 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-Free Multi-Domain Machine Translation with Stage-wise Training
May 06, 2023



Most multi-domain machine translation models rely on domain-annotated data. Unfortunately, domain labels are usually unavailable in both training processes and real translation scenarios. In this work, we propose a label-free multi-domain machine translation model which requires only a few or no domain-annotated data in training and no domain labels in inference. Our model is composed of three parts: a backbone model, a domain discriminator taking responsibility to discriminate data from different domains, and a set of experts that transfer the decoded features from generic to specific. We design a stage-wise training strategy and train the three parts sequentially. To leverage the extra domain knowledge and improve the training stability, in the discriminator training stage, domain differences are modeled explicitly with clustering and distilled into the discriminator through a multi-classification task. Meanwhile, the Gumbel-Max sampling is adopted as the routing scheme in the expert training stage to achieve the balance of each expert in specialization and generalization. Experimental results on the German-to-English translation task show that our model significantly improves BLEU scores on six different domains and even outperforms most of the models trained with domain-annotated data.
Monotonic Simultaneous Translation with Chunk-wise Reordering and Refinement
Oct 18, 2021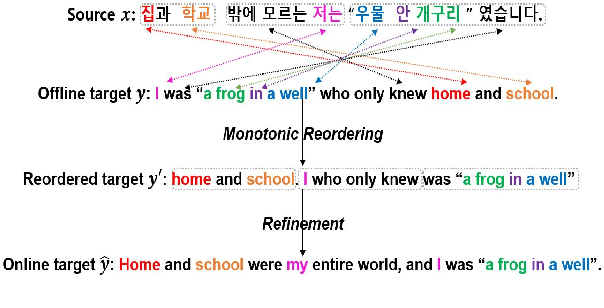
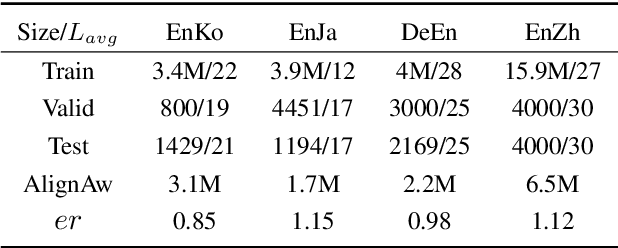
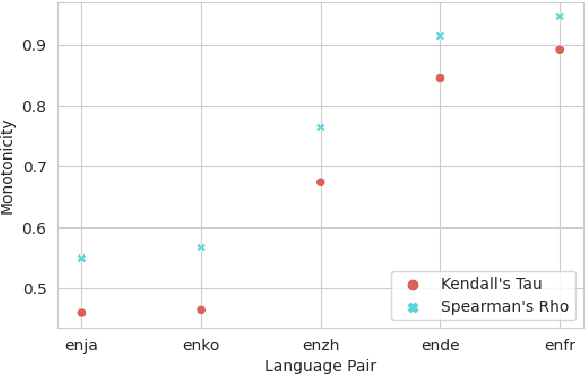
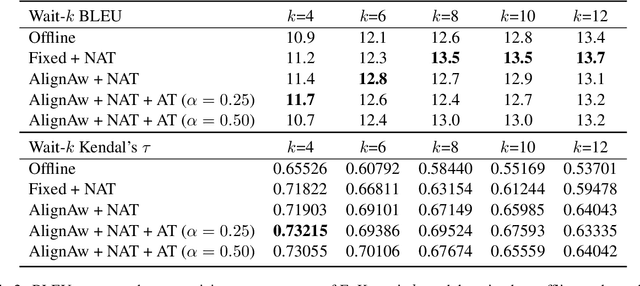
Recent work in simultaneous machine translation is often trained with conventional full sentence translation corpora, leading to either excessive latency or necessity to anticipate as-yet-unarrived words, when dealing with a language pair whose word orders significantly differ. This is unlike human simultaneous interpreters who produce largely monotonic translations at the expense of the grammaticality of a sentence being translated. In this paper, we thus propose an algorithm to reorder and refine the target side of a full sentence translation corpus, so that the words/phrases between the source and target sentences are aligned largely monotonically, using word alignment and non-autoregressive neural machine translation. We then train a widely used wait-k simultaneous translation model on this reordered-and-refined corpus. The proposed approach improves BLEU scores and resulting translations exhibit enhanced monotonicity with source sentences.
Decision Attentive Regularization to Improve Simultaneous Speech Translation Systems
Oct 13, 2021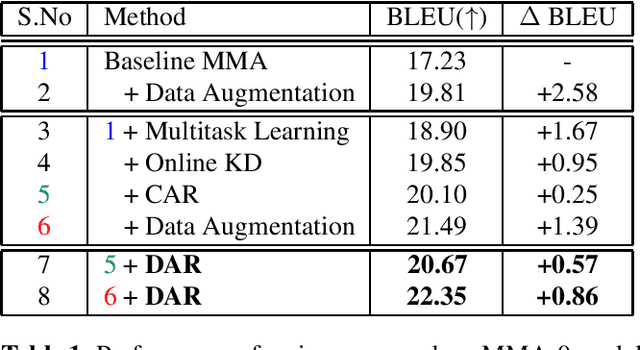
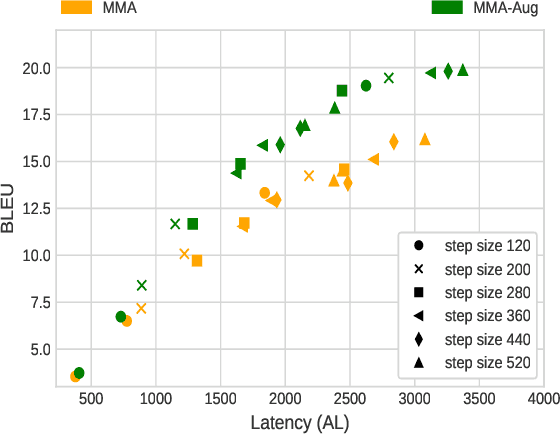
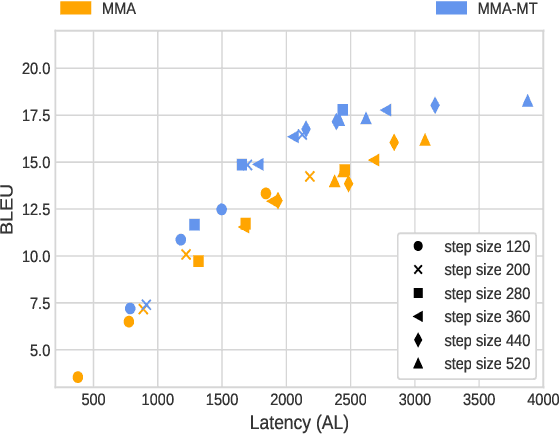
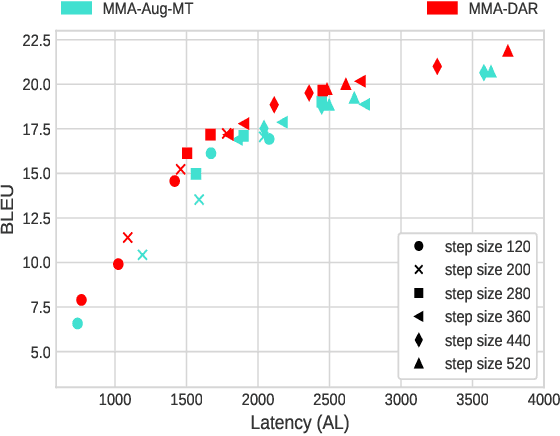
Simultaneous Speech-to-text Translation (SimulST) systems translate source speech in tandem with the speaker using partial input. Recent works have tried to leverage the text translation task to improve the performance of Speech Translation (ST) in the offline domain. Motivated by these improvements, we propose to add Decision Attentive Regularization (DAR) to Monotonic Multihead Attention (MMA) based SimulST systems. DAR improves the read/write decisions for speech using the Simultaneous text Translation (SimulMT) task. We also extend several techniques from the offline domain to the SimulST task. Our proposed system achieves significant performance improvements for the MuST-C English-German (EnDe) SimulST task, where we provide an average BLUE score improvement of around 4.57 points or 34.17% across different latencies. Further, the latency-quality tradeoffs establish that the proposed model achieves better results compared to the baseline.
Infusing Future Information into Monotonic Attention Through Language Models
Sep 07, 2021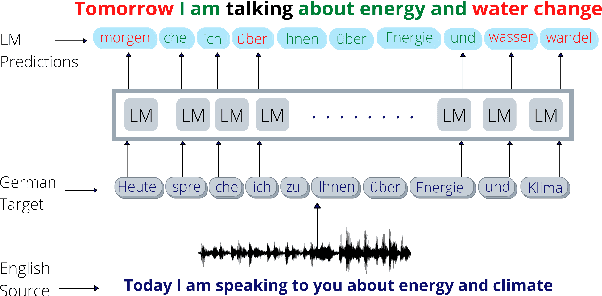

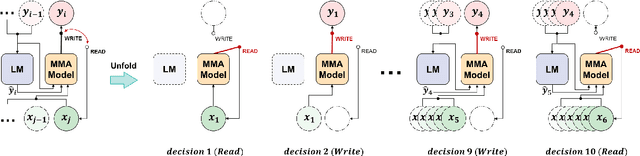
Simultaneous neural machine translation(SNMT) models start emitting the target sequence before they have processed the source sequence. The recent adaptive policies for SNMT use monotonic attention to perform read/write decisions based on the partial source and target sequences. The lack of sufficient information might cause the monotonic attention to take poor read/write decisions, which in turn negatively affects the performance of the SNMT model. On the other hand, human translators make better read/write decisions since they can anticipate the immediate future words using linguistic information and domain knowledge.Motivated by human translators, in this work, we propose a framework to aid monotonic attention with an external language model to improve its decisions.We conduct experiments on the MuST-C English-German and English-French speech-to-text translation tasks to show the effectiveness of the proposed framework.The proposed SNMT method improves the quality-latency trade-off over the state-of-the-art monotonic multihead attention.
Faster Re-translation Using Non-Autoregressive Model For Simultaneous Neural Machine Translation
Dec 29, 2020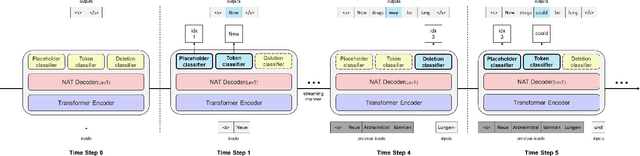

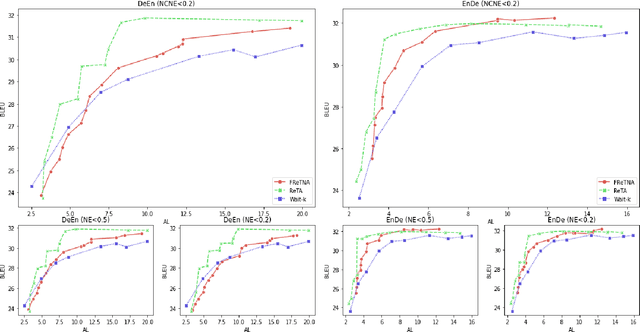
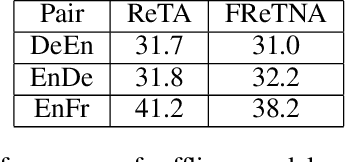
Recently, simultaneous translation has gathered a lot of attention since it enables compelling applications such as subtitle translation for a live event or real-time video-call translation. Some of these translation applications allow editing of partial translation giving rise to re-translation approaches. The current re-translation approaches are based on autoregressive sequence generation models (ReTA), which generate tar-get tokens in the (partial) translation sequentially. The multiple re-translations with sequential generation inReTAmodelslead to an increased inference time gap between the incoming source input and the corresponding target output as the source input grows. Besides, due to the large number of inference operations involved, the ReTA models are not favorable for resource-constrained devices. In this work, we propose a faster re-translation system based on a non-autoregressive sequence generation model (FReTNA) to overcome the aforementioned limitations. We evaluate the proposed model on multiple translation tasks and our model reduces the inference times by several orders and achieves a competitive BLEUscore compared to the ReTA and streaming (Wait-k) models.The proposed model reduces the average computation time by a factor of 20 when compared to the ReTA model by incurring a small drop in the translation quality. It also outperforms the streaming-based Wait-k model both in terms of computation time (1.5 times lower) and translation quality.
Extremely Low Bit Transformer Quantization for On-Device Neural Machine Translation
Oct 13, 2020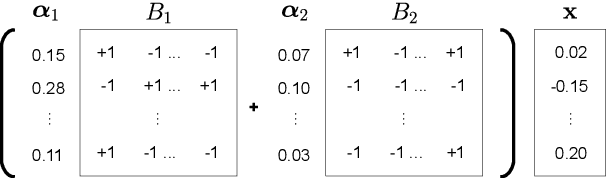
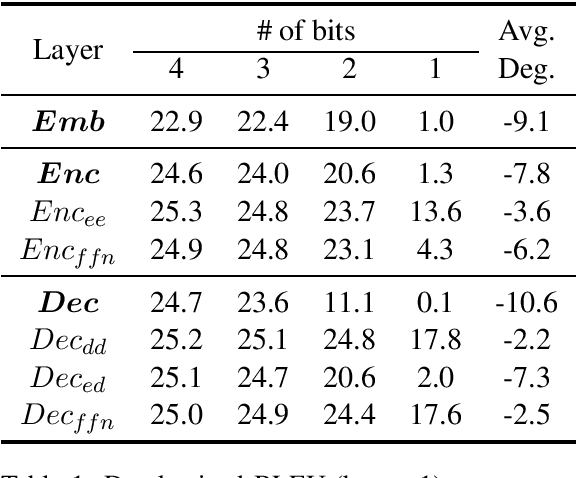
The deployment of widely used Transformer architecture is challenging because of heavy computation load and memory overhead during inference, especially when the target device is limited in computational resources such as mobile or edge devices. Quantization is an effective technique to address such challenges. Our analysis shows that for a given number of quantization bits, each block of Transformer contributes to translation quality and inference computations in different manners. Moreover, even inside an embedding block, each word presents vastly different contributions. Correspondingly, we propose a mixed precision quantization strategy to represent Transformer weights by an extremely low number of bits (e.g., under 3 bits). For example, for each word in an embedding block, we assign different quantization bits based on statistical property. Our quantized Transformer model achieves 11.8$\times$ smaller model size than the baseline model, with less than -0.5 BLEU. We achieve 8.3$\times$ reduction in run-time memory footprints and 3.5$\times$ speed up (Galaxy N10+) such that our proposed compression strategy enables efficient implementation for on-device NMT.
Data Efficient Direct Speech-to-Text Translation with Modality Agnostic Meta-Learning
Nov 11, 2019

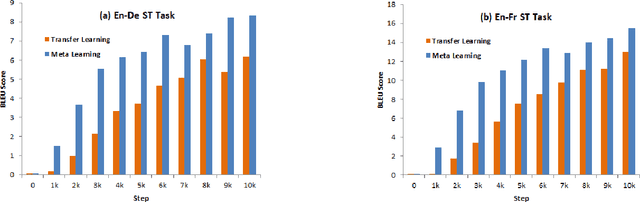
End-to-end Speech Translation (ST) models have several advantages such as lower latency, smaller model size, and less error compounding over conventional pipelines that combine Automatic Speech Recognition (ASR) and text Machine Translation (MT) models. However, collecting large amounts of parallel data for ST task is more difficult compared to the ASR and MT tasks. Previous studies have proposed the use of transfer learning approaches to overcome the above difficulty. These approaches benefit from weakly supervised training data, such as ASR speech-to-transcript or MT text-to-text translation pairs. However, the parameters in these models are updated independently of each task, which may lead to sub-optimal solutions. In this work, we adopt a meta-learning algorithm to train a modality agnostic multi-task model that transfers knowledge from source tasks=ASR+MT to target task=ST where ST task severely lacks data. In the meta-learning phase, the parameters of the model are exposed to vast amounts of speech transcripts (e.g., English ASR) and text translations (e.g., English-German MT). During this phase, parameters are updated in such a way to understand speech, text representations, the relation between them, as well as act as a good initialization point for the target ST task. We evaluate the proposed meta-learning approach for ST tasks on English-German (En-De) and English-French (En-Fr) language pairs from the Multilingual Speech Translation Corpus (MuST-C). Our method outperforms the previous transfer learning approaches and sets new state-of-the-art results for En-De and En-Fr ST tasks by obtaining 9.18, and 11.76 BLEU point improvements, respectively.