 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Patch: Exploring Vulnerabilities of Visuomotor Policies via Viewpoint-Consistent 3D Adversarial Object
Mar 05, 2026Neural network-based visuomotor policies enable robots to perform manipulation tasks but remain susceptible to perceptual attacks. For example, conventional 2D adversarial patches are effective under fixed-camera setups, where appearance is relatively consistent; however, their efficacy often diminishes under dynamic viewpoints from moving cameras, such as wrist-mounted setups, due to perspective distortions. To proactively investigate potential vulnerabilities beyond 2D patches, this work proposes a viewpoint-consistent adversarial texture optimization method for 3D objects through differentiable rendering. As optimization strategies, we employ Expectation over Transformation (EOT) with a Coarse-to-Fine (C2F) curriculum, exploiting distance-dependent frequency characteristics to induce textures effective across varying camera-object distances. We further integrate saliency-guided perturbations to redirect policy attention and design a targeted loss that persistently drives robots toward adversarial objects. Our comprehensive experiments show that the proposed method is effective under various environmental conditions, while confirming its black-box transferability and real-world applicability.
GraphX-Convolution for Point Cloud Deformation in 2D-to-3D Conversion
Nov 15, 2019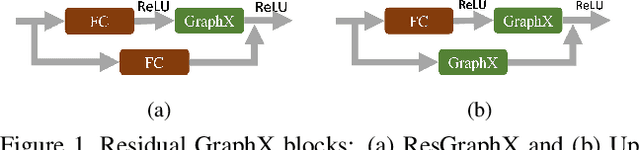
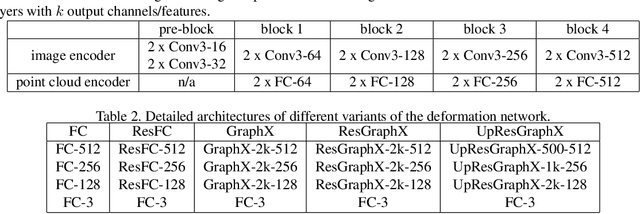
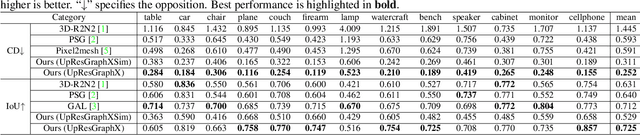
In this paper, we present a novel deep method to reconstruct a point cloud of an object from a single still image. Prior arts in the field struggle to reconstruct an accurate and scalable 3D model due to either the inefficient and expensive 3D representations, the dependency between the output and number of model parameters or the lack of a suitable computing operation. We propose to overcome these by deforming a random point cloud to the object shape through two steps: feature blending and deformation. In the first step, the global and point-specific shape features extracted from a 2D object image are blended with the encoded feature of a randomly generated point cloud, and then this mixture is sent to the deformation step to produce the final representative point set of the object. In the deformation process, we introduce a new layer termed as GraphX that considers the inter-relationship between points like common graph convolutions but operates on unordered sets. Moreover, with a simple trick, the proposed model can generate an arbitrary-sized point cloud, which is the first deep method to do so. Extensive experiments verify that we outperform existing models and halve the state-of-the-art distance score in single image 3D reconstruction.
Video Frame Interpolation by Plug-and-Play Deep Locally Linear Embedding
Jul 04, 2018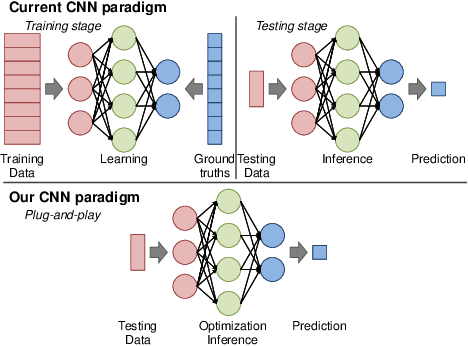
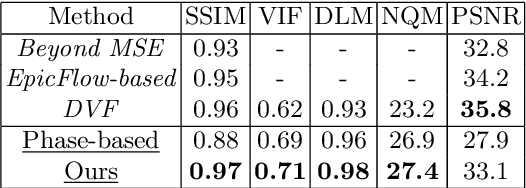
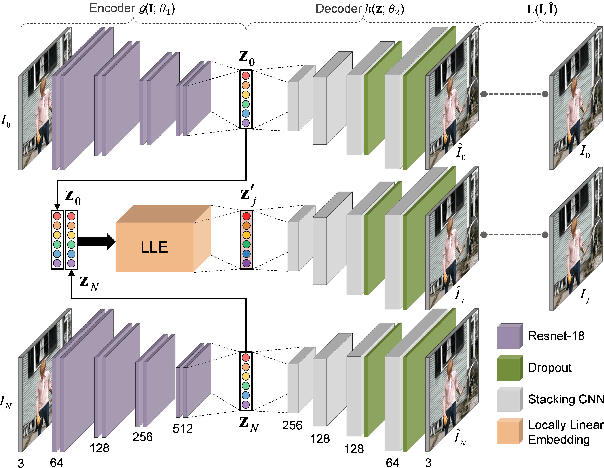
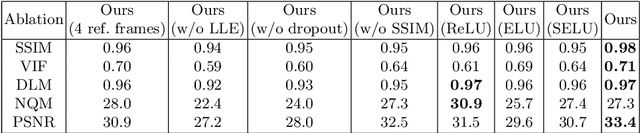
We propose a generative framework which takes on the video frame interpolation problem. Our framework, which we call Deep Locally Linear Embedding (DeepLLE), is powered by a deep convolutional neural network (CNN) while it can be used instantly like conventional models. DeepLLE fits an auto-encoding CNN to a set of several consecutive frames and embeds a linearity constraint on the latent codes so that new frames can be generated by interpolating new latent codes. Different from the current deep learning paradigm which requires training on large datasets, DeepLLE works in a plug-and-play and unsupervised manner, and is able to generate an arbitrary number of frames. Thorough experiments demonstrate that without bells and whistles, our method is highly competitive among current state-of-the-art models.