 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Training of Mixture-of-Experts Models with Megatron Core
Mar 10, 2026Scaling Mixture-of-Experts (MoE) training introduces systems challenges absent in dense models. Because each token activates only a subset of experts, this sparsity allows total parameters to grow much faster than per-token computation, creating coupled constraints across memory, communication, and computation. Optimizing one dimension often shifts pressure to another, demanding co-design across the full system stack. We address these challenges for MoE training through integrated optimizations spanning memory (fine-grained recomputation, offloading, etc.), communication (optimized dispatchers, overlapping, etc.), and computation (Grouped GEMM, fusions, CUDA Graphs, etc.). The framework also provides Parallel Folding for flexible multi-dimensional parallelism, low-precision training support for FP8 and NVFP4, and efficient long-context training. On NVIDIA GB300 and GB200, it achieves 1,233/1,048 TFLOPS/GPU for DeepSeek-V3-685B and 974/919 TFLOPS/GPU for Qwen3-235B. As a performant, scalable, and production-ready open-source solution, it has been used across academia and industry for training MoE models ranging from billions to trillions of parameters on clusters scaling up to thousands of GPUs. This report explains how these techniques work, their trade-offs, and their interactions at the systems level, providing practical guidance for scaling MoE models with Megatron Core.
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
Reducing Activation Recomputation in Large Transformer Models
May 10, 2022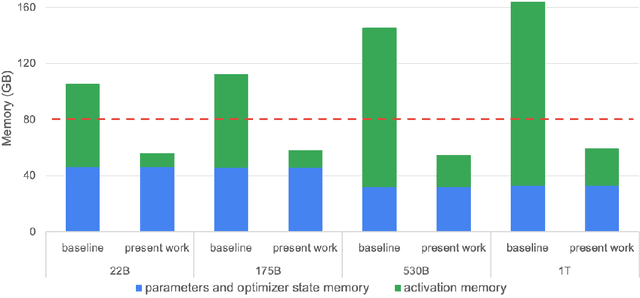


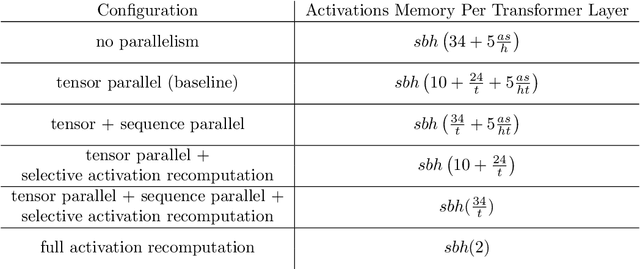
Training large transformer models is one of the most important computational challenges of modern AI. In this paper, we show how to significantly accelerate training of large transformer models by reducing activation recomputation. Activation recomputation is commonly used to work around memory capacity constraints. Rather than storing activations for backpropagation, they are traditionally recomputed, which saves memory but adds redundant compute. In this work, we show most of this redundant compute is unnecessary because we can reduce memory consumption sufficiently without it. We present two novel yet very simple techniques: sequence parallelism and selective activation recomputation. In conjunction with tensor parallelism, these techniques almost eliminate the need to recompute activations. We evaluate our approach on language models up to one trillion parameters in scale and show that our method reduces activation memory by 5x, while reducing execution time overhead from activation recomputation by over 90%. For example, when training a 530B parameter GPT-3 style model on 2240 NVIDIA A100 GPUs, we achieve a Model Flops Utilization of 54.2%, which is 29% faster than the 42.1% we achieve using recomputation. Our implementation will be available in both Megatron-LM and NeMo-Megatron.
FlexSA: Flexible Systolic Array Architecture for Efficient Pruned DNN Model Training
Apr 27, 2020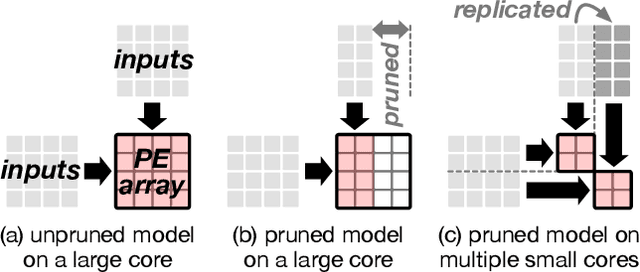
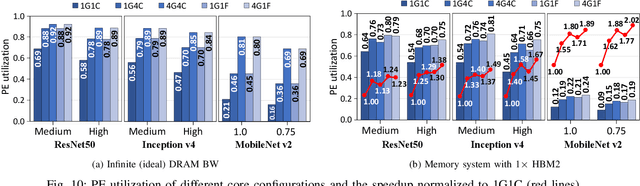
Modern deep learning models have high memory and computation cost. To make them fast and memory-cost efficient, structured model pruning is commonly used. We find that pruning a model using a common training accelerator with large systolic arrays is extremely performance-inefficient. To make a systolic array efficient for pruning and training, we propose FlexSA, a flexible systolic array architecture. FlexSA dynamically reconfigures the systolic array structure and offers multiple sub-systolic operating modes, which are designed for energy- and memory bandwidth-efficient processing of tensors with different sizes and shapes. We also present a compilation heuristic for tiling matrix-multiplication-and-accumulation operations in a training workload to best utilize the resources of FlexSA. Based on our evaluation, FlexSA with the proposed compilation heuristic improves compute resource utilization of pruning and training modern CNN models by 37% compared to a conventional training accelerator with a large systolic array. FlexSA also improves on-chip data reuse by 1.7X saving 28% energy compared to naive systolic array splitting.
DeLTA: GPU Performance Model for Deep Learning Applications with In-depth Memory System Traffic Analysis
Apr 02, 2019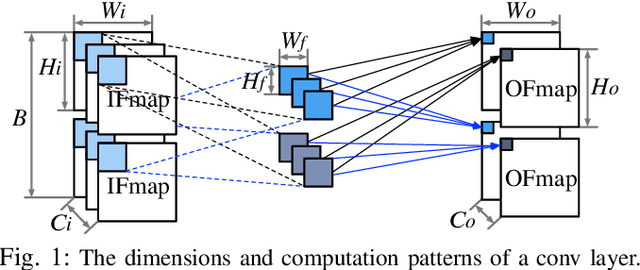
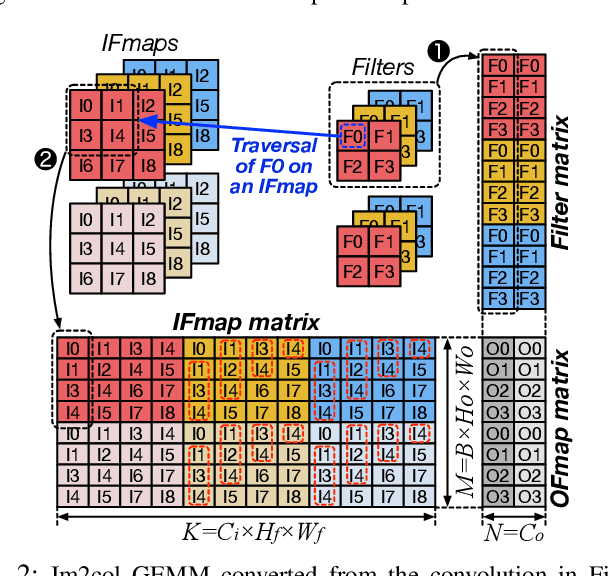
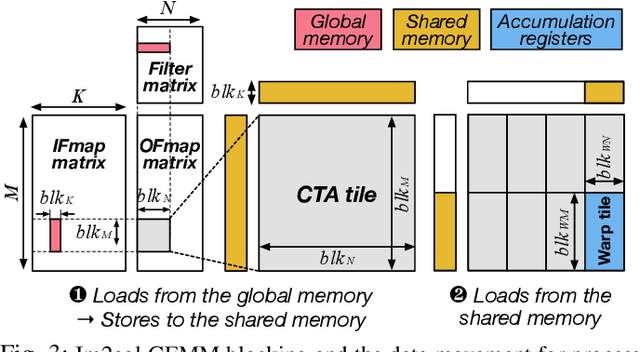
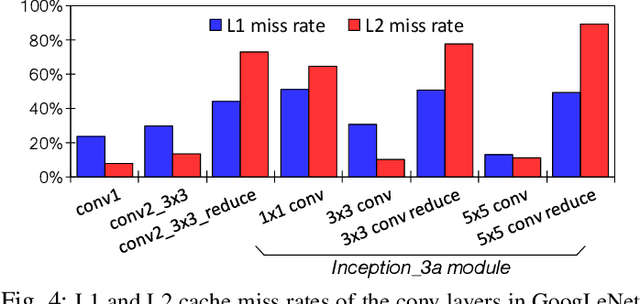
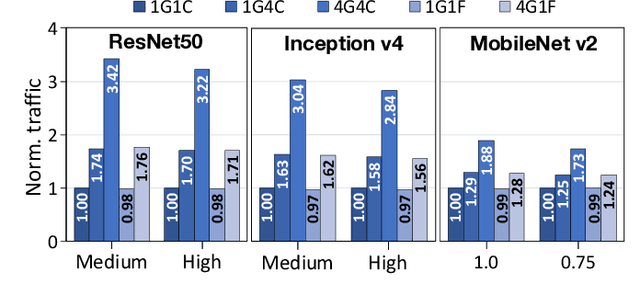
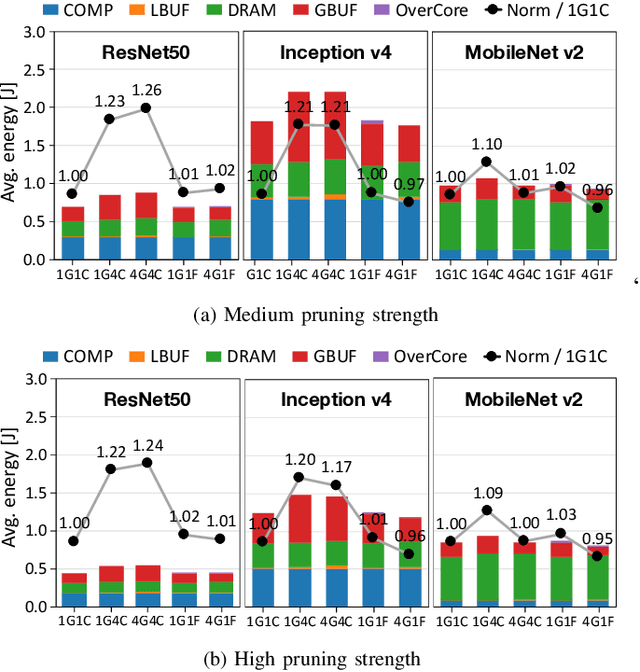
Training convolutional neural networks (CNNs) requires intense compute throughput and high memory bandwidth. Especially, convolution layers account for the majority of the execution time of CNN training, and GPUs are commonly used to accelerate these layer workloads. GPU design optimization for efficient CNN training acceleration requires the accurate modeling of how their performance improves when computing and memory resources are increased. We present DeLTA, the first analytical model that accurately estimates the traffic at each GPU memory hierarchy level, while accounting for the complex reuse patterns of a parallel convolution algorithm. We demonstrate that our model is both accurate and robust for different CNNs and GPU architectures. We then show how this model can be used to carefully balance the scaling of different GPU resources for efficient CNN performance improvement.
PruneTrain: Gradual Structured Pruning from Scratch for Faster Neural Network Training
Jan 26, 2019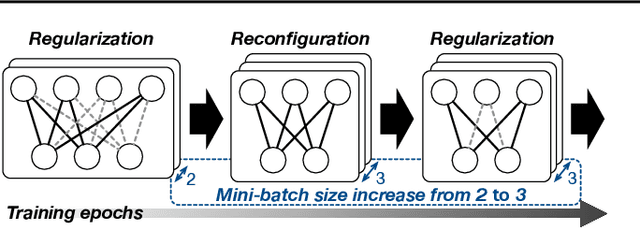
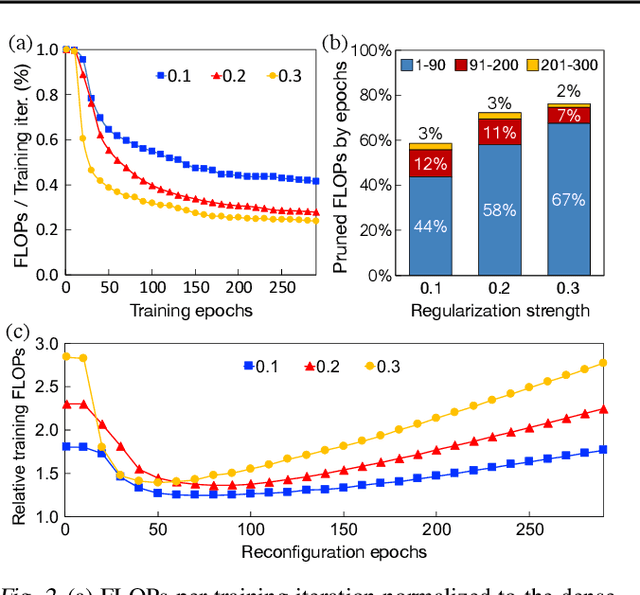
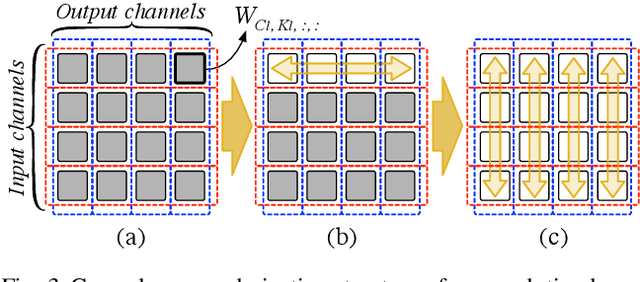
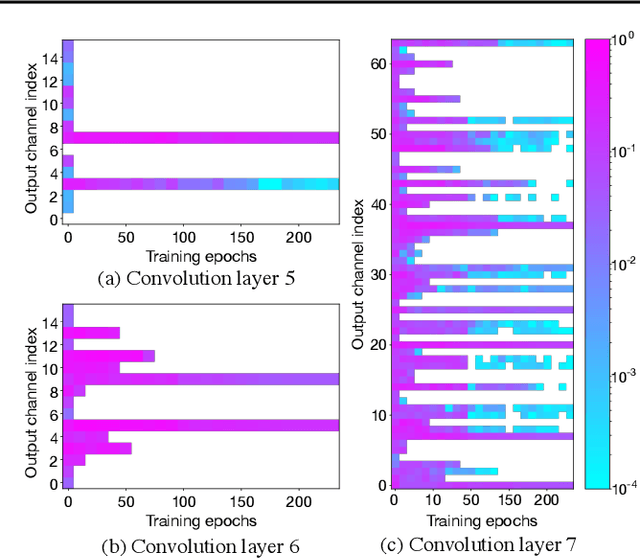
Model pruning is a popular mechanism to make a network more efficient for inference. In this paper, we explore the use of pruning to also make the training of such neural networks more efficient. Unlike all prior model pruning methods that sparsify a pre-trained model and then prune it, we train the network from scratch, while gradually and structurally pruning parameters during the training. We build on our key observations: 1) once parameters are sparsified via regularization, they rarely re-appear in later steps, and 2) setting the appropriate regularization penalty at the beginning of training effectively converges the loss. We train ResNet and VGG networks on CIFAR10/100 and ImageNet datasets from scratch, and achieve 30-50% improvement in training FLOPs and 20-30% improvement in measured training time on modern GPUs.
Mini-batch Serialization: CNN Training with Inter-layer Data Reuse
Sep 30, 2018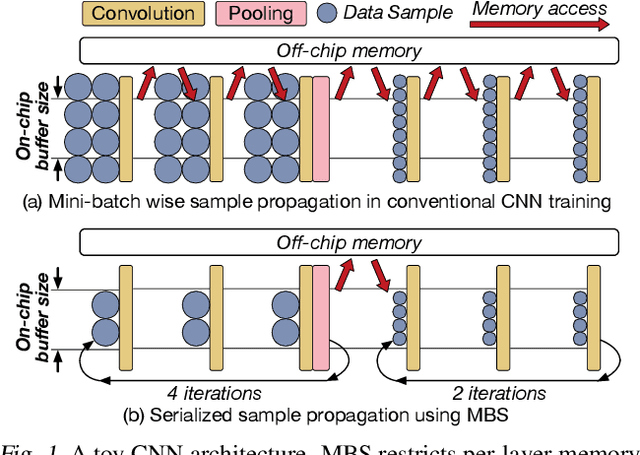
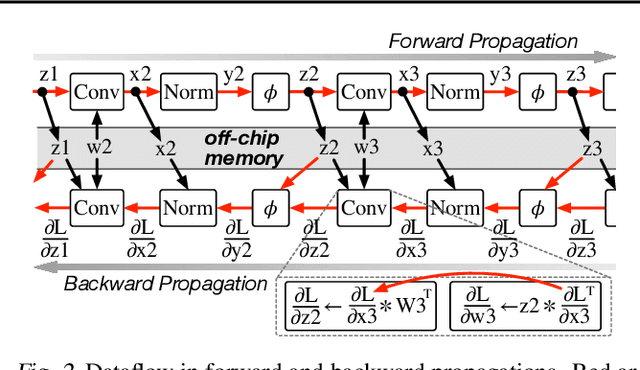
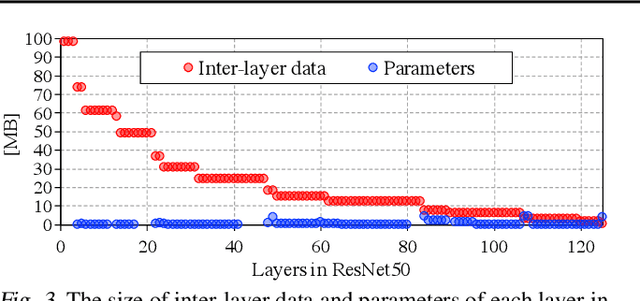
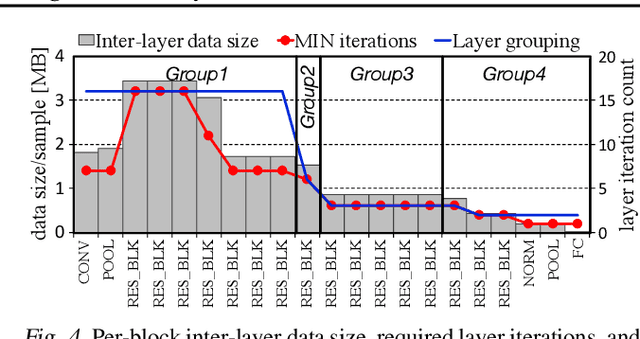
Training convolutional neural networks (CNNs) requires intense computations and high memory bandwidth. We find that bandwidth today is over-provisioned because most memory accesses in CNN training can be eliminated by rearranging computation to better utilize on-chip buffers and avoid traffic resulting from large per-layer memory footprints. We introduce the MBS CNN training approach that significantly reduces memory traffic by partially serializing mini-batch processing across groups of layers. This optimizes reuse within on-chip buffers and balances both intra-layer and inter-layer reuse. We also introduce the WaveCore CNN training accelerator that effectively trains CNNs in the MBS approach with high functional-unit utilization. Combined, WaveCore and MBS reduce DRAM traffic by 73%, improve performance by 45%, and save 24% system energy for modern deep CNN training compared to conventional training mechanisms and accelerators.