 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Re-translation Using Non-Autoregressive Model For Simultaneous Neural Machine Translation
Paper and Code
Dec 29, 2020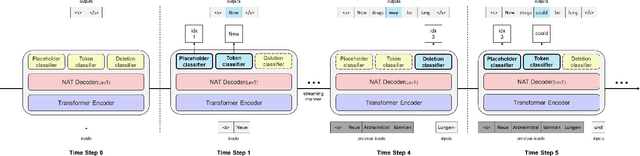

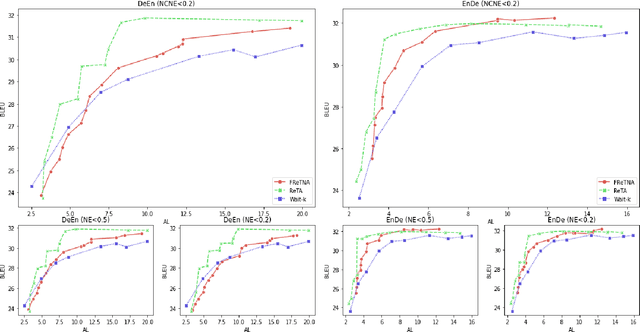
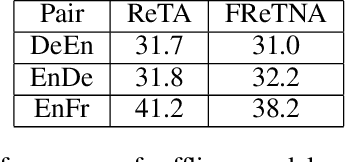
Recently, simultaneous translation has gathered a lot of attention since it enables compelling applications such as subtitle translation for a live event or real-time video-call translation. Some of these translation applications allow editing of partial translation giving rise to re-translation approaches. The current re-translation approaches are based on autoregressive sequence generation models (ReTA), which generate tar-get tokens in the (partial) translation sequentially. The multiple re-translations with sequential generation inReTAmodelslead to an increased inference time gap between the incoming source input and the corresponding target output as the source input grows. Besides, due to the large number of inference operations involved, the ReTA models are not favorable for resource-constrained devices. In this work, we propose a faster re-translation system based on a non-autoregressive sequence generation model (FReTNA) to overcome the aforementioned limitations. We evaluate the proposed model on multiple translation tasks and our model reduces the inference times by several orders and achieves a competitive BLEUscore compared to the ReTA and streaming (Wait-k) models.The proposed model reduces the average computation time by a factor of 20 when compared to the ReTA model by incurring a small drop in the translation quality. It also outperforms the streaming-based Wait-k model both in terms of computation time (1.5 times lower) and translation quality.