 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Attention-Enhanced Network with Joint Dehazing and Retinex-Based Enhancement for Underwater Images
May 14, 2026Underwater images suffer from severe wavelength-dependent light absorption and scattering, and turbidity due to suspended particles, degrading visual quality for applications in autonomous underwater vehicles (AUVs), marine biology, archaeology, and offshore infrastructure inspection. Classical IFM inadequately capture nonlinear underwater light behavior, while purely data-driven methods lack physical interpretability. This paper proposes a three-stage network named ADR, that extends the underwater image formation model with additional terms to perform underwater dehazing, followed by Retinex-based enhancement and attention-enabled U-Net++ refinement. Experiments on UIEB and UFO-120 benchmark datasets demonstrate competitive performance with state-of-the-art methods.
An Underwater Dehazing Network with Implicit Transmission Estimation
May 13, 2026Underwater images suffer from wavelength-dependent light absorption and scattering, which reduces visual quality. This phenomenon could limit the operational reliability of autonomous underwater vehicles, marine surveys, and offshore inspection systems. Purely classical methods often achieve suboptimal performance in real-world datasets, while purely data-driven methods lack physical interpretability. In this letter, we propose UDehaze-iT, a deep network for underwater image enhancement that estimates scene depth implicitly and derives per-channel transmission through the Beer-Lambert law with learnable attenuation coefficients. We estimate atmospheric light as a semi-classical per-channel scalar, and a zero-initialized residual refiner corrects remaining artefacts after dehazing. To effectively train our method, we apply a composite loss function consisting of five key terms: a L1 loss, a multi-scale patchwise DCT loss, a forward model reconstruction loss, and two regularization terms. With ~0.9M parameters, UDehaze-iT achieves competitive performance on UIEB and UFO-120 datasets.
Functional Connectome Fingerprinting Using Convolutional and Dictionary Learning
Oct 30, 2025Advances in data analysis and machine learning have revolutionized the study of brain signatures using fMRI, enabling non-invasive exploration of cognition and behavior through individual neural patterns. Functional connectivity (FC), which quantifies statistical relationships between brain regions, has emerged as a key metric for studying individual variability and developing biomarkers for personalized medicine in neurological and psychiatric disorders. The concept of subject fingerprinting, introduced by Finn et al. (2015), leverages neural connectivity variability to identify individuals based on their unique patterns. While traditional FC methods perform well on small datasets, machine learning techniques are more effective with larger datasets, isolating individual-specific features and maximizing inter-subject differences. In this study, we propose a framework combining convolutional autoencoders and sparse dictionary learning to enhance fingerprint accuracy. Autoencoders capture shared connectivity patterns while isolating subject-specific features in residual FC matrices, which are analyzed using sparse coding to identify distinctive features. Tested on the Human Connectome Project dataset, this approach achieved a 10% improvement over baseline group-averaged FC models. Our results highlight the potential of integrating deep learning and sparse coding techniques for scalable and robust functional connectome fingerprinting, advancing personalized neuroscience applications and biomarker development.
Graph Guided Modulo Recovery of EEG Signals
Oct 30, 2025Electroencephalography (EEG) often shows significant variability among people. This fluctuation disrupts reliable acquisition and may result in distortion or clipping. Modulo sampling is now a promising solution to this problem, by folding signals instead of saturating them. Recovery of the original waveform from folded observations is a highly ill-posed problem. In this work, we propose a method based on a graph neural network, referred to as GraphUnwrapNet, for the modulo recovery of EEG signals. Our core idea is to represent an EEG signal as an organized graph whose channels and temporal connections establish underlying interdependence. One of our key contributions is in introducing a pre-estimation guided feature injection module to provide coarse folding indicators that enhance stability during recovery at wrap boundaries. This design integrates structural information with folding priors into an integrated framework. We performed comprehensive experiments on the Simultaneous Task EEG Workload (STEW) dataset. The results demonstrate consistent enhancements over traditional optimization techniques and competitive accuracy relative to current deep learning models. Our findings emphasize the potential of graph-based methodology for robust modulo EEG recovery.
Structure Aware Image Downscaling
Oct 26, 2025Image downscaling is one of the key operations in recent display technology and visualization tools. By this process, the dimension of an image is reduced, aiming to preserve structural integrity and visual fidelity. In this paper, we propose a new image downscaling method which is built on the core ideas of image filtering and edge detection. In particular, we present a structure-informed downscaling algorithm that maintains fine details through edge-aware processing. The proposed method comprises three steps: (i) edge map computation, (ii) edge-guided interpolation, and (iii) texture enhancement. To faithfully retain the strong structures in an image, we first compute the edge maps by applying an efficient edge detection operator. This is followed by an edge-guided interpolation to preserve fine details after resizing. Finally, we fuse local texture enriched component of the original image to the interpolated one to restore high-frequency information. By integrating edge information with adaptive filtering, our approach effectively minimizes artifacts while retaining crucial image features. To demonstrate the effective downscaling capability of our proposed method, we validate on four datasets: DIV2K, BSD100, Urban100, and RealSR. For downscaling by 4x, our method could achieve as high as 39.07 dB PSNR on the DIV2K dataset and 38.71 dB on the RealSR dataset. Extensive experimental results confirm that the proposed image downscaling method is capable of achieving superior performance in terms of both visual quality and performance metrics with reference to recent methods. Most importantly, the downscaled images by our method do not suffer from edge blurring and texture loss, unlike many existing ones.
Low-Light Image Enhancement Using Gamma Learning And Attention-Enabled Encoder-Decoder Networks
Oct 26, 2025Images acquired in low-light environments present significant obstacles for computer vision systems and human perception, especially for applications requiring accurate object recognition and scene analysis. Such images typically manifest multiple quality issues: amplified noise, inadequate scene illumination, contrast reduction, color distortion, and loss of details. While recent deep learning methods have shown promise, developing simple and efficient frameworks that naturally integrate global illumination adjustment with local detail refinement continues to be an important objective. To this end, we introduce a dual-stage deep learning architecture that combines adaptive gamma correction with attention-enhanced refinement to address these fundamental limitations. The first stage uses an Adaptive Gamma Correction Module (AGCM) to learn suitable gamma values for each pixel based on both local and global cues, producing a brightened intermediate output. The second stage applies an encoder-decoder deep network with Convolutional Block Attention Modules (CBAM) to this brightened image, in order to restore finer details. We train the network using a composite loss that includes L1 reconstruction, SSIM, total variation, color constancy, and gamma regularization terms to balance pixel accuracy with visual quality. Experiments on LOL-v1, LOL-v2 real, and LOL-v2 synthetic datasets show our method reaches PSNR of upto 29.96 dB and upto 0.9458 SSIM, outperforming existing approaches. Additional tests on DICM, LIME, MEF, and NPE datasets using NIQE, BRISQUE, and UNIQUE metrics confirm better perceptual quality with fewer artifacts, achieving the best NIQE scores across all datasets. Our GAtED (Gamma learned and Attention-enabled Encoder-Decoder) method effectively handles both global illumination adjustment and local detail enhancement, offering a practical solution for low-light enhancement.
A Poisson-Guided Decomposition Network for Extreme Low-Light Image Enhancement
Jun 04, 2025



Low-light image denoising and enhancement are challenging, especially when traditional noise assumptions, such as Gaussian noise, do not hold in majority. In many real-world scenarios, such as low-light imaging, noise is signal-dependent and is better represented as Poisson noise. In this work, we address the problem of denoising images degraded by Poisson noise under extreme low-light conditions. We introduce a light-weight deep learning-based method that integrates Retinex based decomposition with Poisson denoising into a unified encoder-decoder network. The model simultaneously enhances illumination and suppresses noise by incorporating a Poisson denoising loss to address signal-dependent noise. Without prior requirement for reflectance and illumination, the network learns an effective decomposition process while ensuring consistent reflectance and smooth illumination without causing any form of color distortion. The experimental results demonstrate the effectiveness and practicality of the proposed low-light illumination enhancement method. Our method significantly improves visibility and brightness in low-light conditions, while preserving image structure and color constancy under ambient illumination.
Efficient Hierarchical Bayesian Inference for Spatio-temporal Regression Models in Neuroimaging
Nov 23, 2021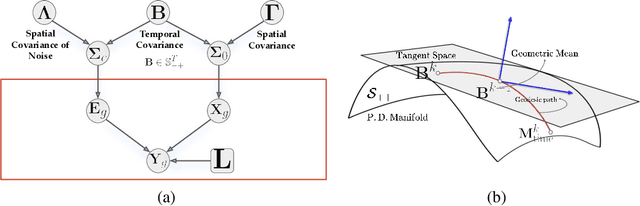
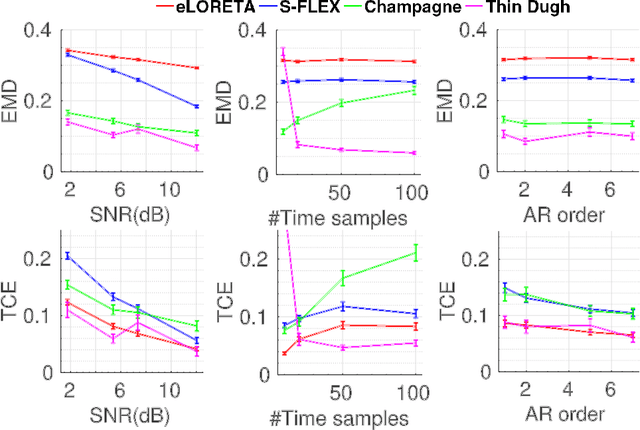
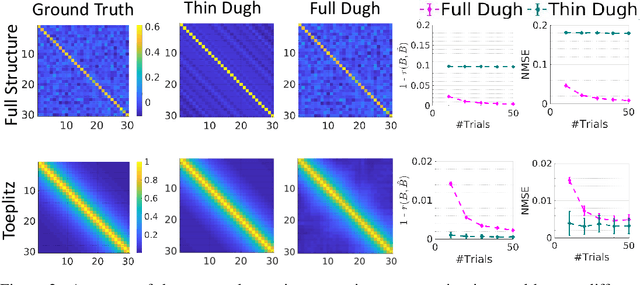
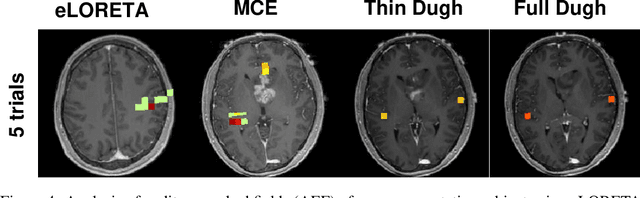
Several problems in neuroimaging and beyond require inference on the parameters of multi-task sparse hierarchical regression models. Examples include M/EEG inverse problems, neural encoding models for task-based fMRI analyses, and climate science. In these domains, both the model parameters to be inferred and the measurement noise may exhibit a complex spatio-temporal structure. Existing work either neglects the temporal structure or leads to computationally demanding inference schemes. Overcoming these limitations, we devise a novel flexible hierarchical Bayesian framework within which the spatio-temporal dynamics of model parameters and noise are modeled to have Kronecker product covariance structure. Inference in our framework is based on majorization-minimization optimization and has guaranteed convergence properties. Our highly efficient algorithms exploit the intrinsic Riemannian geometry of temporal autocovariance matrices. For stationary dynamics described by Toeplitz matrices, the theory of circulant embeddings is employed. We prove convex bounding properties and derive update rules of the resulting algorithms. On both synthetic and real neural data from M/EEG, we demonstrate that our methods lead to improved performance.
Nonlocal Co-occurrence for Image Downscaling
Dec 22, 2020

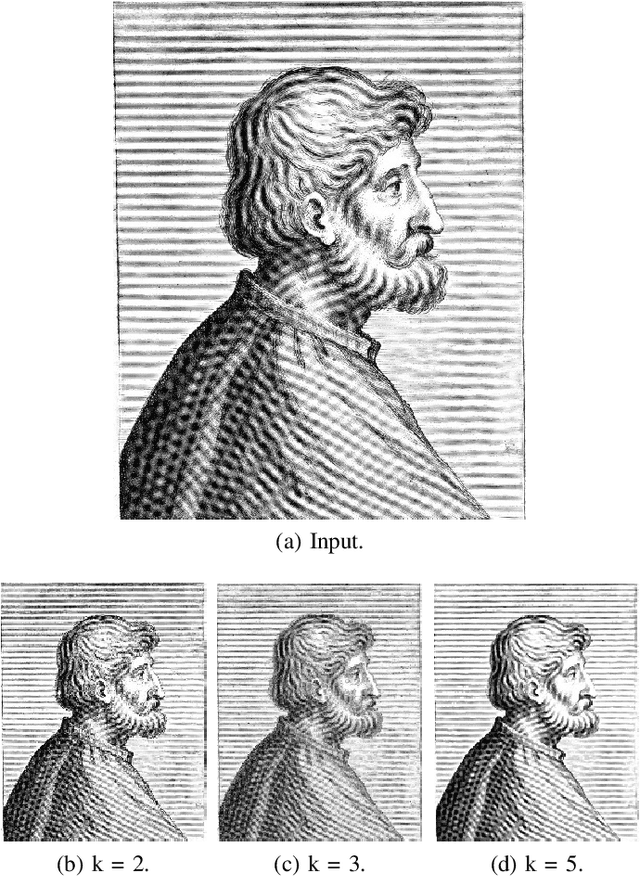
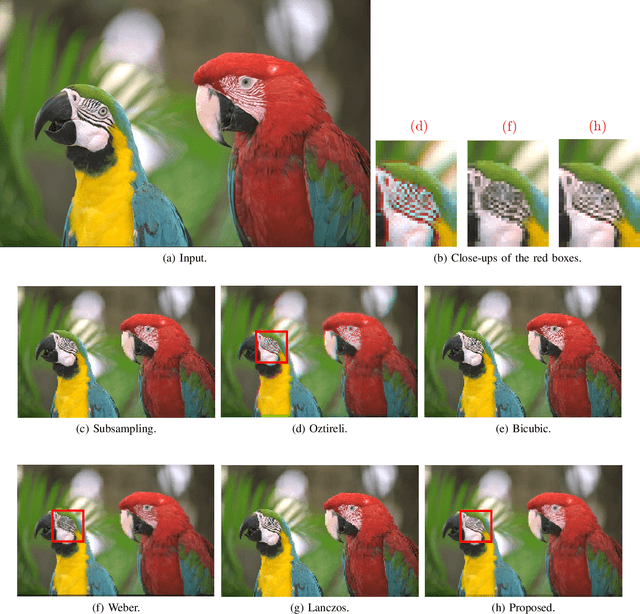
Image downscaling is one of the widely used operations in image processing and computer graphics. It was recently demonstrated in the literature that kernel-based convolutional filters could be modified to develop efficient image downscaling algorithms. In this work, we present a new downscaling technique which is based on kernel-based image filtering concept. We propose to use pairwise co-occurrence similarity of the pixelpairs as the range kernel similarity in the filtering operation. The co-occurrence of the pixel-pair is learned directly from the input image. This co-occurrence learning is performed in a neighborhood based fashion all over the image. The proposed method can preserve the high-frequency structures, which were present in the input image, into the downscaled image. The resulting images retain visually important details and do not suffer from edge-blurring artifact. We demonstrate the effectiveness of our proposed approach with extensive experiments on a large number of images downscaled with various downscaling factors.
Linearized ADMM and Fast Nonlocal Denoising for Efficient Plug-and-Play Restoration
Jan 18, 2019
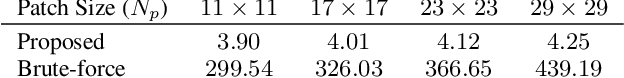
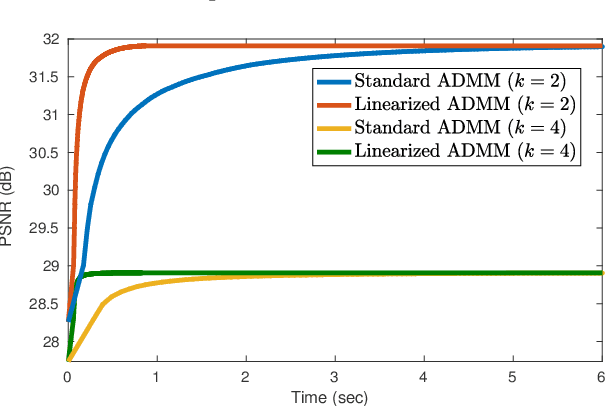
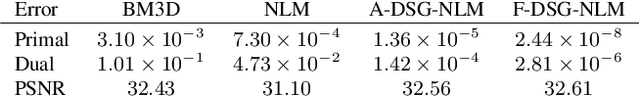
In plug-and-play image restoration, the regularization is performed using powerful denoisers such as nonlocal means (NLM) or BM3D. This is done within the framework of alternating direction method of multipliers (ADMM), where the regularization step is formally replaced by an off-the-shelf denoiser. Each plug-and-play iteration involves the inversion of the forward model followed by a denoising step. In this paper, we present a couple of ideas for improving the efficiency of the inversion and denoising steps. First, we propose to use linearized ADMM, which generally allows us to perform the inversion at a lower cost than standard ADMM. Moreover, we can easily incorporate hard constraints into the optimization framework as a result. Second, we develop a fast algorithm for doubly stochastic NLM, originally proposed by Sreehari et al. (IEEE TCI, 2016), which is about 80x faster than brute-force computation. This particular denoiser can be expressed as the proximal map of a convex regularizer and, as a consequence, we can guarantee convergence for linearized plug-and-play ADMM. We demonstrate the effectiveness of our proposals for super-resolution and single-photon imaging.