 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelightable and Dynamic Gaussian Avatar Reconstruction from Monocular Video
Dec 11, 2025Modeling relightable and animatable human avatars from monocular video is a long-standing and challenging task. Recently, Neural Radiance Field (NeRF) and 3D Gaussian Splatting (3DGS) methods have been employed to reconstruct the avatars. However, they often produce unsatisfactory photo-realistic results because of insufficient geometrical details related to body motion, such as clothing wrinkles. In this paper, we propose a 3DGS-based human avatar modeling framework, termed as Relightable and Dynamic Gaussian Avatar (RnD-Avatar), that presents accurate pose-variant deformation for high-fidelity geometrical details. To achieve this, we introduce dynamic skinning weights that define the human avatar's articulation based on pose while also learning additional deformations induced by body motion. We also introduce a novel regularization to capture fine geometric details under sparse visual cues. Furthermore, we present a new multi-view dataset with varied lighting conditions to evaluate relight. Our framework enables realistic rendering of novel poses and views while supporting photo-realistic lighting effects under arbitrary lighting conditions. Our method achieves state-of-the-art performance in novel view synthesis, novel pose rendering, and relighting.
* 8 pages, 9 figures, published in ACM MM 2025
BEAT: Balanced Frequency Adaptive Tuning for Long-Term Time-Series Forecasting
Jan 31, 2025



Time-series forecasting is crucial for numerous real-world applications including weather prediction and financial market modeling. While temporal-domain methods remain prevalent, frequency-domain approaches can effectively capture multi-scale periodic patterns, reduce sequence dependencies, and naturally denoise signals. However, existing approaches typically train model components for all frequencies under a unified training objective, often leading to mismatched learning speeds: high-frequency components converge faster and risk overfitting, while low-frequency components underfit due to insufficient training time. To deal with this challenge, we propose BEAT (Balanced frEquency Adaptive Tuning), a novel framework that dynamically monitors the training status for each frequency and adaptively adjusts their gradient updates. By recognizing convergence, overfitting, or underfitting for each frequency, BEAT dynamically reallocates learning priorities, moderating gradients for rapid learners and increasing those for slower ones, alleviating the tension between competing objectives across frequencies and synchronizing the overall learning process. Extensive experiments on seven real-world datasets demonstrate that BEAT consistently outperforms state-of-the-art approaches.
GraphX-Convolution for Point Cloud Deformation in 2D-to-3D Conversion
Nov 15, 2019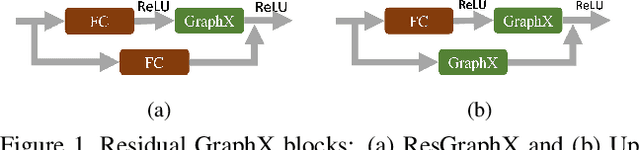
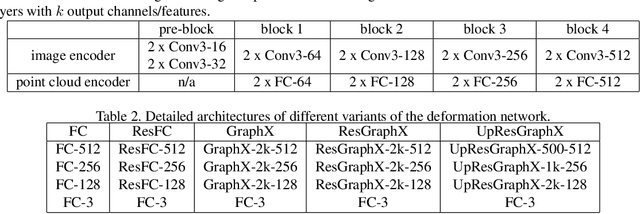
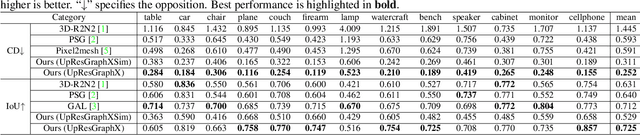
In this paper, we present a novel deep method to reconstruct a point cloud of an object from a single still image. Prior arts in the field struggle to reconstruct an accurate and scalable 3D model due to either the inefficient and expensive 3D representations, the dependency between the output and number of model parameters or the lack of a suitable computing operation. We propose to overcome these by deforming a random point cloud to the object shape through two steps: feature blending and deformation. In the first step, the global and point-specific shape features extracted from a 2D object image are blended with the encoded feature of a randomly generated point cloud, and then this mixture is sent to the deformation step to produce the final representative point set of the object. In the deformation process, we introduce a new layer termed as GraphX that considers the inter-relationship between points like common graph convolutions but operates on unordered sets. Moreover, with a simple trick, the proposed model can generate an arbitrary-sized point cloud, which is the first deep method to do so. Extensive experiments verify that we outperform existing models and halve the state-of-the-art distance score in single image 3D reconstruction.