 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Mixture-of-Experts Specialization via Cluster-Aware Upcycling
Apr 15, 2026Sparse Upcycling provides an efficient way to initialize a Mixture-of-Experts (MoE) model from pretrained dense weights instead of training from scratch. However, since all experts start from identical weights and the router is randomly initialized, the model suffers from expert symmetry and limited early specialization. We propose Cluster-aware Upcycling, a strategy that incorporates semantic structure into MoE initialization. Our method first partitions the dense model's input activations into semantic clusters. Each expert is then initialized using the subspace representations of its corresponding cluster via truncated SVD, while setting the router's initial weights to the cluster centroids. This cluster-aware initialization breaks expert symmetry and encourages early specialization aligned with the data distribution. Furthermore, we introduce an expert-ensemble self-distillation loss that stabilizes training by providing reliable routing guidance using an ensemble teacher. When evaluated on CLIP ViT-B/32 and ViT-B/16, Cluster-aware Upcycling consistently outperforms existing methods across both zero-shot and few-shot benchmarks. The proposed method also produces more diverse and disentangled expert representations, reduces inter-expert similarity, and leads to more confident routing behavior.
Pri4R: Learning World Dynamics for Vision-Language-Action Models with Privileged 4D Representation
Mar 02, 2026Humans learn not only how their bodies move, but also how the surrounding world responds to their actions. In contrast, while recent Vision-Language-Action (VLA) models exhibit impressive semantic understanding, they often fail to capture the spatiotemporal dynamics governing physical interaction. In this paper, we introduce Pri4R, a simple yet effective approach that endows VLA models with an implicit understanding of world dynamics by leveraging privileged 4D information during training. Specifically, Pri4R augments VLAs with a lightweight point track head that predicts 3D point tracks. By injecting VLA features into this head to jointly predict future 3D trajectories, the model learns to incorporate evolving scene geometry within its shared representation space, enabling more physically aware context for precise control. Due to its architectural simplicity, Pri4R is compatible with dominant VLA design patterns with minimal changes. During inference, we run the model using the original VLA architecture unchanged; Pri4R adds no extra inputs, outputs, or computational overhead. Across simulation and real-world evaluations, Pri4R significantly improves performance on challenging manipulation tasks, including a +10% gain on LIBERO-Long and a +40% gain on RoboCasa. We further show that 3D point track prediction is an effective supervision target for learning action-world dynamics, and validate our design choices through extensive ablations.
Fine-Grained Video Captioning through Scene Graph Consolidation
Feb 23, 2025Recent advances in visual language models (VLMs) have significantly improved image captioning, but extending these gains to video understanding remains challenging due to the scarcity of fine-grained video captioning datasets. To bridge this gap, we propose a novel zero-shot video captioning approach that combines frame-level scene graphs from a video to obtain intermediate representations for caption generation. Our method first generates frame-level captions using an image VLM, converts them into scene graphs, and consolidates these graphs to produce comprehensive video-level descriptions. To achieve this, we leverage a lightweight graph-to-text model trained solely on text corpora, eliminating the need for video captioning annotations. Experiments on the MSR-VTT and ActivityNet Captions datasets show that our approach outperforms zero-shot video captioning baselines, demonstrating that aggregating frame-level scene graphs yields rich video understanding without requiring large-scale paired data or high inference cost.
Pooling Revisited: Your Receptive Field is Suboptimal
May 30, 2022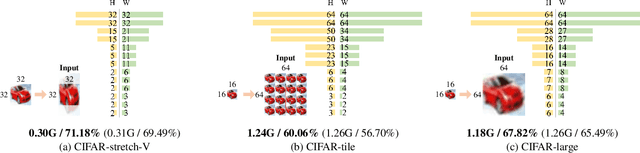
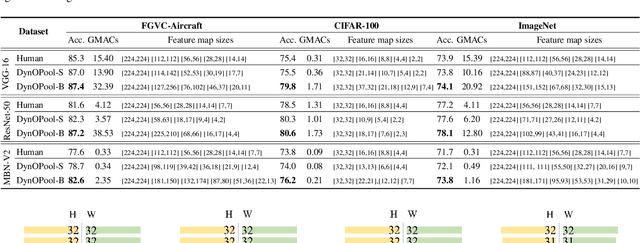
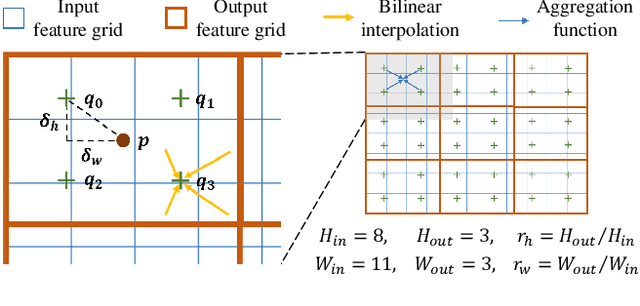
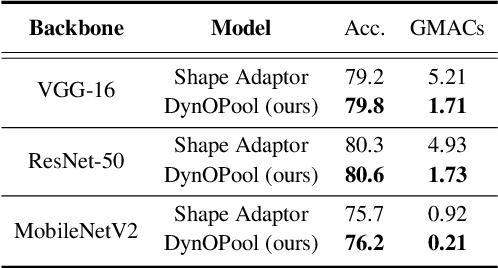
The size and shape of the receptive field determine how the network aggregates local information and affect the overall performance of a model considerably. Many components in a neural network, such as kernel sizes and strides for convolution and pooling operations, influence the configuration of a receptive field. However, they still rely on hyperparameters, and the receptive fields of existing models result in suboptimal shapes and sizes. Hence, we propose a simple yet effective Dynamically Optimized Pooling operation, referred to as DynOPool, which optimizes the scale factors of feature maps end-to-end by learning the desirable size and shape of its receptive field in each layer. Any kind of resizing modules in a deep neural network can be replaced by the operations with DynOPool at a minimal cost. Also, DynOPool controls the complexity of a model by introducing an additional loss term that constrains computational cost. Our experiments show that the models equipped with the proposed learnable resizing module outperform the baseline networks on multiple datasets in image classification and semantic segmentation.
Learning Debiased and Disentangled Representations for Semantic Segmentation
Oct 31, 2021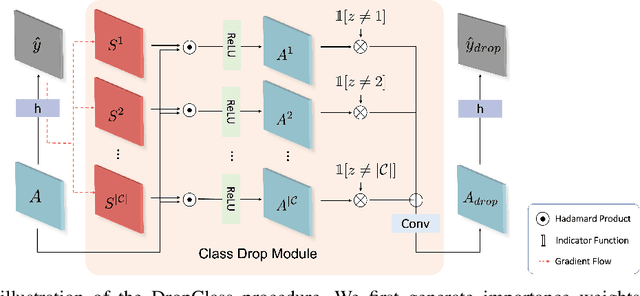
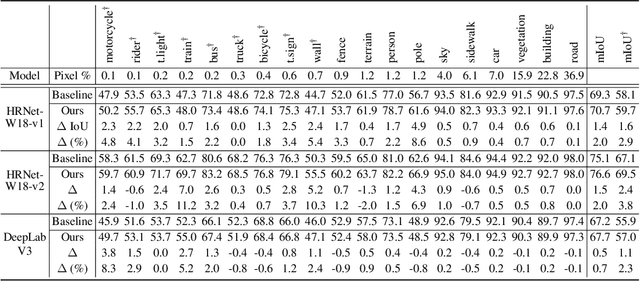
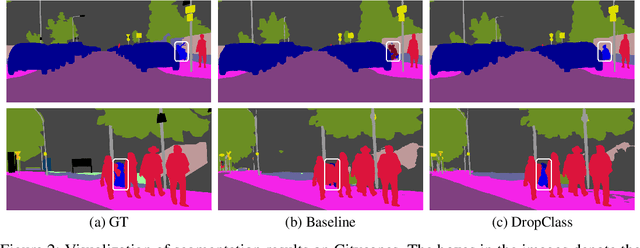

Deep neural networks are susceptible to learn biased models with entangled feature representations, which may lead to subpar performances on various downstream tasks. This is particularly true for under-represented classes, where a lack of diversity in the data exacerbates the tendency. This limitation has been addressed mostly in classification tasks, but there is little study on additional challenges that may appear in more complex dense prediction problems including semantic segmentation. To this end, we propose a model-agnostic and stochastic training scheme for semantic segmentation, which facilitates the learning of debiased and disentangled representations. For each class, we first extract class-specific information from the highly entangled feature map. Then, information related to a randomly sampled class is suppressed by a feature selection process in the feature space. By randomly eliminating certain class information in each training iteration, we effectively reduce feature dependencies among classes, and the model is able to learn more debiased and disentangled feature representations. Models trained with our approach demonstrate strong results on multiple semantic segmentation benchmarks, with especially notable performance gains on under-represented classes.