 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCTolyzer: Fully automatic analysis toolkit for segmentation and feature extracting in optical coherence tomography (OCT) and scanning laser ophthalmoscopy (SLO) data
Jul 19, 2024Purpose: To describe OCTolyzer: an open-source toolkit for retinochoroidal analysis in optical coherence tomography (OCT) and scanning laser ophthalmoscopy (SLO) images. Method: OCTolyzer has two analysis suites, for SLO and OCT images. The former enables anatomical segmentation and feature measurement of the en face retinal vessels. The latter leverages image metadata for retinal layer segmentations and deep learning-based choroid layer segmentation to compute retinochoroidal measurements such as thickness and volume. We introduce OCTolyzer and assess the reproducibility of its OCT analysis suite for choroid analysis. Results: At the population-level, choroid region metrics were highly reproducible (Mean absolute error/Pearson/Spearman correlation for macular volume choroid thickness (CT):6.7$\mu$m/0.9933/0.9969, macular B-scan CT:11.6$\mu$m/0.9858/0.9889, peripapillary CT:5.0$\mu$m/0.9942/0.9940). Macular choroid vascular index (CVI) had good reproducibility (volume CVI:0.0271/0.9669/0.9655, B-scan CVI:0.0130/0.9090/0.9145). At the eye-level, measurement error in regional and vessel metrics were below 5% and 20% of the population's variability, respectively. Major outliers were from poor quality B-scans with thick choroids and invisible choroid-sclera boundary. Conclusions: OCTolyzer is the first open-source pipeline to convert OCT/SLO data into reproducible and clinically meaningful retinochoroidal measurements. OCT processing on a standard laptop CPU takes under 2 seconds for macular or peripapillary B-scans and 85 seconds for volume scans. OCTolyzer can help improve standardisation in the field of OCT/SLO image analysis and is freely available here: https://github.com/jaburke166/OCTolyzer.
SLOctolyzer: Fully automatic analysis toolkit for segmentation and feature extracting in scanning laser ophthalmoscopy images
Jun 24, 2024



Purpose: To describe SLOctolyzer: an open-source analysis toolkit for en face retinal vessels appearing in infrared reflectance scanning laser ophthalmoscopy (SLO) images. Methods: SLOctolyzer includes two main modules: segmentation and measurement. The segmentation module use deep learning methods to delineate retinal anatomy, while the measurement module quantifies key retinal vascular features such as vessel complexity, density, tortuosity, and calibre. We evaluate the segmentation module using unseen data and measure its reproducibility. Results: SLOctolyzer's segmentation module performed well against unseen internal test data (Dice for all-vessels, 0.9097; arteries, 0.8376; veins, 0.8525; optic disc, 0.9430; fovea, 0.8837). External validation against severe retinal pathology showed decreased performance (Dice for arteries, 0.7180; veins, 0.7470; optic disc, 0.9032). SLOctolyzer had good reproducibility (mean difference for fractal dimension, -0.0007; vessel density, -0.0003; vessel calibre, -0.3154 $\mu$m; tortuosity density, 0.0013). SLOctolyzer can process a macula-centred SLO image in under 20 seconds and a disc-centred SLO image in under 30 seconds using a standard laptop CPU. Conclusions: To our knowledge, SLOctolyzer is the first open-source tool to convert raw SLO images into reproducible and clinically meaningful retinal vascular parameters. SLO images are captured simultaneous to optical coherence tomography (OCT), and we believe our software will be useful for extracting retinal vascular measurements from large OCT image sets and linking them to ocular or systemic diseases. It requires no specialist knowledge or proprietary software, and allows manual correction of segmentations and re-computing of vascular metrics. SLOctolyzer is freely available at https://github.com/jaburke166/SLOctolyzer.
A publicly available vessel segmentation algorithm for SLO images
Nov 29, 2023



Background and Objective: Infra-red scanning laser ophthalmoscope (IRSLO) images are akin to colour fundus photographs in displaying the posterior pole and retinal vasculature fine detail. While there are many trained networks readily available for retinal vessel segmentation in colour fundus photographs, none cater to IRSLO images. Accordingly, we aimed to develop (and release as open source) a vessel segmentation algorithm tailored specifically to IRSLO images. Materials and Methods: We used 23 expertly annotated IRSLO images from the RAVIR dataset, combined with 7 additional images annotated in-house. We trained a U-Net (convolutional neural network) to label pixels as 'vessel' or 'background'. Results: On an unseen test set (4 images), our model achieved an AUC of 0.981, and an AUPRC of 0.815. Upon thresholding, it achieved a sensitivity of 0.844, a specificity of 0.983, and an F1 score of 0.857. Conclusion: We have made our automatic segmentation algorithm publicly available and easy to use. Researchers can use the generated vessel maps to compute metrics such as fractal dimension and vessel density.
A method for quantifying sectoral optic disc pallor in fundus photographs and its association with peripapillary RNFL thickness
Nov 13, 2023



Purpose: To develop an automatic method of quantifying optic disc pallor in fundus photographs and determine associations with peripapillary retinal nerve fibre layer (pRNFL) thickness. Methods: We used deep learning to segment the optic disc, fovea, and vessels in fundus photographs, and measured pallor. We assessed the relationship between pallor and pRNFL thickness derived from optical coherence tomography scans in 118 participants. Separately, we used images diagnosed by clinical inspection as pale (N=45) and assessed how measurements compared to healthy controls (N=46). We also developed automatic rejection thresholds, and tested the software for robustness to camera type, image format, and resolution. Results: We developed software that automatically quantified disc pallor across several zones in fundus photographs. Pallor was associated with pRNFL thickness globally (\b{eta} = -9.81 (SE = 3.16), p < 0.05), in the temporal inferior zone (\b{eta} = -29.78 (SE = 8.32), p < 0.01), with the nasal/temporal ratio (\b{eta} = 0.88 (SE = 0.34), p < 0.05), and in the whole disc (\b{eta} = -8.22 (SE = 2.92), p < 0.05). Furthermore, pallor was significantly higher in the patient group. Lastly, we demonstrate the analysis to be robust to camera type, image format, and resolution. Conclusions: We developed software that automatically locates and quantifies disc pallor in fundus photographs and found associations between pallor measurements and pRNFL thickness. Translational relevance: We think our method will be useful for the identification, monitoring and progression of diseases characterized by disc pallor/optic atrophy, including glaucoma, compression, and potentially in neurodegenerative disorders.
Cross-linguistically Consistent Semantic and Syntactic Annotation of Child-directed Speech
Sep 22, 2021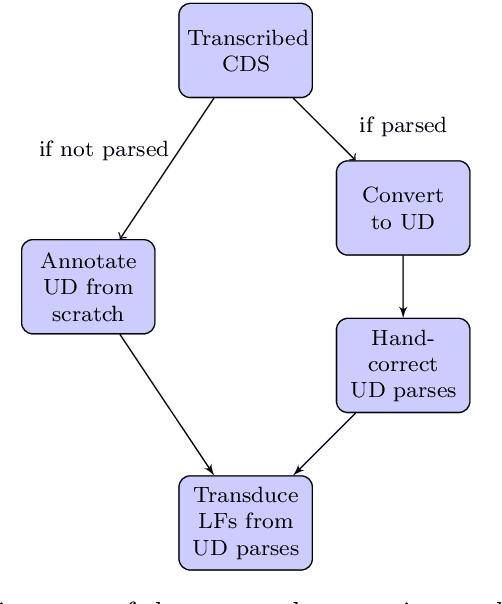
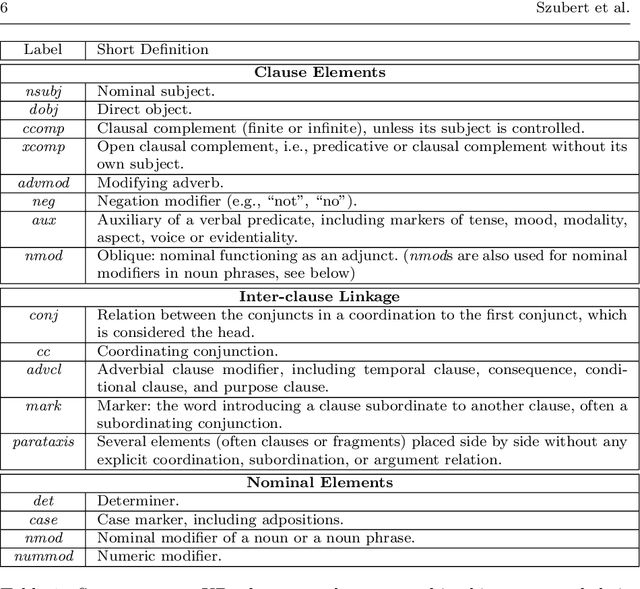
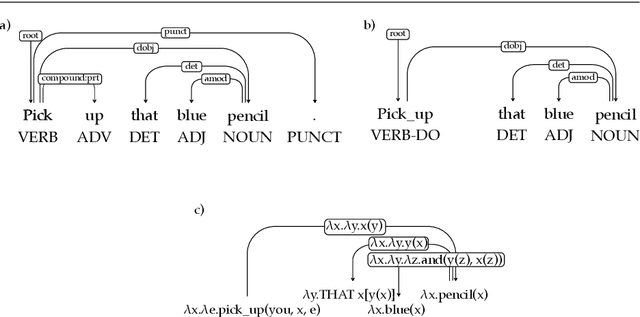
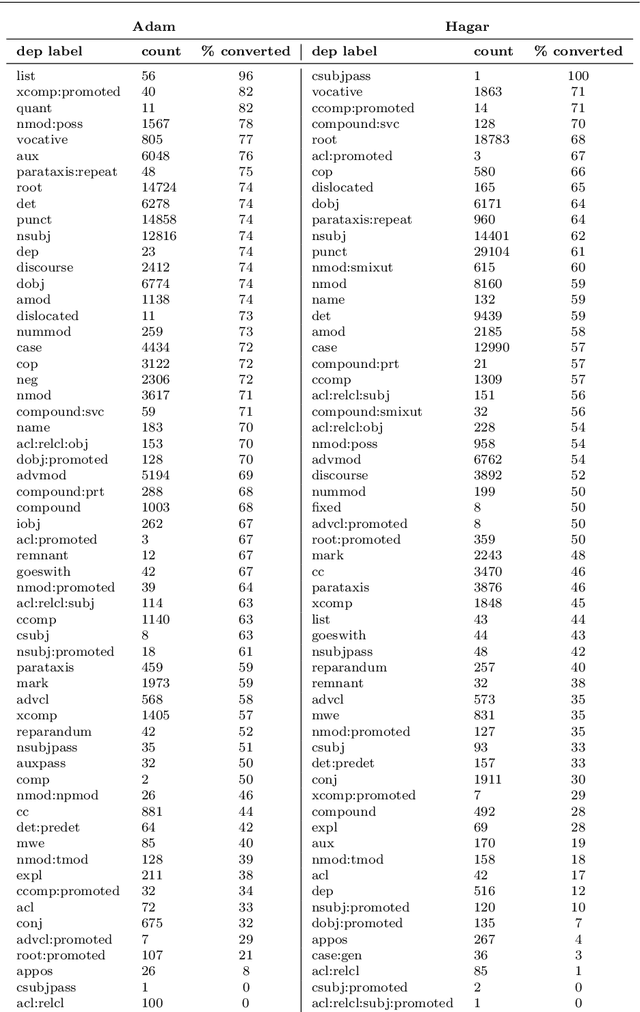
While corpora of child speech and child-directed speech (CDS) have enabled major contributions to the study of child language acquisition, semantic annotation for such corpora is still scarce and lacks a uniform standard. We compile two CDS corpora with sentential logical forms, one in English and the other in Hebrew. In compiling the corpora we employ a methodology that enforces a cross-linguistically consistent representation, building on recent advances in dependency representation and semantic parsing. The corpora are based on a sizable portion of Brown's Adam corpus from CHILDES (about 80% of its child-directed utterances), and to all child-directed utterances from Berman's Hebrew CHILDES corpus Hagar. We begin by annotating the corpora with the Universal Dependencies (UD) scheme for syntactic annotation, motivated by its applicability to a wide variety of domains and languages. We then proceed by applying an automatic method for transducing sentential logical forms (LFs) from UD structures. The two representations have complementary strengths: UD structures are language-neutral and support direct annotation, whereas LFs are neutral as to the interface between syntax and semantics, and transparently encode semantic distinctions. We verify the quality of the annotated UD annotation using an inter-annotator agreement study. We then demonstrate the utility of the compiled corpora through a longitudinal corpus study of the prevalence of different syntactic and semantic phenomena.