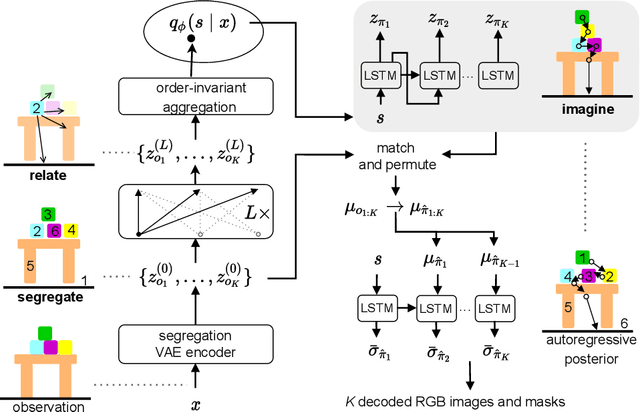


Empowering agents with a compositional understanding of their environment is a promising next step toward solving long-horizon planning problems. On the one hand, we have seen encouraging progress on variational inference algorithms for obtaining sets of object-centric latent representations ("slots") from unstructured scene observations. On the other hand, generating scenes from slots has received less attention, in part because it is complicated by the lack of a canonical object order. A canonical object order is useful for learning the object correlations necessary to generate physically plausible scenes similar to how raster scan order facilitates learning pixel correlations for pixel-level autoregressive image generation. In this work, we address this lack by learning a fixed object order for a hierarchical variational autoencoder with a single level of autoregressive slots and a global scene prior. We cast autoregressive slot inference as a set-to-sequence modeling problem. We introduce an auxiliary loss to train the slot prior to generate objects in a fixed order. During inference, we align a set of inferred slots to the object order obtained from a slot prior rollout. To ensure the rolled out objects are meaningful for the given scene, we condition the prior on an inferred global summary of the input. Experiments on compositional environments and ablations demonstrate that our model with global prior, inference with aligned slot order, and auxiliary loss achieves state-of-the-art sample quality.