 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamera-Driven Representation Learning for Unsupervised Domain Adaptive Person Re-identification
Aug 23, 2023



We present a novel unsupervised domain adaption method for person re-identification (reID) that generalizes a model trained on a labeled source domain to an unlabeled target domain. We introduce a camera-driven curriculum learning (CaCL) framework that leverages camera labels of person images to transfer knowledge from source to target domains progressively. To this end, we divide target domain dataset into multiple subsets based on the camera labels, and initially train our model with a single subset (i.e., images captured by a single camera). We then gradually exploit more subsets for training, according to a curriculum sequence obtained with a camera-driven scheduling rule. The scheduler considers maximum mean discrepancies (MMD) between each subset and the source domain dataset, such that the subset closer to the source domain is exploited earlier within the curriculum. For each curriculum sequence, we generate pseudo labels of person images in a target domain to train a reID model in a supervised way. We have observed that the pseudo labels are highly biased toward cameras, suggesting that person images obtained from the same camera are likely to have the same pseudo labels, even for different IDs. To address the camera bias problem, we also introduce a camera-diversity (CD) loss encouraging person images of the same pseudo label, but captured across various cameras, to involve more for discriminative feature learning, providing person representations robust to inter-camera variations. Experimental results on standard benchmarks, including real-to-real and synthetic-to-real scenarios, demonstrate the effectiveness of our framework.
Extracting Structured Seed-Mediated Gold Nanorod Growth Procedures from Literature with GPT-3
Apr 26, 2023Although gold nanorods have been the subject of much research, the pathways for controlling their shape and thereby their optical properties remain largely heuristically understood. Although it is apparent that the simultaneous presence of and interaction between various reagents during synthesis control these properties, computational and experimental approaches for exploring the synthesis space can be either intractable or too time-consuming in practice. This motivates an alternative approach leveraging the wealth of synthesis information already embedded in the body of scientific literature by developing tools to extract relevant structured data in an automated, high-throughput manner. To that end, we present an approach using the powerful GPT-3 language model to extract structured multi-step seed-mediated growth procedures and outcomes for gold nanorods from unstructured scientific text. GPT-3 prompt completions are fine-tuned to predict synthesis templates in the form of JSON documents from unstructured text input with an overall accuracy of $86\%$. The performance is notable, considering the model is performing simultaneous entity recognition and relation extraction. We present a dataset of 11,644 entities extracted from 1,137 papers, resulting in 268 papers with at least one complete seed-mediated gold nanorod growth procedure and outcome for a total of 332 complete procedures.
Structured information extraction from complex scientific text with fine-tuned large language models
Dec 10, 2022



Intelligently extracting and linking complex scientific information from unstructured text is a challenging endeavor particularly for those inexperienced with natural language processing. Here, we present a simple sequence-to-sequence approach to joint named entity recognition and relation extraction for complex hierarchical information in scientific text. The approach leverages a pre-trained large language model (LLM), GPT-3, that is fine-tuned on approximately 500 pairs of prompts (inputs) and completions (outputs). Information is extracted either from single sentences or across sentences in abstracts/passages, and the output can be returned as simple English sentences or a more structured format, such as a list of JSON objects. We demonstrate that LLMs trained in this way are capable of accurately extracting useful records of complex scientific knowledge for three representative tasks in materials chemistry: linking dopants with their host materials, cataloging metal-organic frameworks, and general chemistry/phase/morphology/application information extraction. This approach represents a simple, accessible, and highly-flexible route to obtaining large databases of structured knowledge extracted from unstructured text. An online demo is available at http://www.matscholar.com/info-extraction.
Decomposed Knowledge Distillation for Class-Incremental Semantic Segmentation
Oct 12, 2022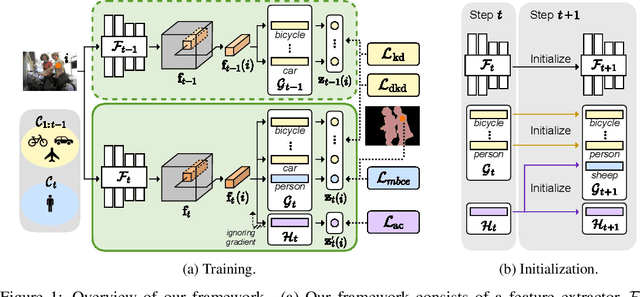
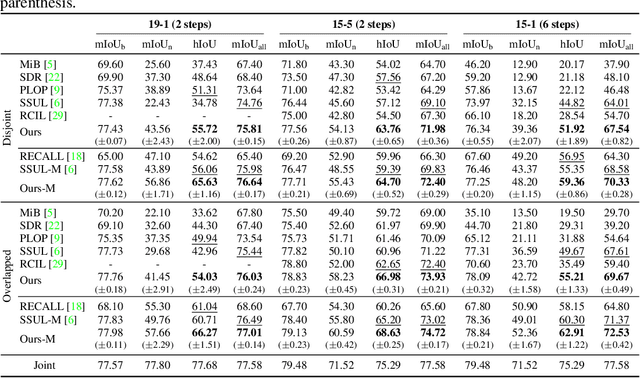
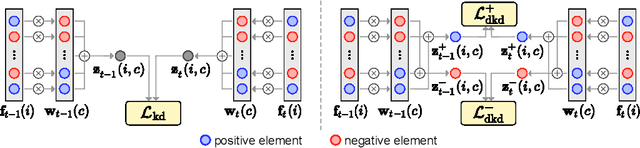
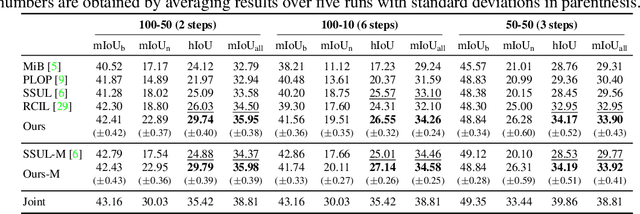
Class-incremental semantic segmentation (CISS) labels each pixel of an image with a corresponding object/stuff class continually. To this end, it is crucial to learn novel classes incrementally without forgetting previously learned knowledge. Current CISS methods typically use a knowledge distillation (KD) technique for preserving classifier logits, or freeze a feature extractor, to avoid the forgetting problem. The strong constraints, however, prevent learning discriminative features for novel classes. We introduce a CISS framework that alleviates the forgetting problem and facilitates learning novel classes effectively. We have found that a logit can be decomposed into two terms. They quantify how likely an input belongs to a particular class or not, providing a clue for a reasoning process of a model. The KD technique, in this context, preserves the sum of two terms (i.e., a class logit), suggesting that each could be changed and thus the KD does not imitate the reasoning process. To impose constraints on each term explicitly, we propose a new decomposed knowledge distillation (DKD) technique, improving the rigidity of a model and addressing the forgetting problem more effectively. We also introduce a novel initialization method to train new classifiers for novel classes. In CISS, the number of negative training samples for novel classes is not sufficient to discriminate old classes. To mitigate this, we propose to transfer knowledge of negatives to the classifiers successively using an auxiliary classifier, boosting the performance significantly. Experimental results on standard CISS benchmarks demonstrate the effectiveness of our framework.
OIMNet++: Prototypical Normalization and Localization-aware Learning for Person Search
Jul 21, 2022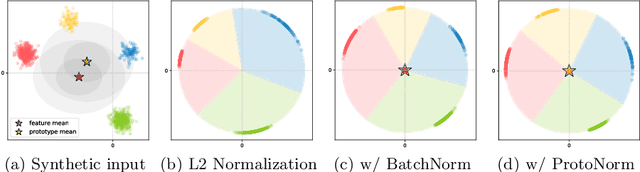
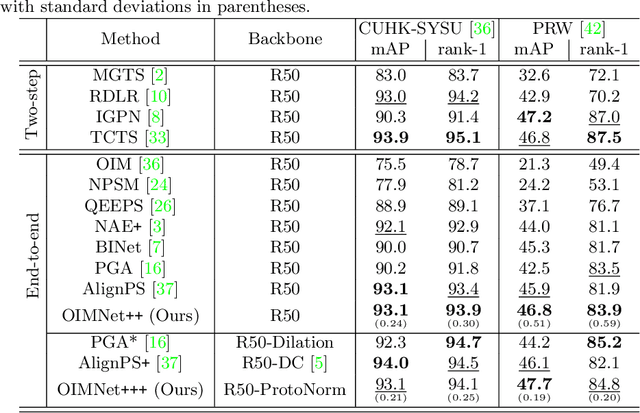
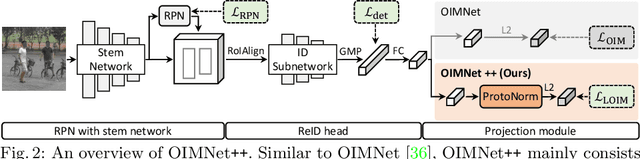
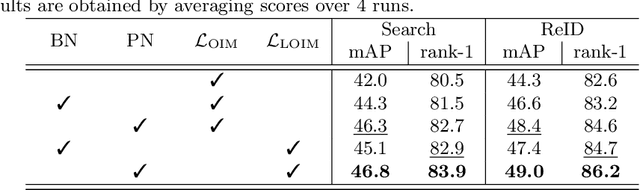
We address the task of person search, that is, localizing and re-identifying query persons from a set of raw scene images. Recent approaches are typically built upon OIMNet, a pioneer work on person search, that learns joint person representations for performing both detection and person re-identification (reID) tasks. To obtain the representations, they extract features from pedestrian proposals, and then project them on a unit hypersphere with L2 normalization. These methods also incorporate all positive proposals, that sufficiently overlap with the ground truth, equally to learn person representations for reID. We have found that 1) the L2 normalization without considering feature distributions degenerates the discriminative power of person representations, and 2) positive proposals often also depict background clutter and person overlaps, which could encode noisy features to person representations. In this paper, we introduce OIMNet++ that addresses the aforementioned limitations. To this end, we introduce a novel normalization layer, dubbed ProtoNorm, that calibrates features from pedestrian proposals, while considering a long-tail distribution of person IDs, enabling L2 normalized person representations to be discriminative. We also propose a localization-aware feature learning scheme that encourages better-aligned proposals to contribute more in learning discriminative representations. Experimental results and analysis on standard person search benchmarks demonstrate the effectiveness of OIMNet++.
Learning by Aligning: Visible-Infrared Person Re-identification using Cross-Modal Correspondences
Aug 17, 2021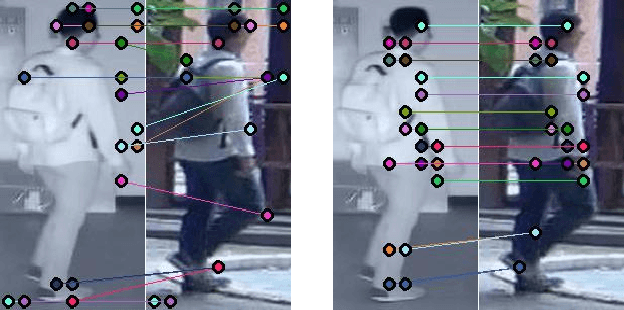
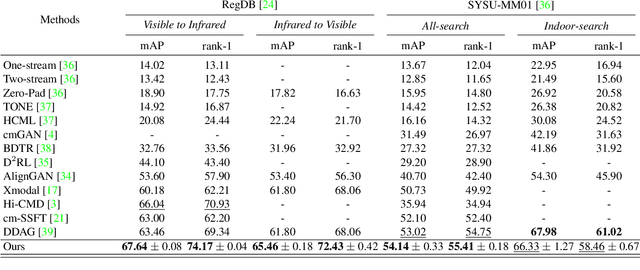
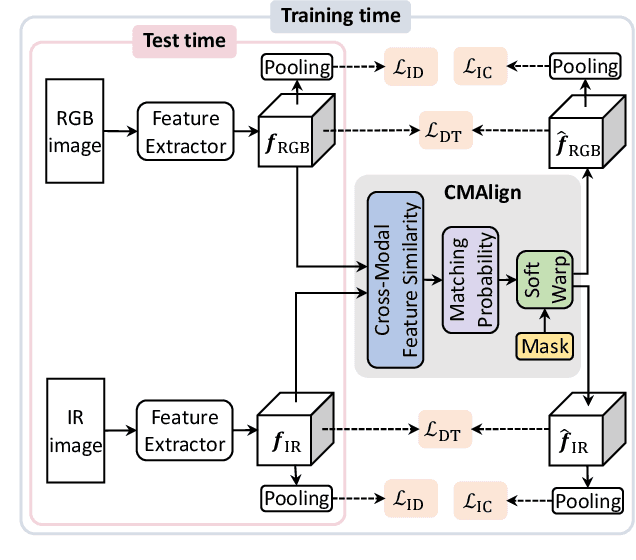
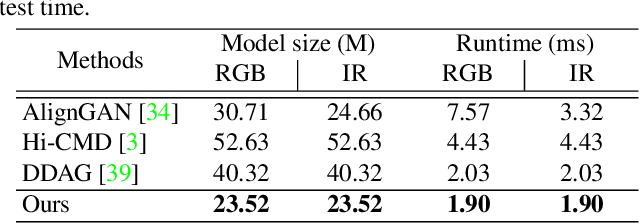
We address the problem of visible-infrared person re-identification (VI-reID), that is, retrieving a set of person images, captured by visible or infrared cameras, in a cross-modal setting. Two main challenges in VI-reID are intra-class variations across person images, and cross-modal discrepancies between visible and infrared images. Assuming that the person images are roughly aligned, previous approaches attempt to learn coarse image- or rigid part-level person representations that are discriminative and generalizable across different modalities. However, the person images, typically cropped by off-the-shelf object detectors, are not necessarily well-aligned, which distract discriminative person representation learning. In this paper, we introduce a novel feature learning framework that addresses these problems in a unified way. To this end, we propose to exploit dense correspondences between cross-modal person images. This allows to address the cross-modal discrepancies in a pixel-level, suppressing modality-related features from person representations more effectively. This also encourages pixel-wise associations between cross-modal local features, further facilitating discriminative feature learning for VI-reID. Extensive experiments and analyses on standard VI-reID benchmarks demonstrate the effectiveness of our approach, which significantly outperforms the state of the art.
HVPR: Hybrid Voxel-Point Representation for Single-stage 3D Object Detection
Apr 02, 2021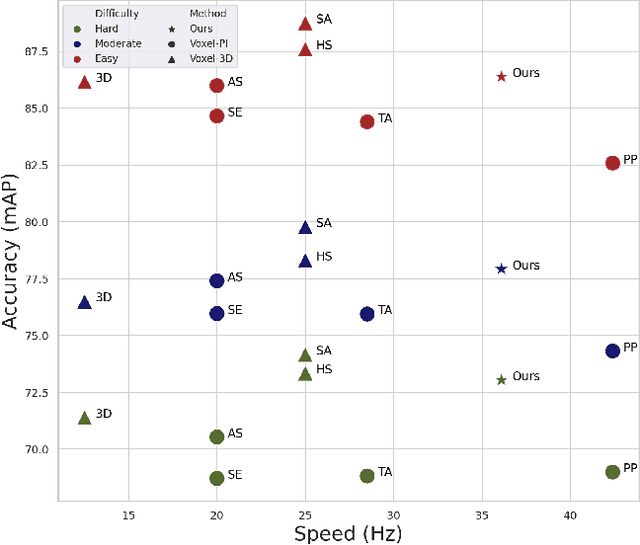
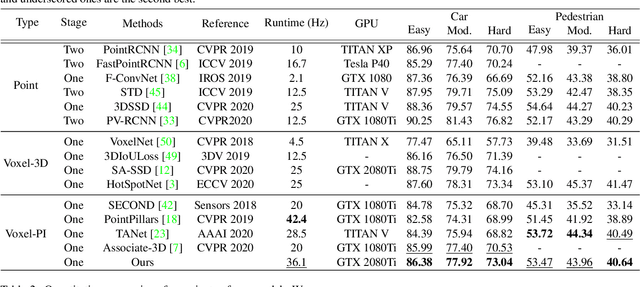
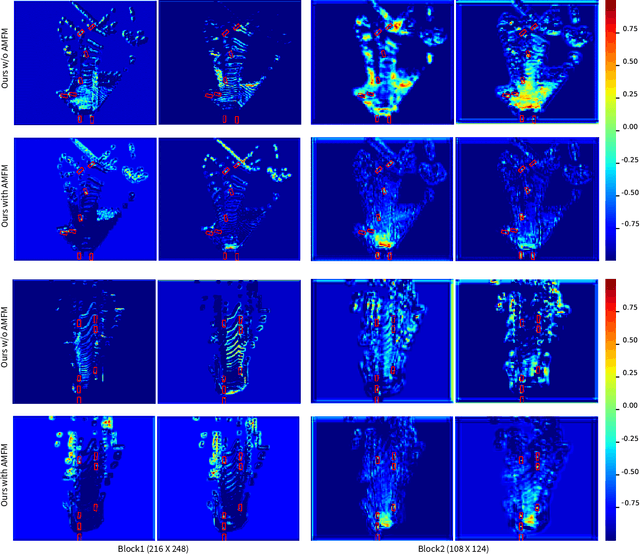
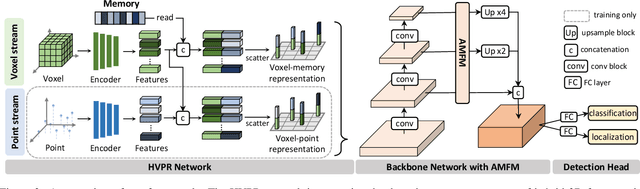
We address the problem of 3D object detection, that is, estimating 3D object bounding boxes from point clouds. 3D object detection methods exploit either voxel-based or point-based features to represent 3D objects in a scene. Voxel-based features are efficient to extract, while they fail to preserve fine-grained 3D structures of objects. Point-based features, on the other hand, represent the 3D structures more accurately, but extracting these features is computationally expensive. We introduce in this paper a novel single-stage 3D detection method having the merit of both voxel-based and point-based features. To this end, we propose a new convolutional neural network (CNN) architecture, dubbed HVPR, that integrates both features into a single 3D representation effectively and efficiently. Specifically, we augment the point-based features with a memory module to reduce the computational cost. We then aggregate the features in the memory, semantically similar to each voxel-based one, to obtain a hybrid 3D representation in a form of a pseudo image, allowing to localize 3D objects in a single stage efficiently. We also propose an Attentive Multi-scale Feature Module (AMFM) that extracts scale-aware features considering the sparse and irregular patterns of point clouds. Experimental results on the KITTI dataset demonstrate the effectiveness and efficiency of our approach, achieving a better compromise in terms of speed and accuracy.
Unsupervised Learning of Deep-Learned Features from Breast Cancer Images
Jun 21, 2020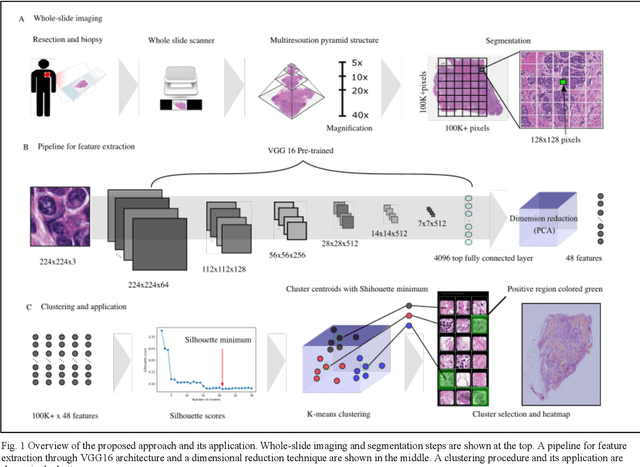
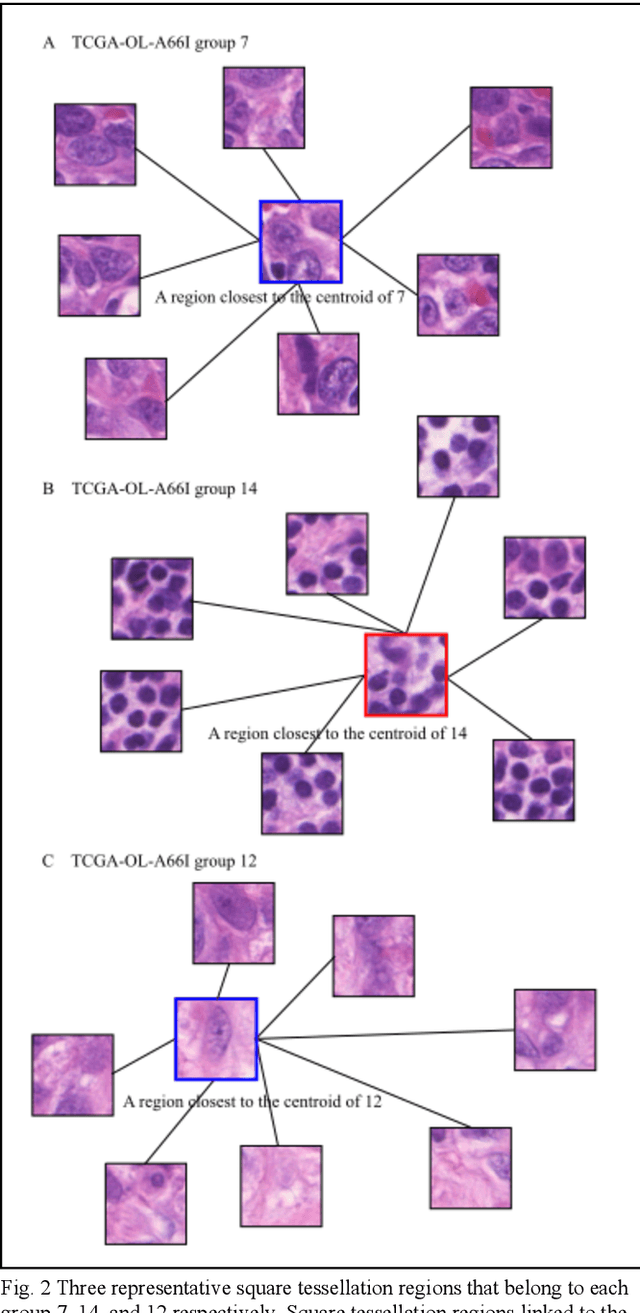
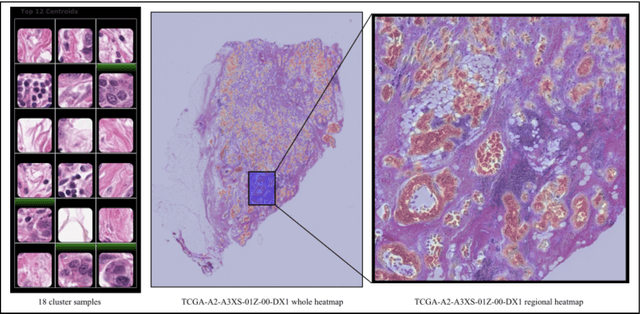
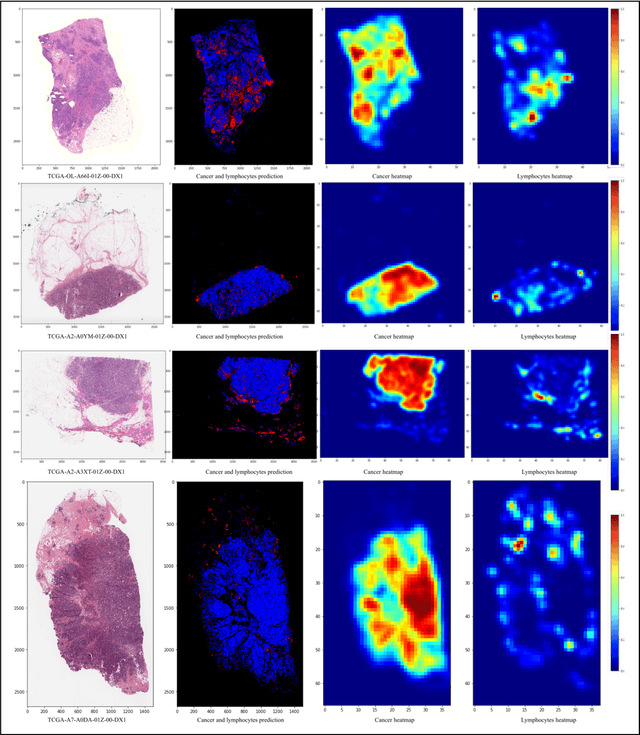
Detecting cancer manually in whole slide images requires significant time and effort on the laborious process. Recent advances in whole slide image analysis have stimulated the growth and development of machine learning-based approaches that improve the efficiency and effectiveness in the diagnosis of cancer diseases. In this paper, we propose an unsupervised learning approach for detecting cancer in breast invasive carcinoma (BRCA) whole slide images. The proposed method is fully automated and does not require human involvement during the unsupervised learning procedure. We demonstrate the effectiveness of the proposed approach for cancer detection in BRCA and show how the machine can choose the most appropriate clusters during the unsupervised learning procedure. Moreover, we present a prototype application that enables users to select relevant groups mapping all regions related to the groups in whole slide images.
HistomicsML2.0: Fast interactive machine learning for whole slide imaging data
Jan 30, 2020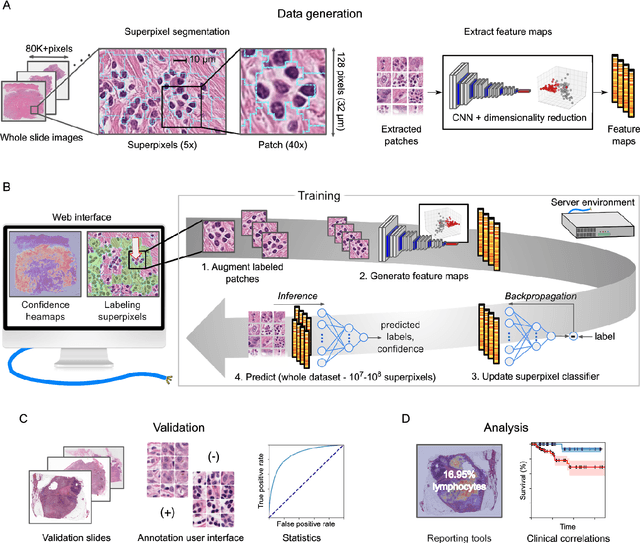
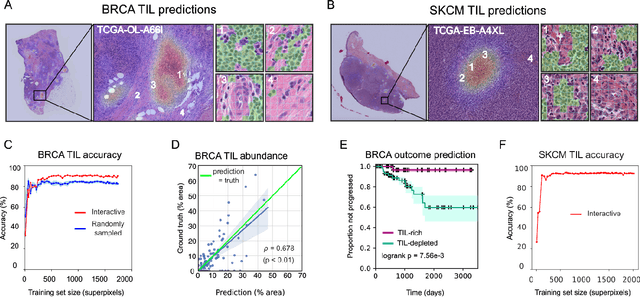
Extracting quantitative phenotypic information from whole-slide images presents significant challenges for investigators who are not experienced in developing image analysis algorithms. We present new software that enables rapid learn-by-example training of machine learning classifiers for detection of histologic patterns in whole-slide imaging datasets. HistomicsML2.0 uses convolutional networks to be readily adaptable to a variety of applications, provides a web-based user interface, and is available as a software container to simplify deployment.
GraphX-Convolution for Point Cloud Deformation in 2D-to-3D Conversion
Nov 15, 2019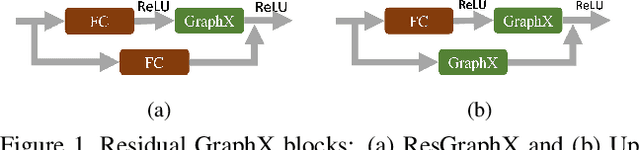
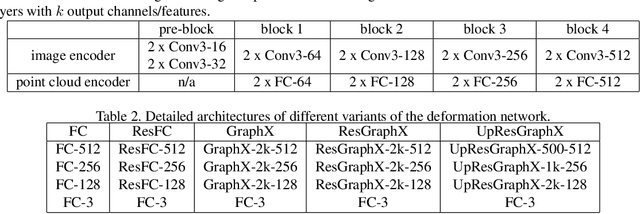
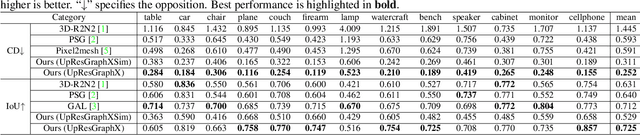
In this paper, we present a novel deep method to reconstruct a point cloud of an object from a single still image. Prior arts in the field struggle to reconstruct an accurate and scalable 3D model due to either the inefficient and expensive 3D representations, the dependency between the output and number of model parameters or the lack of a suitable computing operation. We propose to overcome these by deforming a random point cloud to the object shape through two steps: feature blending and deformation. In the first step, the global and point-specific shape features extracted from a 2D object image are blended with the encoded feature of a randomly generated point cloud, and then this mixture is sent to the deformation step to produce the final representative point set of the object. In the deformation process, we introduce a new layer termed as GraphX that considers the inter-relationship between points like common graph convolutions but operates on unordered sets. Moreover, with a simple trick, the proposed model can generate an arbitrary-sized point cloud, which is the first deep method to do so. Extensive experiments verify that we outperform existing models and halve the state-of-the-art distance score in single image 3D reconstruction.