 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantics-Preserving Adversarial Training
Sep 23, 2020



Adversarial training is a defense technique that improves adversarial robustness of a deep neural network (DNN) by including adversarial examples in the training data. In this paper, we identify an overlooked problem of adversarial training in that these adversarial examples often have different semantics than the original data, introducing unintended biases into the model. We hypothesize that such non-semantics-preserving (and resultingly ambiguous) adversarial data harm the robustness of the target models. To mitigate such unintended semantic changes of adversarial examples, we propose semantics-preserving adversarial training (SPAT) which encourages perturbation on the pixels that are shared among all classes when generating adversarial examples in the training stage. Experiment results show that SPAT improves adversarial robustness and achieves state-of-the-art results in CIFAR-10 and CIFAR-100.
IDS at SemEval-2020 Task 10: Does Pre-trained Language Model Know What to Emphasize?
Jul 24, 2020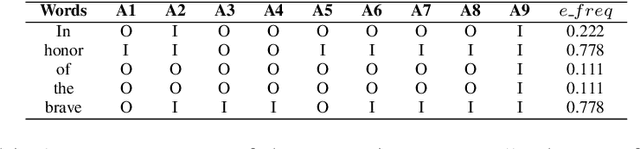

We propose a novel method that enables us to determine words that deserve to be emphasized from written text in visual media, relying only on the information from the self-attention distributions of pre-trained language models (PLMs). With extensive experiments and analyses, we show that 1) our zero-shot approach is superior to a reasonable baseline that adopts TF-IDF and that 2) there exist several attention heads in PLMs specialized for emphasis selection, confirming that PLMs are capable of recognizing important words in sentences.
Multilingual Zero-shot Constituency Parsing
Apr 08, 2020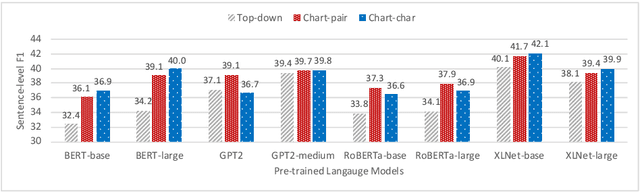
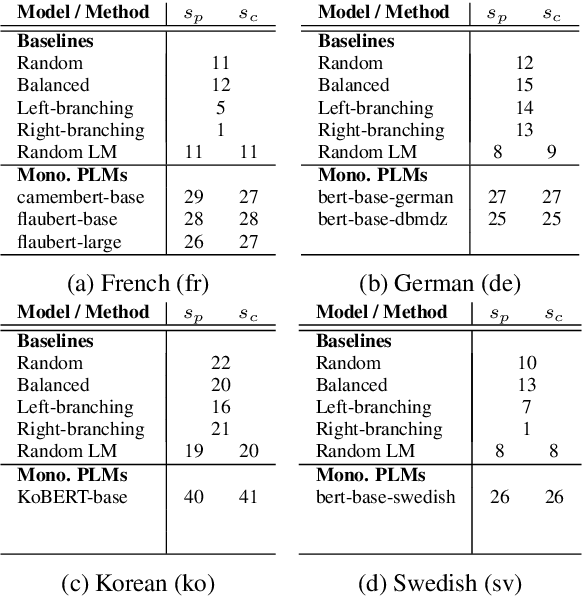
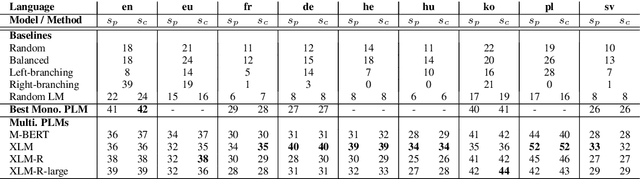
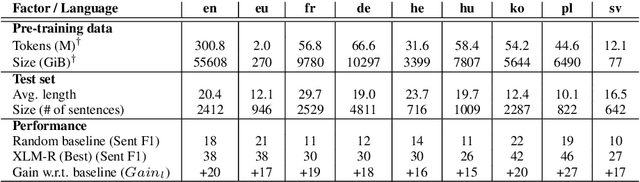
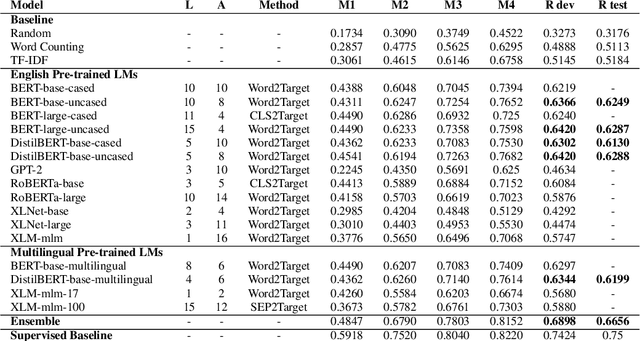
Zero-shot constituency parsing aims to extract parse trees from neural models such as pre-trained language models (PLMs) without further training or the need to train an additional parser. This paper improves upon existing zero-shot parsing paradigms by introducing a novel chart-based parsing method, showing gains in zero-shot parsing performance. Furthermore, we attempt to broaden the range of zero-shot parsing applications by examining languages other than English and by utilizing multilingual models, demonstrating that it is feasible to generate parse tree-like structures for sentences in eight other languages using our method.
Variational Hierarchical Dialog Autoencoder for Dialog State Tracking Data Augmentation
Feb 07, 2020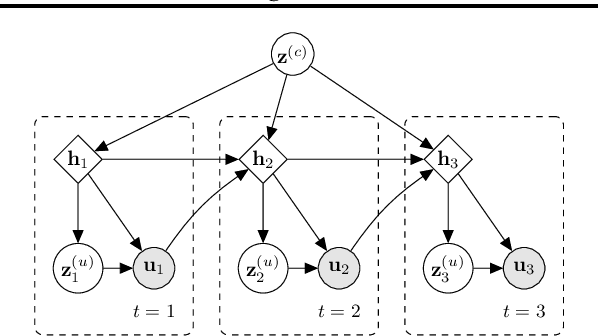
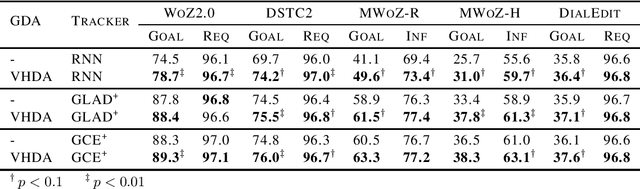
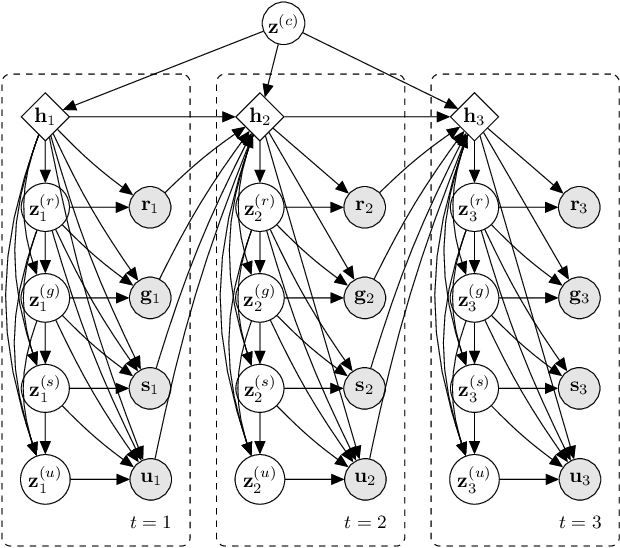
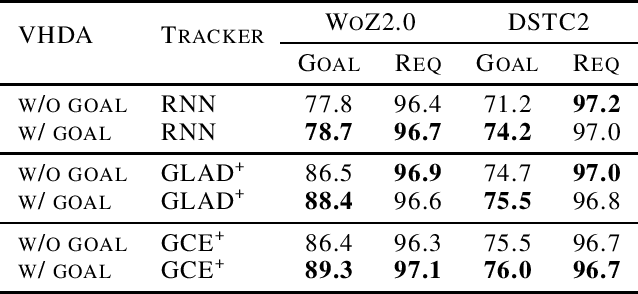
Recent works have shown that generative data augmentation, where synthetic samples generated from deep generative models are used to augment the training dataset, benefit certain NLP tasks. In this work, we extend this approach to the task of dialog state tracking for goal-oriented dialogs. Since, goal-oriented dialogs naturally exhibit a hierarchical structure over utterances and related annotations, deep generative data augmentation for the task requires the generative model to be aware of the hierarchical nature. We propose the Variational Hierarchical Dialog Autoencoder (VHDA) for modeling complete aspects of goal-oriented dialogs, including linguistic features and underlying structured annotations, namely dialog acts and goals. We also propose two training policies to mitigate issues that arise with training VAE-based models. Experiments show that our hierarchical model is able to generate realistic and novel samples that improve the robustness of state-of-the-art dialog state trackers, ultimately improving the dialog state tracking performances on various dialog domains. Surprisingly, the ability to jointly generate dialog features enables our model to outperform previous state-of-the-arts in related subtasks, such as language generation and user simulation.
Are Pre-trained Language Models Aware of Phrases? Simple but Strong Baselines for Grammar Induction
Jan 30, 2020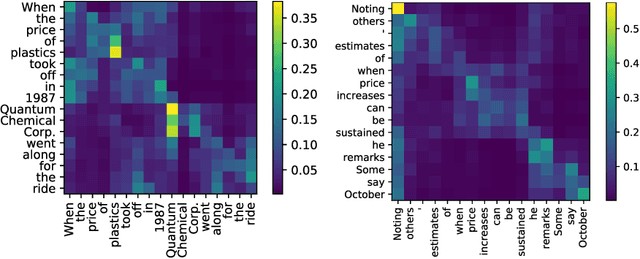
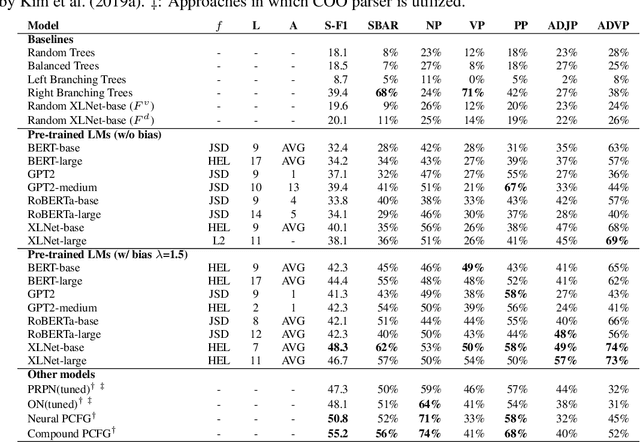
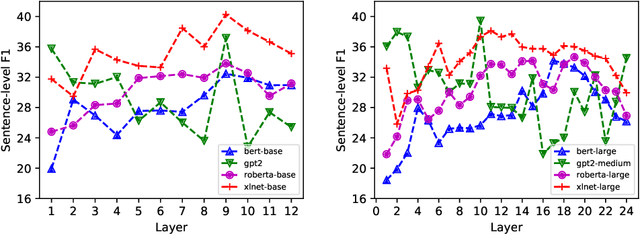
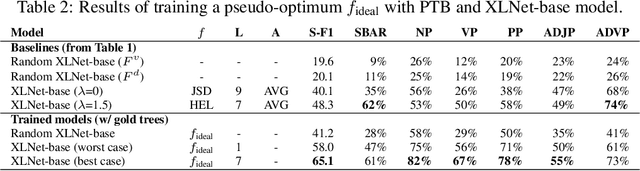
With the recent success and popularity of pre-trained language models (LMs) in natural language processing, there has been a rise in efforts to understand their inner workings. In line with such interest, we propose a novel method that assists us in investigating the extent to which pre-trained LMs capture the syntactic notion of constituency. Our method provides an effective way of extracting constituency trees from the pre-trained LMs without training. In addition, we report intriguing findings in the induced trees, including the fact that pre-trained LMs outperform other approaches in correctly demarcating adverb phrases in sentences.
Summary Level Training of Sentence Rewriting for Abstractive Summarization
Sep 26, 2019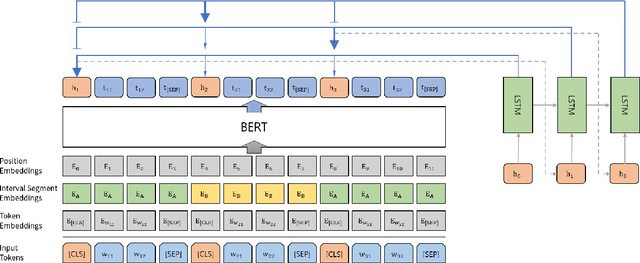
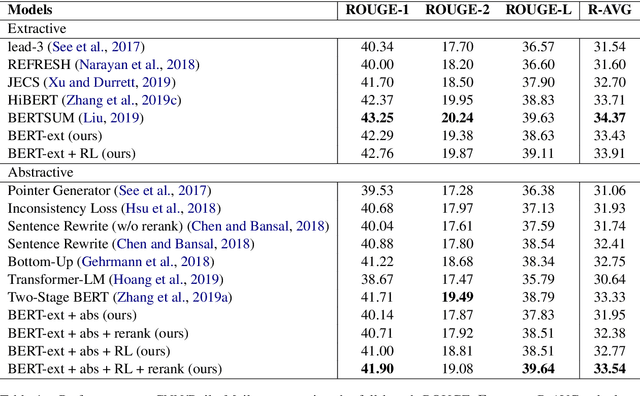
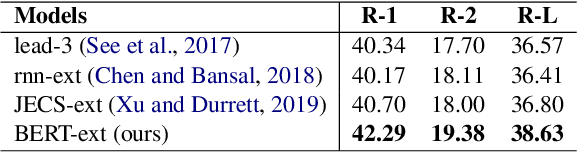
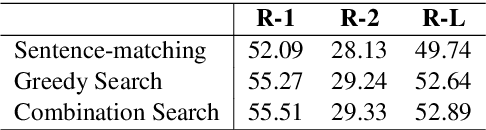
As an attempt to combine extractive and abstractive summarization, Sentence Rewriting models adopt the strategy of extracting salient sentences from a document first and then paraphrasing the selected ones to generate a summary. However, the existing models in this framework mostly rely on sentence-level rewards or suboptimal labels, causing a mismatch between a training objective and evaluation metric. In this paper, we present a novel training signal that directly maximizes summary-level ROUGE scores through reinforcement learning. In addition, we incorporate BERT into our model, making good use of its ability on natural language understanding. In extensive experiments, we show that a combination of our proposed model and training procedure obtains new state-of-the-art performance on both CNN/Daily Mail and New York Times datasets. We also demonstrate that it generalizes better on DUC-2002 test set.
Don't Just Scratch the Surface: Enhancing Word Representations for Korean with Hanja
Aug 27, 2019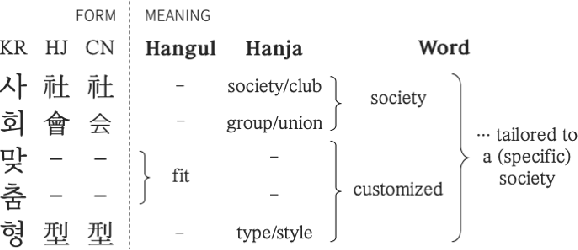
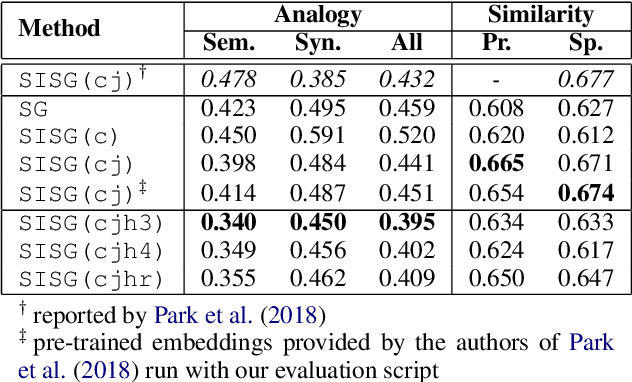
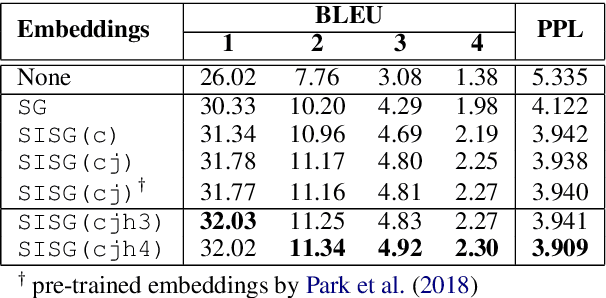
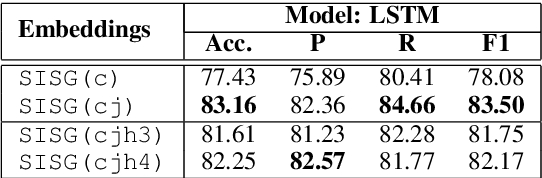
We propose a simple yet effective approach for improving Korean word representations using additional linguistic annotation (i.e. Hanja). We employ cross-lingual transfer learning in training word representations by leveraging the fact that Hanja is closely related to Chinese. We evaluate the intrinsic quality of representations learned through our approach using the word analogy and similarity tests. In addition, we demonstrate their effectiveness on several downstream tasks, including a novel Korean news headline generation task.
A Cross-Sentence Latent Variable Model for Semi-Supervised Text Sequence Matching
Jun 04, 2019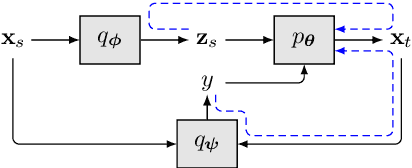
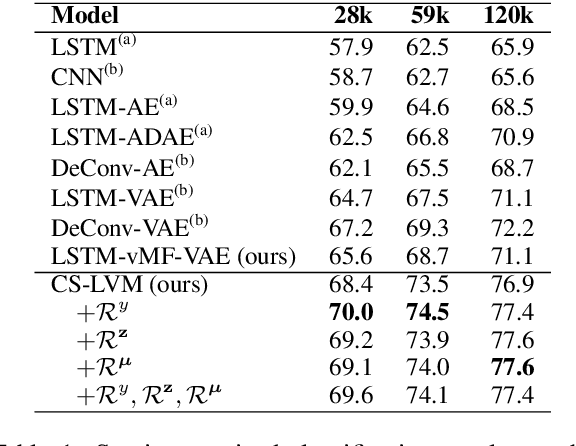
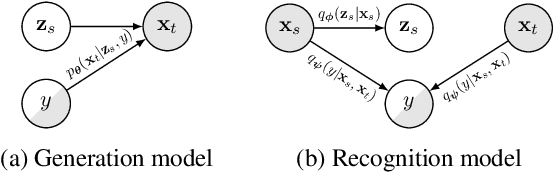
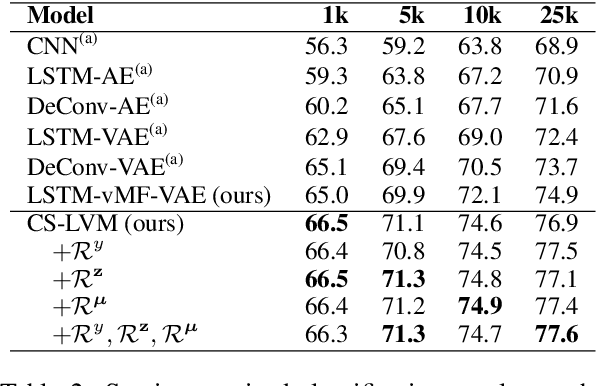
We present a latent variable model for predicting the relationship between a pair of text sequences. Unlike previous auto-encoding--based approaches that consider each sequence separately, our proposed framework utilizes both sequences within a single model by generating a sequence that has a given relationship with a source sequence. We further extend the cross-sentence generating framework to facilitate semi-supervised training. We also define novel semantic constraints that lead the decoder network to generate semantically plausible and diverse sequences. We demonstrate the effectiveness of the proposed model from quantitative and qualitative experiments, while achieving state-of-the-art results on semi-supervised natural language inference and paraphrase identification.
SNU_IDS at SemEval-2019 Task 3: Addressing Training-Test Class Distribution Mismatch in Conversational Classification
Apr 01, 2019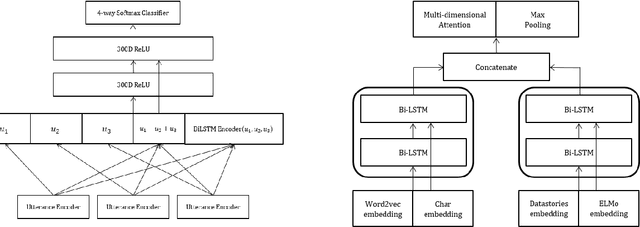
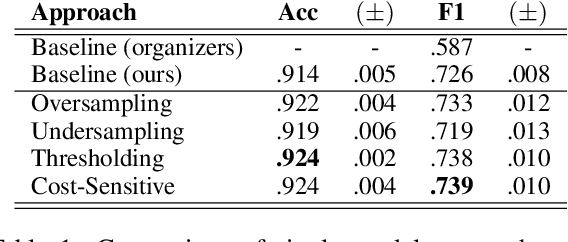
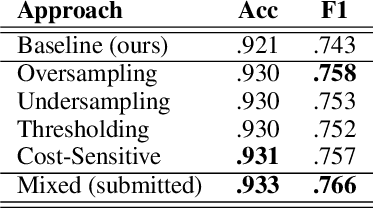
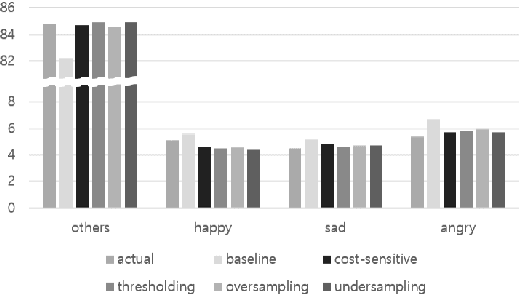
We present several techniques to tackle the mismatch in class distributions between training and test data in the Contextual Emotion Detection task of SemEval 2019, by extending the existing methods for class imbalance problem. Reducing the distance between the distribution of prediction and ground truth, they consistently show positive effects on the performance. Also we propose a novel neural architecture which utilizes representation of overall context as well as of each utterance. The combination of the methods and the models achieved micro F1 score of about 0.766 on the final evaluation.
Data Augmentation for Spoken Language Understanding via Joint Variational Generation
Nov 06, 2018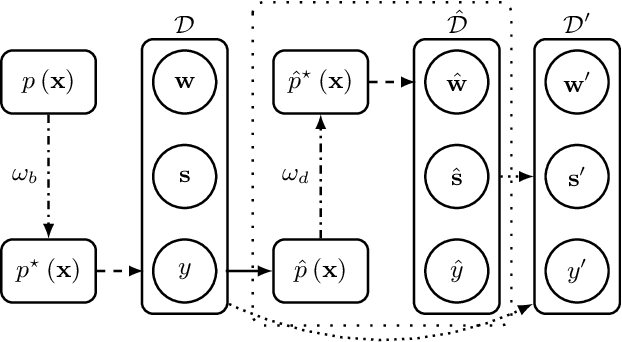
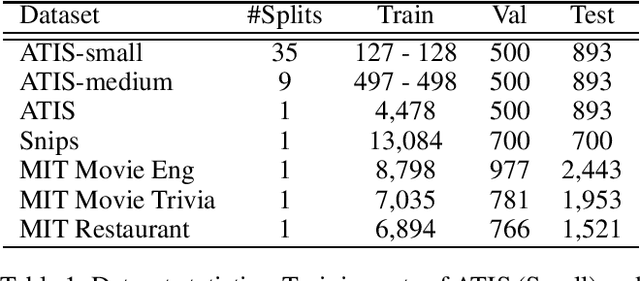
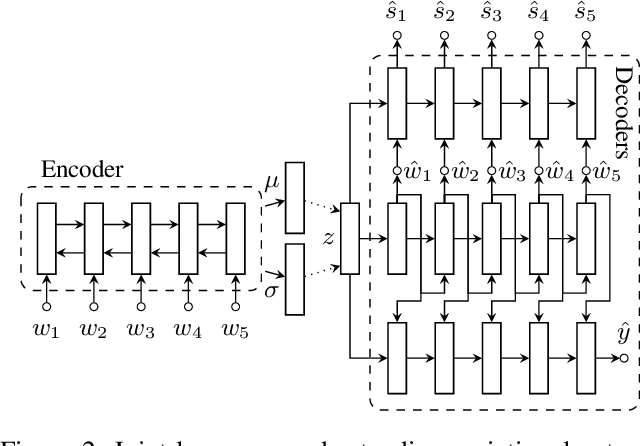
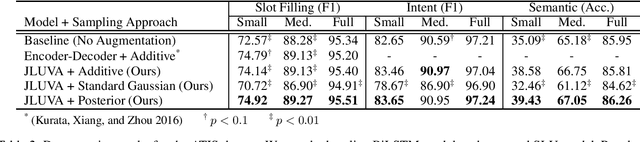
Data scarcity is one of the main obstacles of domain adaptation in spoken language understanding (SLU) due to the high cost of creating manually tagged SLU datasets. Recent works in neural text generative models, particularly latent variable models such as variational autoencoder (VAE), have shown promising results in regards to generating plausible and natural sentences. In this paper, we propose a novel generative architecture which leverages the generative power of latent variable models to jointly synthesize fully annotated utterances. Our experiments show that existing SLU models trained on the additional synthetic examples achieve performance gains. Our approach not only helps alleviate the data scarcity issue in the SLU task for many datasets but also indiscriminately improves language understanding performances for various SLU models, supported by extensive experiments and rigorous statistical testing.