 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation for Spoken Language Understanding via Joint Variational Generation
Nov 06, 2018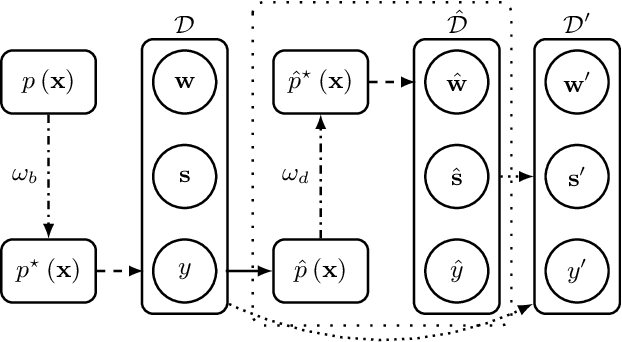
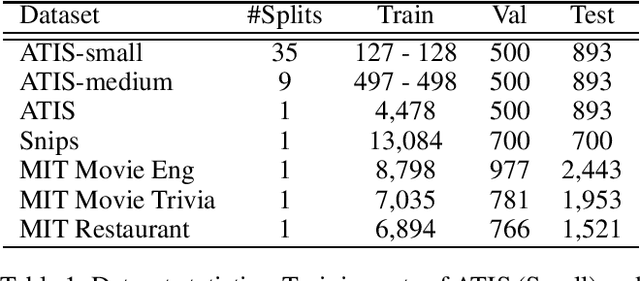
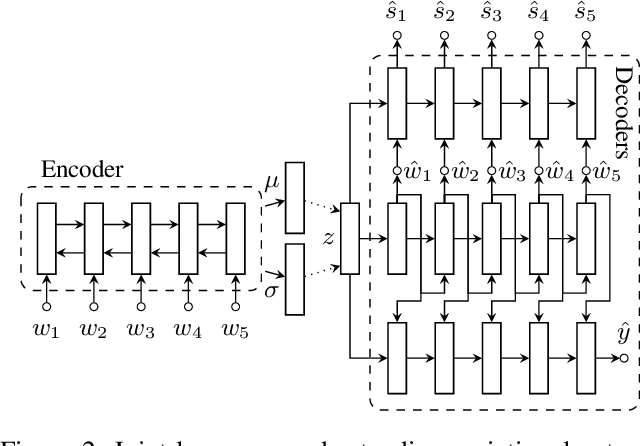
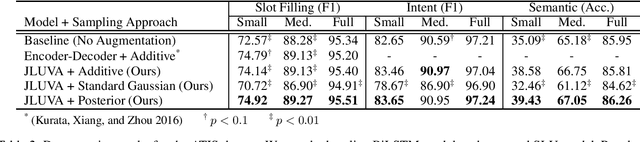
Data scarcity is one of the main obstacles of domain adaptation in spoken language understanding (SLU) due to the high cost of creating manually tagged SLU datasets. Recent works in neural text generative models, particularly latent variable models such as variational autoencoder (VAE), have shown promising results in regards to generating plausible and natural sentences. In this paper, we propose a novel generative architecture which leverages the generative power of latent variable models to jointly synthesize fully annotated utterances. Our experiments show that existing SLU models trained on the additional synthetic examples achieve performance gains. Our approach not only helps alleviate the data scarcity issue in the SLU task for many datasets but also indiscriminately improves language understanding performances for various SLU models, supported by extensive experiments and rigorous statistical testing.
Improving Visually Grounded Sentence Representations with Self-Attention
Dec 02, 2017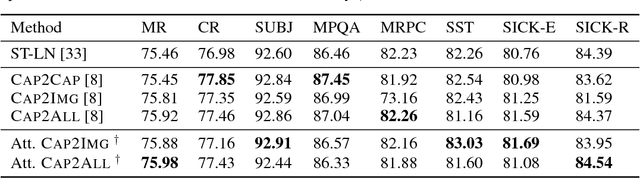

Sentence representation models trained only on language could potentially suffer from the grounding problem. Recent work has shown promising results in improving the qualities of sentence representations by jointly training them with associated image features. However, the grounding capability is limited due to distant connection between input sentences and image features by the design of the architecture. In order to further close the gap, we propose applying self-attention mechanism to the sentence encoder to deepen the grounding effect. Our results on transfer tasks show that self-attentive encoders are better for visual grounding, as they exploit specific words with strong visual associations.