 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Fairness Policies from Legal Documents
Sep 12, 2018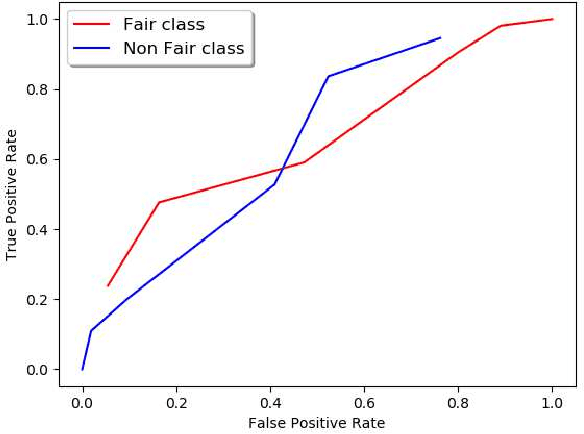
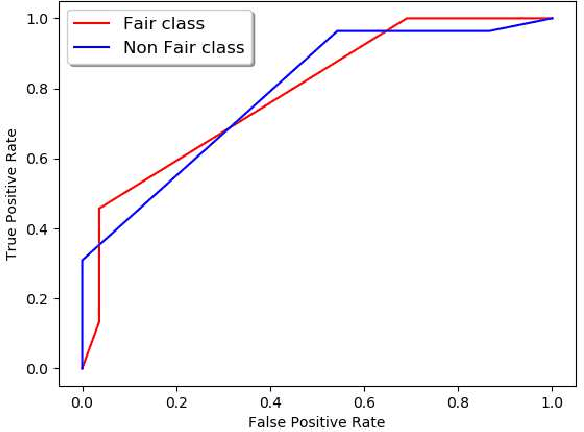
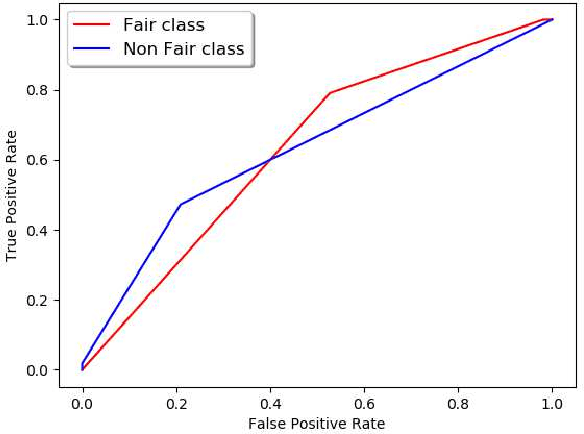
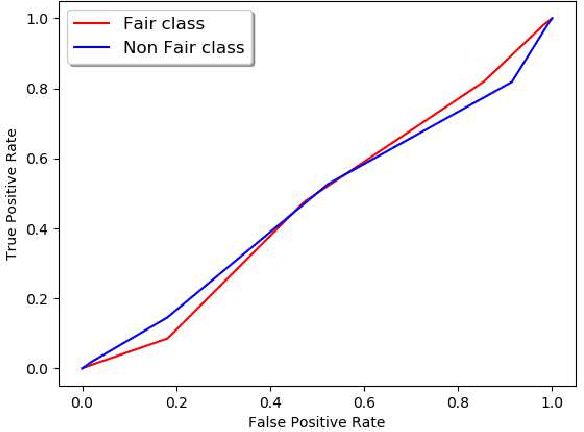
Machine Learning community is recently exploring the implications of bias and fairness with respect to the AI applications. The definition of fairness for such applications varies based on their domain of application. The policies governing the use of such machine learning system in a given context are defined by the constitutional laws of nations and regulatory policies enforced by the organizations that are involved in the usage. Fairness related laws and policies are often spread across the large documents like constitution, agreements, and organizational regulations. These legal documents have long complex sentences in order to achieve rigorousness and robustness. Automatic extraction of fairness policies, or in general, any specific kind of policies from large legal corpus can be very useful for the study of bias and fairness in the context of AI applications. We attempted to automatically extract fairness policies from publicly available law documents using two approaches based on semantic relatedness. The experiments reveal how classical Wordnet-based similarity and vector-based similarity differ in addressing this task. We have shown that similarity based on word vectors beats the classical approach with a large margin, whereas other vector representations of senses and sentences fail to even match the classical baseline. Further, we have presented thorough error analysis and reasoning to explain the results with appropriate examples from the dataset for deeper insights.