 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval Augmented Classification for Confidential Documents
Apr 09, 2026Unauthorized disclosure of confidential documents demands robust, low-leakage classification. In real work environments, there is a lot of inflow and outflow of documents. To continuously update knowledge, we propose a methodology for classifying confidential documents using Retrieval Augmented Classification (RAC). To confirm this effectiveness, we compare RAC and supervised fine tuning (FT) on the WikiLeaks US Diplomacy corpus under realistic sequence-length constraints. On balanced data, RAC matches FT. On unbalanced data, RAC is more stable while delivering comparable performance--about 96% Accuracy on both the original (unbalanced) and augmented (balanced) sets, and up to 94% F1 with proper prompting--whereas FT attains 90% F1 trained on the augmented, balanced set but drops to 88% F1 trained on the original, unbalanced set. When robust augmentation is infeasible, RAC provides a practical, security-preserving path to strong classification by keeping sensitive content out of model weights and under your control, and it remains robust as real-world conditions change in class balance, data, context length, or governance requirements. Because RAC grounds decisions in an external vector store with similarity matching, it is less sensitive to label skew, reduces parameter-level leakage, and can incorporate new data immediately via reindexing--a difficult step for FT, which typically requires retraining. The contributions of this paper are threefold: first, a RAC-based classification pipeline and evaluation recipe; second, a controlled study that isolates class imbalance and context-length effects for FT versus RAC in confidential-document grading; and third, actionable guidance on RAC design patterns for governed deployments.
* Appears in: KSII The 17th International Conference on Internet (ICONI) 2025, Dec 2025. 7 pages (48-54)
Unsupervised Learning of Deep-Learned Features from Breast Cancer Images
Jun 21, 2020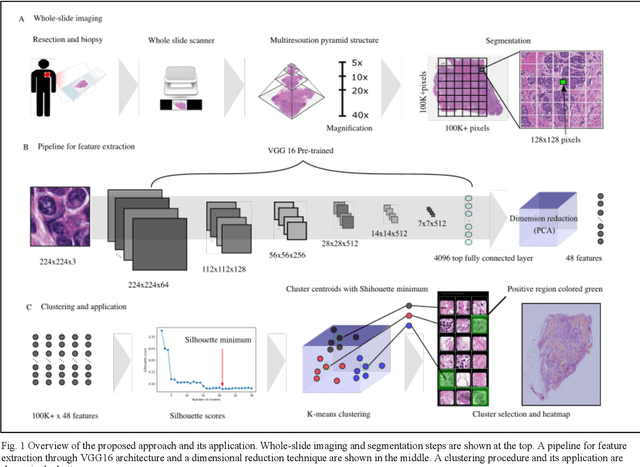
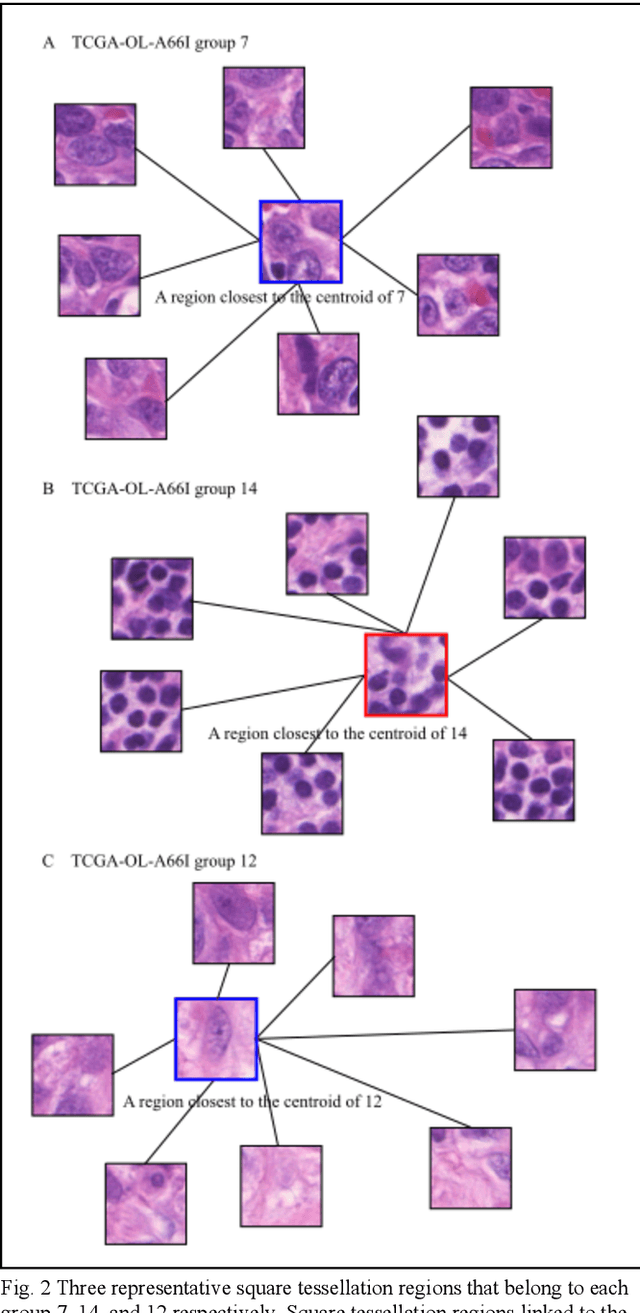
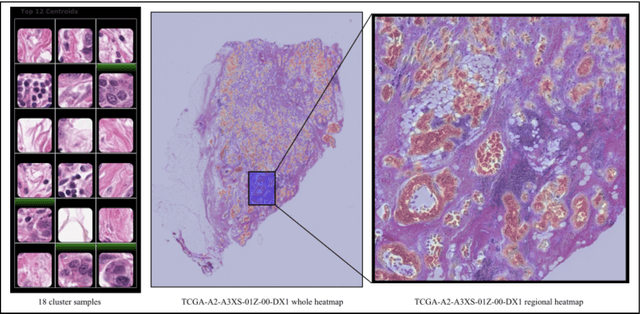
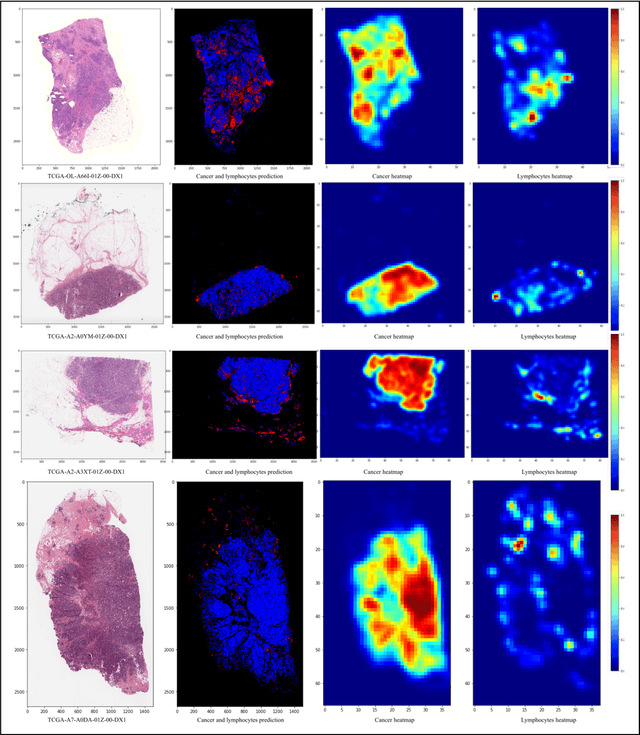
Detecting cancer manually in whole slide images requires significant time and effort on the laborious process. Recent advances in whole slide image analysis have stimulated the growth and development of machine learning-based approaches that improve the efficiency and effectiveness in the diagnosis of cancer diseases. In this paper, we propose an unsupervised learning approach for detecting cancer in breast invasive carcinoma (BRCA) whole slide images. The proposed method is fully automated and does not require human involvement during the unsupervised learning procedure. We demonstrate the effectiveness of the proposed approach for cancer detection in BRCA and show how the machine can choose the most appropriate clusters during the unsupervised learning procedure. Moreover, we present a prototype application that enables users to select relevant groups mapping all regions related to the groups in whole slide images.