 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardening Deep Neural Networks via Adversarial Model Cascades
Nov 04, 2018
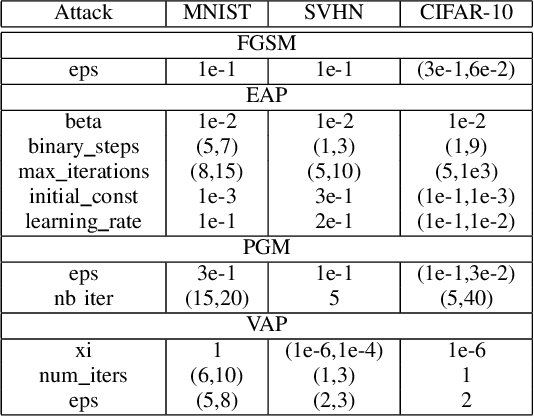
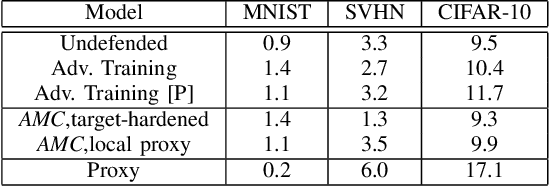
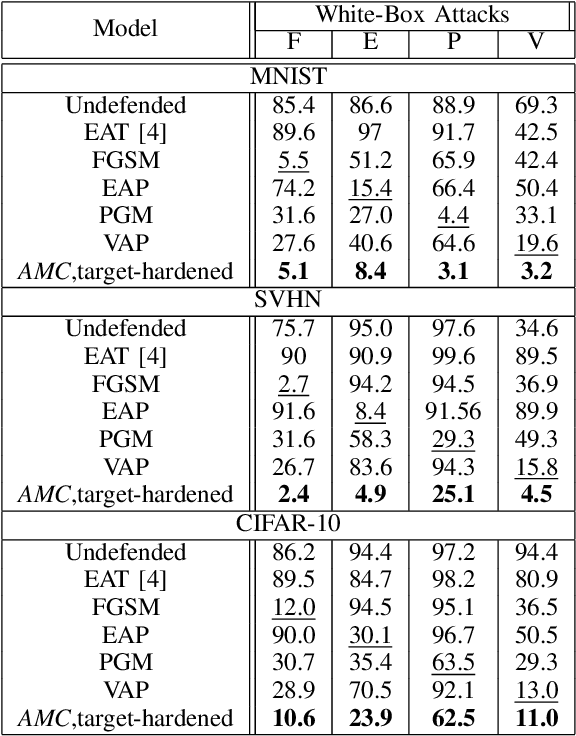
Deep neural networks (DNNs) are vulnerable to malicious inputs crafted by an adversary to produce erroneous outputs. Works on securing neural networks against adversarial examples achieve high empirical robustness on simple datasets such as MNIST. However, these techniques are inadequate when empirically tested on complex data sets such as CIFAR-10 and SVHN. Further, existing techniques are designed to target specific attacks and fail to generalize across attacks. We propose the Adversarial Model Cascades (AMC) as a way to tackle the above inadequacies. Our approach trains a cascade of models sequentially where each model is optimized to be robust towards a mixture of multiple attacks. Ultimately, it yields a single model which is secure against a wide range of attacks; namely FGSM, Elastic, Virtual Adversarial Perturbations and Madry. On an average, AMC increases the model's empirical robustness against various attacks simultaneously, by a significant margin (of 6.225% for MNIST, 5.075% for SVHN and 2.65% for CIFAR10). At the same time, the model's performance on non-adversarial inputs is comparable to the state-of-the-art models.
AI Fairness 360: An Extensible Toolkit for Detecting, Understanding, and Mitigating Unwanted Algorithmic Bias
Oct 03, 2018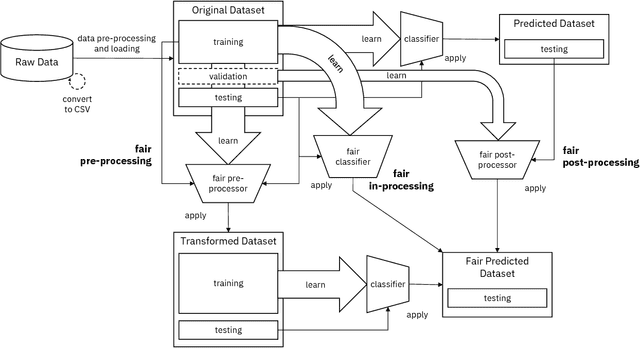
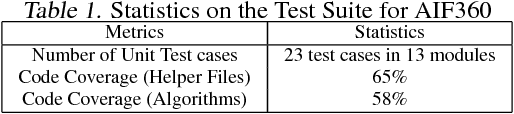
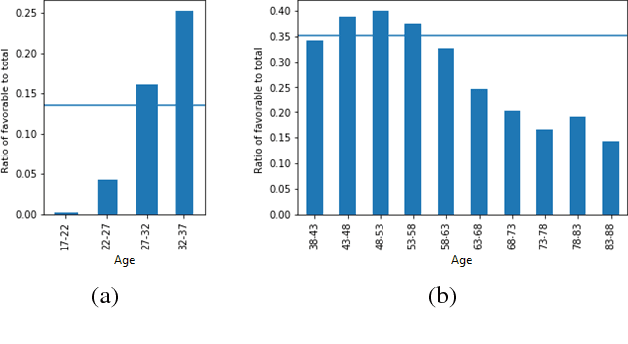
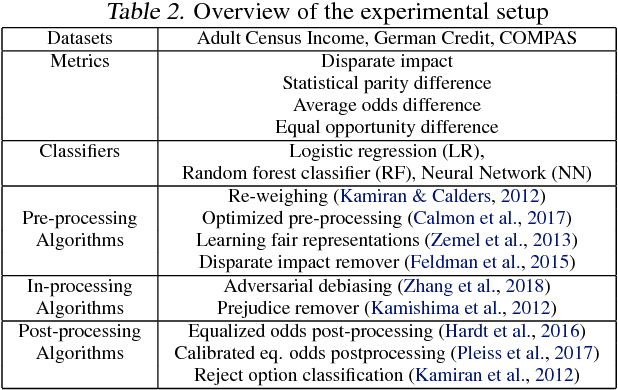
Fairness is an increasingly important concern as machine learning models are used to support decision making in high-stakes applications such as mortgage lending, hiring, and prison sentencing. This paper introduces a new open source Python toolkit for algorithmic fairness, AI Fairness 360 (AIF360), released under an Apache v2.0 license {https://github.com/ibm/aif360). The main objectives of this toolkit are to help facilitate the transition of fairness research algorithms to use in an industrial setting and to provide a common framework for fairness researchers to share and evaluate algorithms. The package includes a comprehensive set of fairness metrics for datasets and models, explanations for these metrics, and algorithms to mitigate bias in datasets and models. It also includes an interactive Web experience (https://aif360.mybluemix.net) that provides a gentle introduction to the concepts and capabilities for line-of-business users, as well as extensive documentation, usage guidance, and industry-specific tutorials to enable data scientists and practitioners to incorporate the most appropriate tool for their problem into their work products. The architecture of the package has been engineered to conform to a standard paradigm used in data science, thereby further improving usability for practitioners. Such architectural design and abstractions enable researchers and developers to extend the toolkit with their new algorithms and improvements, and to use it for performance benchmarking. A built-in testing infrastructure maintains code quality.
Extracting Fairness Policies from Legal Documents
Sep 12, 2018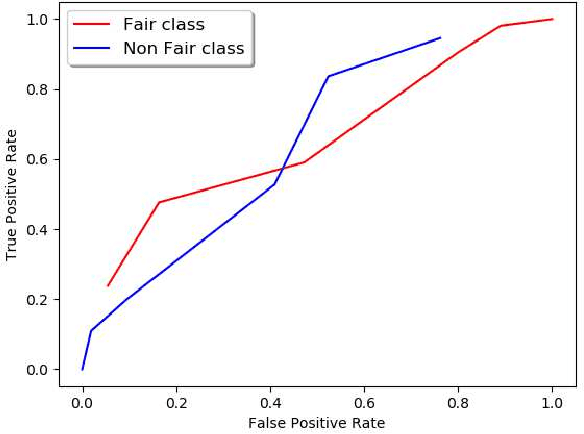
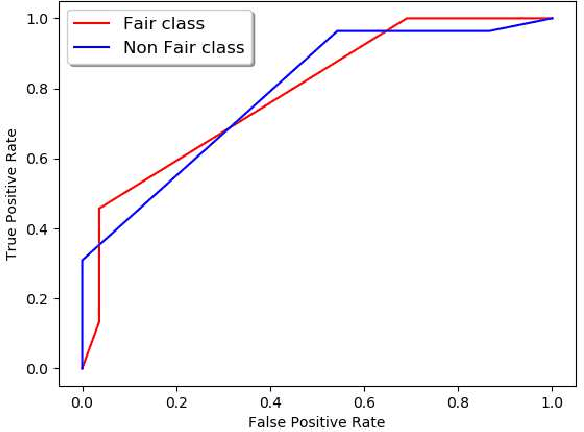
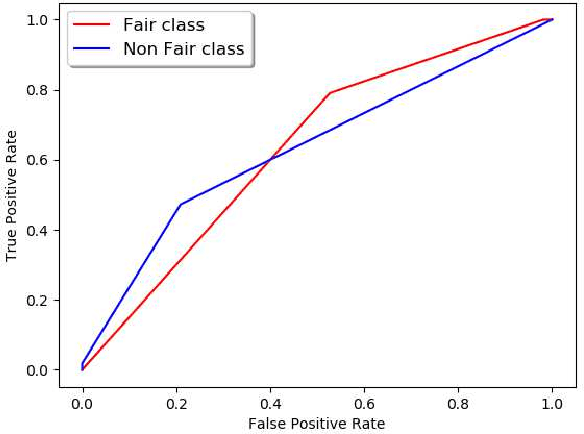
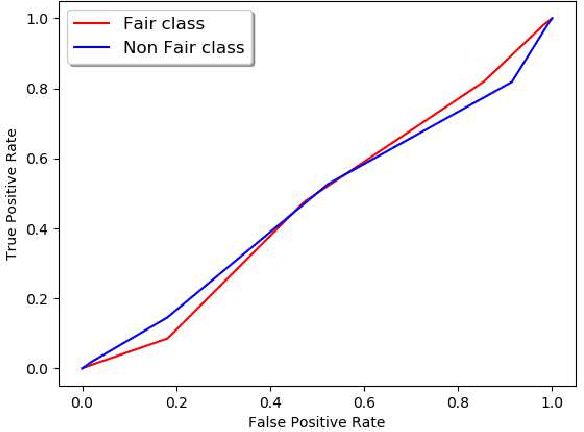
Machine Learning community is recently exploring the implications of bias and fairness with respect to the AI applications. The definition of fairness for such applications varies based on their domain of application. The policies governing the use of such machine learning system in a given context are defined by the constitutional laws of nations and regulatory policies enforced by the organizations that are involved in the usage. Fairness related laws and policies are often spread across the large documents like constitution, agreements, and organizational regulations. These legal documents have long complex sentences in order to achieve rigorousness and robustness. Automatic extraction of fairness policies, or in general, any specific kind of policies from large legal corpus can be very useful for the study of bias and fairness in the context of AI applications. We attempted to automatically extract fairness policies from publicly available law documents using two approaches based on semantic relatedness. The experiments reveal how classical Wordnet-based similarity and vector-based similarity differ in addressing this task. We have shown that similarity based on word vectors beats the classical approach with a large margin, whereas other vector representations of senses and sentences fail to even match the classical baseline. Further, we have presented thorough error analysis and reasoning to explain the results with appropriate examples from the dataset for deeper insights.
Increasing Trust in AI Services through Supplier's Declarations of Conformity
Aug 22, 2018The accuracy and reliability of machine learning algorithms are an important concern for suppliers of artificial intelligence (AI) services, but considerations beyond accuracy, such as safety, security, and provenance, are also critical elements to engender consumers' trust in a service. In this paper, we propose a supplier's declaration of conformity (SDoC) for AI services to help increase trust in AI services. An SDoC is a transparent, standardized, but often not legally required, document used in many industries and sectors to describe the lineage of a product along with the safety and performance testing it has undergone. We envision an SDoC for AI services to contain purpose, performance, safety, security, and provenance information to be completed and voluntarily released by AI service providers for examination by consumers. Importantly, it conveys product-level rather than component-level functional testing. We suggest a set of declaration items tailored to AI and provide examples for two fictitious AI services.
Judging a Book by its Description : Analyzing Gender Stereotypes in the Man Bookers Prize Winning Fiction
Jul 25, 2018
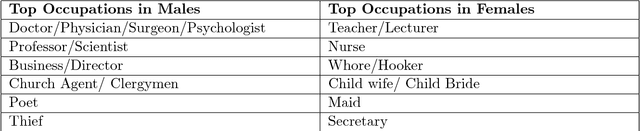
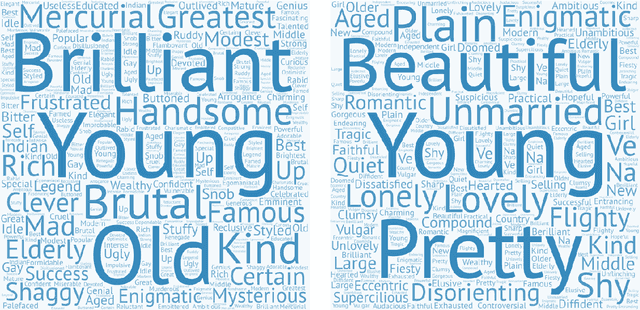

The presence of gender stereotypes in many aspects of society is a well-known phenomenon. In this paper, we focus on studying and quantifying such stereotypes and bias in the Man Bookers Prize winning fiction. We consider 275 books shortlisted for Man Bookers Prize between 1969 and 2017. The gender bias is analyzed by semantic modeling of book descriptions on Goodreads. This reveals the pervasiveness of gender bias and stereotype in the books on different features like occupation, introductions and actions associated to the characters in the book.
Generating Clues for Gender based Occupation De-biasing in Text
Apr 11, 2018
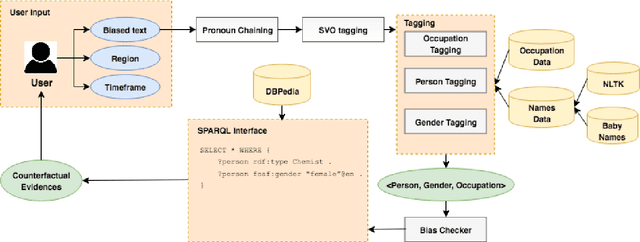
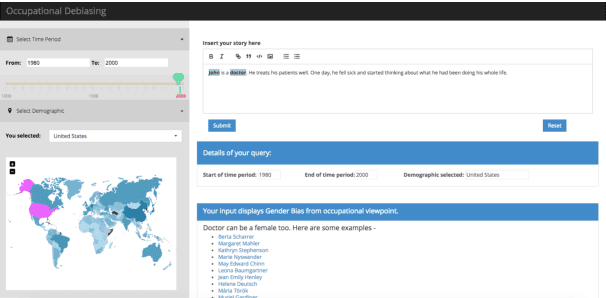
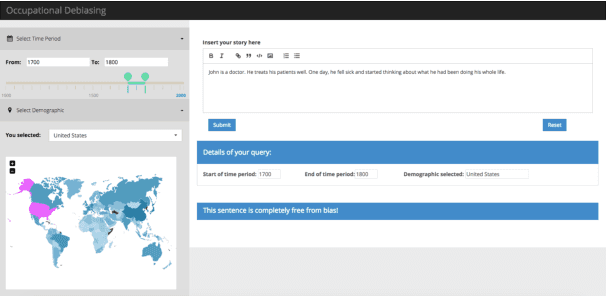
Vast availability of text data has enabled widespread training and use of AI systems that not only learn and predict attributes from the text but also generate text automatically. However, these AI models also learn gender, racial and ethnic biases present in the training data. In this paper, we present the first system that discovers the possibility that a given text portrays a gender stereotype associated with an occupation. If the possibility exists, the system offers counter-evidences of opposite gender also being associated with the same occupation in the context of user-provided geography and timespan. The system thus enables text de-biasing by assisting a human-in-the-loop. The system can not only act as a text pre-processor before training any AI model but also help human story writers write stories free of occupation-level gender bias in the geographical and temporal context of their choice.
Model Extraction Warning in MLaaS Paradigm
Nov 20, 2017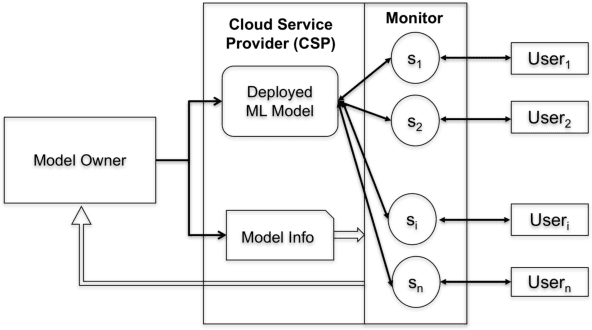
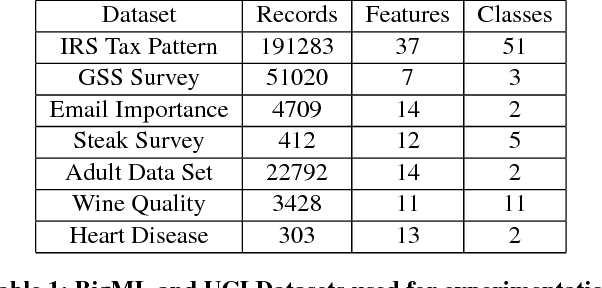
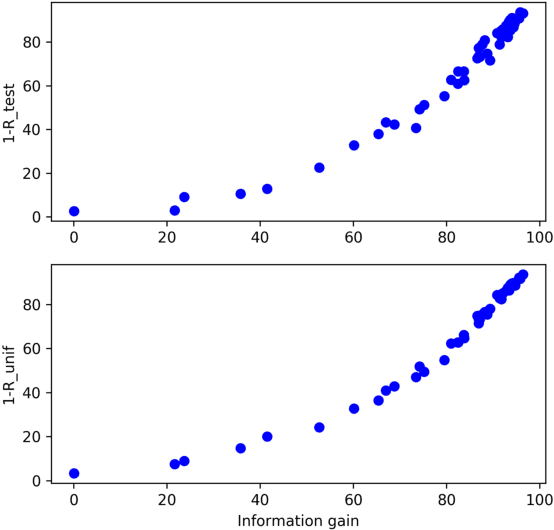
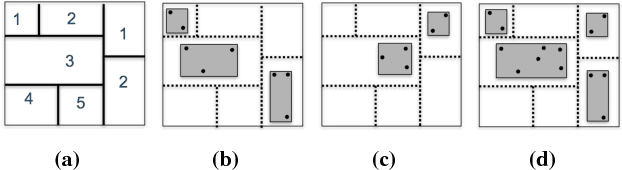
Cloud vendors are increasingly offering machine learning services as part of their platform and services portfolios. These services enable the deployment of machine learning models on the cloud that are offered on a pay-per-query basis to application developers and end users. However recent work has shown that the hosted models are susceptible to extraction attacks. Adversaries may launch queries to steal the model and compromise future query payments or privacy of the training data. In this work, we present a cloud-based extraction monitor that can quantify the extraction status of models by observing the query and response streams of both individual and colluding adversarial users. We present a novel technique that uses information gain to measure the model learning rate by users with increasing number of queries. Additionally, we present an alternate technique that maintains intelligent query summaries to measure the learning rate relative to the coverage of the input feature space in the presence of collusion. Both these approaches have low computational overhead and can easily be offered as services to model owners to warn them of possible extraction attacks from adversaries. We present performance results for these approaches for decision tree models deployed on BigML MLaaS platform, using open source datasets and different adversarial attack strategies.
Bollywood Movie Corpus for Text, Images and Videos
Oct 11, 2017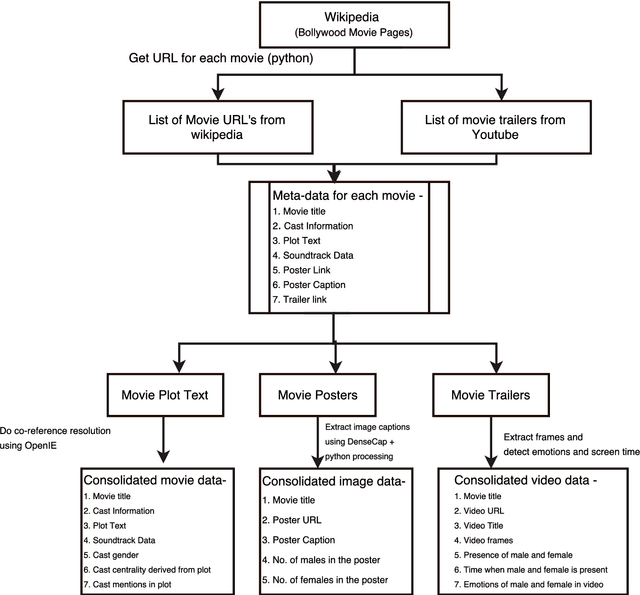
In past few years, several data-sets have been released for text and images. We present an approach to create the data-set for use in detecting and removing gender bias from text. We also include a set of challenges we have faced while creating this corpora. In this work, we have worked with movie data from Wikipedia plots and movie trailers from YouTube. Our Bollywood Movie corpus contains 4000 movies extracted from Wikipedia and 880 trailers extracted from YouTube which were released from 1970-2017. The corpus contains csv files with the following data about each movie - Wikipedia title of movie, cast, plot text, co-referenced plot text, soundtrack information, link to movie poster, caption of movie poster, number of males in poster, number of females in poster. In addition to that, corresponding to each cast member the following data is available - cast name, cast gender, cast verbs, cast adjectives, cast relations, cast centrality, cast mentions. We present some preliminary results on the task of bias removal which suggest that the data-set is quite useful for performing such tasks.
A Survey on Resilient Machine Learning
Jul 11, 2017

Machine learning based system are increasingly being used for sensitive tasks such as security surveillance, guiding autonomous vehicle, taking investment decisions, detecting and blocking network intrusion and malware etc. However, recent research has shown that machine learning models are venerable to attacks by adversaries at all phases of machine learning (eg, training data collection, training, operation). All model classes of machine learning systems can be misled by providing carefully crafted inputs making them wrongly classify inputs. Maliciously created input samples can affect the learning process of a ML system by either slowing down the learning process, or affecting the performance of the learned mode, or causing the system make error(s) only in attacker's planned scenario. Because of these developments, understanding security of machine learning algorithms and systems is emerging as an important research area among computer security and machine learning researchers and practitioners. We present a survey of this emerging area in machine learning.
Towards Crafting Text Adversarial Samples
Jul 10, 2017
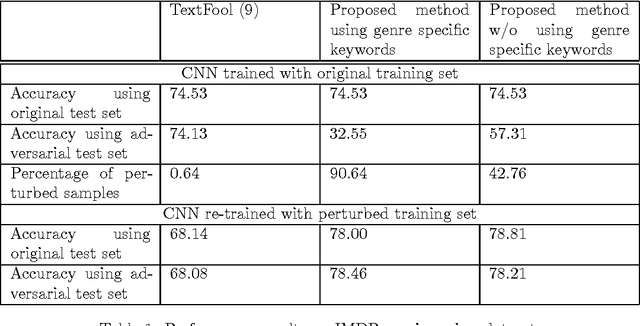
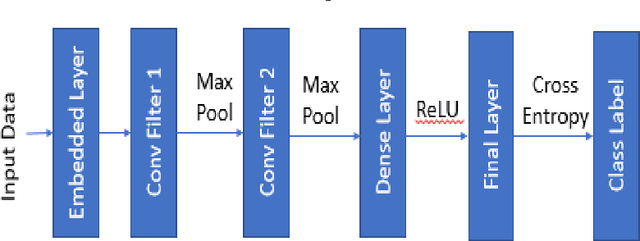
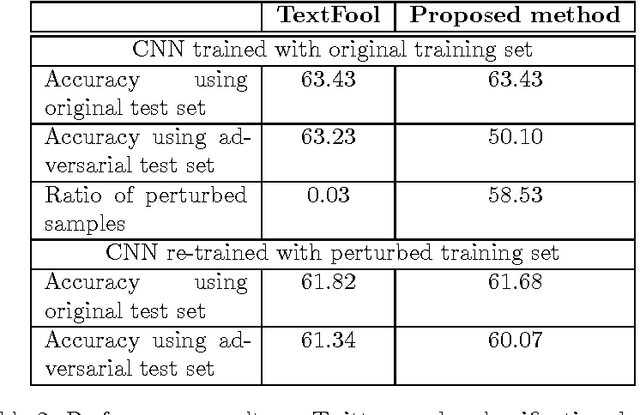
Adversarial samples are strategically modified samples, which are crafted with the purpose of fooling a classifier at hand. An attacker introduces specially crafted adversarial samples to a deployed classifier, which are being mis-classified by the classifier. However, the samples are perceived to be drawn from entirely different classes and thus it becomes hard to detect the adversarial samples. Most of the prior works have been focused on synthesizing adversarial samples in the image domain. In this paper, we propose a new method of crafting adversarial text samples by modification of the original samples. Modifications of the original text samples are done by deleting or replacing the important or salient words in the text or by introducing new words in the text sample. Our algorithm works best for the datasets which have sub-categories within each of the classes of examples. While crafting adversarial samples, one of the key constraint is to generate meaningful sentences which can at pass off as legitimate from language (English) viewpoint. Experimental results on IMDB movie review dataset for sentiment analysis and Twitter dataset for gender detection show the efficiency of our proposed method.