 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre ChatGPT and GPT-4 General-Purpose Solvers for Financial Text Analytics? An Examination on Several Typical Tasks
May 10, 2023The most recent large language models such as ChatGPT and GPT-4 have garnered significant attention, as they are capable of generating high-quality responses to human input. Despite the extensive testing of ChatGPT and GPT-4 on generic text corpora, showcasing their impressive capabilities, a study focusing on financial corpora has not been conducted. In this study, we aim to bridge this gap by examining the potential of ChatGPT and GPT-4 as a solver for typical financial text analytic problems in the zero-shot or few-shot setting. Specifically, we assess their capabilities on four representative tasks over five distinct financial textual datasets. The preliminary study shows that ChatGPT and GPT-4 struggle on tasks such as financial named entity recognition (NER) and sentiment analysis, where domain-specific knowledge is required, while they excel in numerical reasoning tasks. We report both the strengths and limitations of the current versions of ChatGPT and GPT-4, comparing them to the state-of-the-art finetuned models as well as pretrained domain-specific generative models. Our experiments provide qualitative studies, through which we hope to help understand the capability of the existing models and facilitate further improvements.
Bayesian Hierarchical Models for Counterfactual Estimation
Jan 21, 2023



Counterfactual explanations utilize feature perturbations to analyze the outcome of an original decision and recommend an actionable recourse. We argue that it is beneficial to provide several alternative explanations rather than a single point solution and propose a probabilistic paradigm to estimate a diverse set of counterfactuals. Specifically, we treat the perturbations as random variables endowed with prior distribution functions. This allows sampling multiple counterfactuals from the posterior density, with the added benefit of incorporating inductive biases, preserving domain specific constraints and quantifying uncertainty in estimates. More importantly, we leverage Bayesian hierarchical modeling to share information across different subgroups of a population, which can both improve robustness and measure fairness. A gradient based sampler with superior convergence characteristics efficiently computes the posterior samples. Experiments across several datasets demonstrate that the counterfactuals estimated using our approach are valid, sparse, diverse and feasible.
Neural Transition-based Parsing of Library Deprecations
Dec 23, 2022



This paper tackles the challenging problem of automating code updates to fix deprecated API usages of open source libraries by analyzing their release notes. Our system employs a three-tier architecture: first, a web crawler service retrieves deprecation documentation from the web; then a specially built parser processes those text documents into tree-structured representations; finally, a client IDE plugin locates and fixes identified deprecated usages of libraries in a given codebase. The focus of this paper in particular is the parsing component. We introduce a novel transition-based parser in two variants: based on a classical feature engineered classifier and a neural tree encoder. To confirm the effectiveness of our method, we gathered and labeled a set of 426 API deprecations from 7 well-known Python data science libraries, and demonstrated our approach decisively outperforms a non-trivial neural machine translation baseline.
ConvFinQA: Exploring the Chain of Numerical Reasoning in Conversational Finance Question Answering
Oct 07, 2022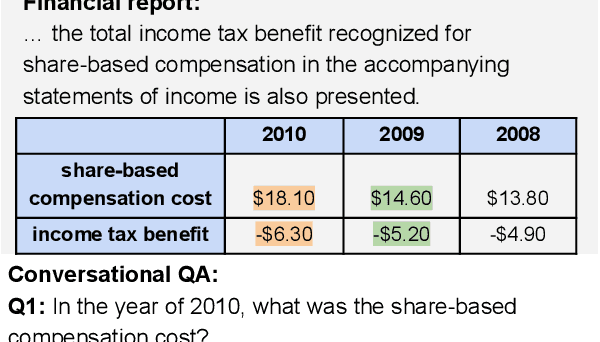

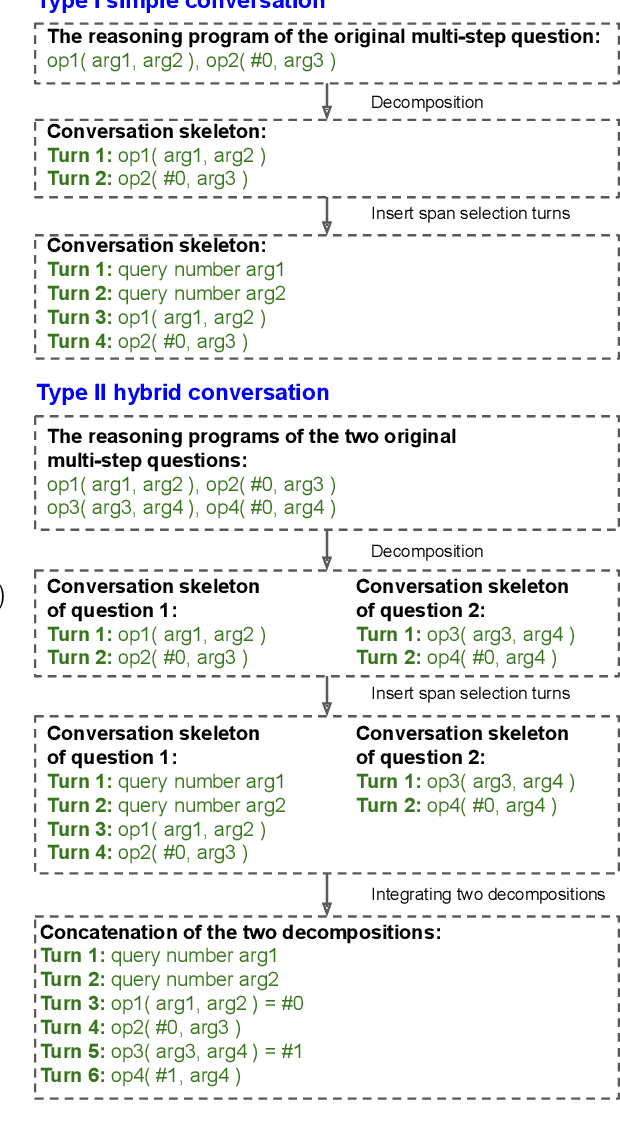

With the recent advance in large pre-trained language models, researchers have achieved record performances in NLP tasks that mostly focus on language pattern matching. The community is experiencing the shift of the challenge from how to model language to the imitation of complex reasoning abilities like human beings. In this work, we investigate the application domain of finance that involves real-world, complex numerical reasoning. We propose a new large-scale dataset, ConvFinQA, aiming to study the chain of numerical reasoning in conversational question answering. Our dataset poses great challenge in modeling long-range, complex numerical reasoning paths in real-world conversations. We conduct comprehensive experiments and analyses with both the neural symbolic methods and the prompting-based methods, to provide insights into the reasoning mechanisms of these two divisions. We believe our new dataset should serve as a valuable resource to push forward the exploration of real-world, complex reasoning tasks as the next research focus. Our dataset and code is publicly available at https://github.com/czyssrs/ConvFinQA.
AIR-JPMC@SMM4H'22: Classifying Self-Reported Intimate Partner Violence in Tweets with Multiple BERT-based Models
Sep 22, 2022
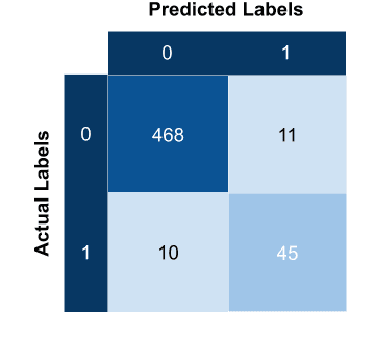

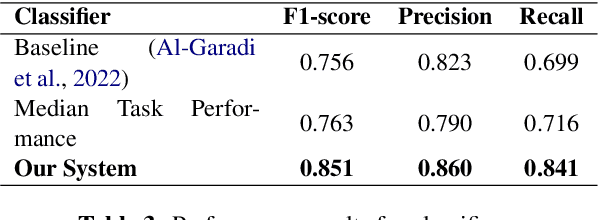
This paper presents our submission for the SMM4H 2022-Shared Task on the classification of self-reported intimate partner violence on Twitter (in English). The goal of this task was to accurately determine if the contents of a given tweet demonstrated someone reporting their own experience with intimate partner violence. The submitted system is an ensemble of five RoBERTa models each weighted by their respective F1-scores on the validation data-set. This system performed 13% better than the baseline and was the best performing system overall for this shared task.
Online Learning for Mixture of Multivariate Hawkes Processes
Aug 16, 2022
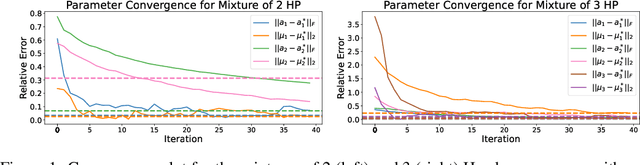
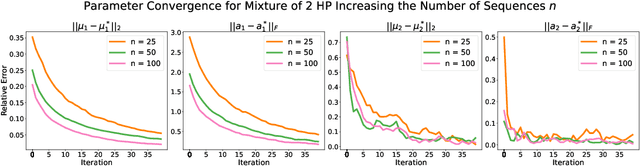

Online learning of Hawkes processes has received increasing attention in the last couple of years especially for modeling a network of actors. However, these works typically either model the rich interaction between the events or the latent cluster of the actors or the network structure between the actors. We propose to model the latent structure of the network of actors as well as their rich interaction across events for real-world settings of medical and financial applications. Experimental results on both synthetic and real-world data showcase the efficacy of our approach.
Bandit Sampling for Multiplex Networks
Feb 08, 2022



Graph neural networks have gained prominence due to their excellent performance in many classification and prediction tasks. In particular, they are used for node classification and link prediction which have a wide range of applications in social networks, biomedical data sets, and financial transaction graphs. Most of the existing work focuses primarily on the monoplex setting where we have access to a network with only a single type of connection between entities. However, in the multiplex setting, where there are multiple types of connections, or \emph{layers}, between entities, performance on tasks such as link prediction has been shown to be stronger when information from other connection types is taken into account. We propose an algorithm for scalable learning on multiplex networks with a large number of layers. The efficiency of our method is enabled by an online learning algorithm that learns how to sample relevant neighboring layers so that only the layers with relevant information are aggregated during training. This sampling differs from prior work, such as MNE, which aggregates information across \emph{all} layers and consequently leads to computational intractability on large networks. Our approach also improves on the recent layer sampling method of \textsc{DeePlex} in that the unsampled layers do not need to be trained, enabling further increases in efficiency.We present experimental results on both synthetic and real-world scenarios that demonstrate the practical effectiveness of our proposed approach.
Structure with Semantics: Exploiting Document Relations for Retrieval
Jan 12, 2022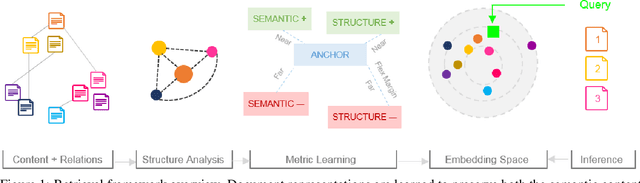
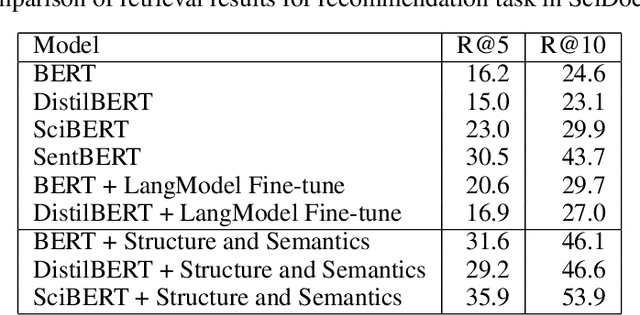
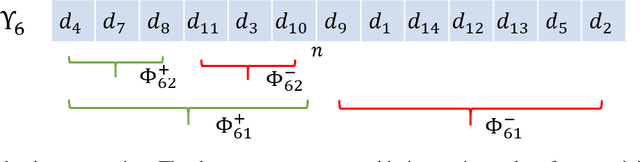
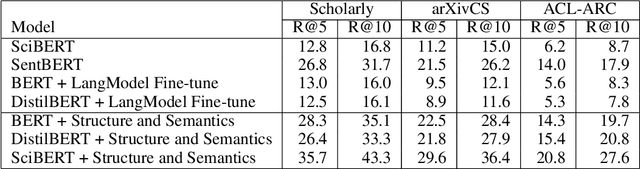
Retrieving relevant documents from a corpus is typically based on the semantic similarity between the document content and query text. The inclusion of structural relationship between documents can benefit the retrieval mechanism by addressing semantic gaps. However, incorporating these relationships requires tractable mechanisms that balance structure with semantics and take advantage of the prevalent pre-train/fine-tune paradigm. We propose here a holistic approach to learning document representations by integrating intra-document content with inter-document relations. Our deep metric learning solution analyzes the complex neighborhood structure in the relationship network to efficiently sample similar/dissimilar document pairs and defines a novel quintuplet loss function that simultaneously encourages document pairs that are semantically relevant to be closer and structurally unrelated to be far apart in the representation space. Furthermore, the separation margins between the documents are varied flexibly to encode the heterogeneity in relationship strengths. The model is fully fine-tunable and natively supports query projection during inference. We demonstrate that it outperforms competing methods on multiple datasets for document retrieval tasks.
Synthetic Document Generator for Annotation-free Layout Recognition
Nov 11, 2021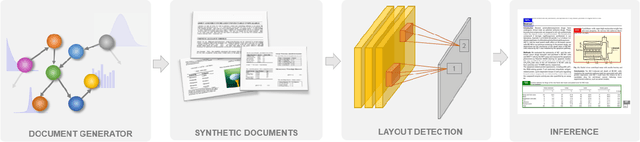
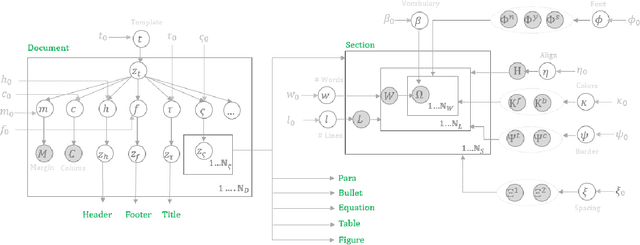
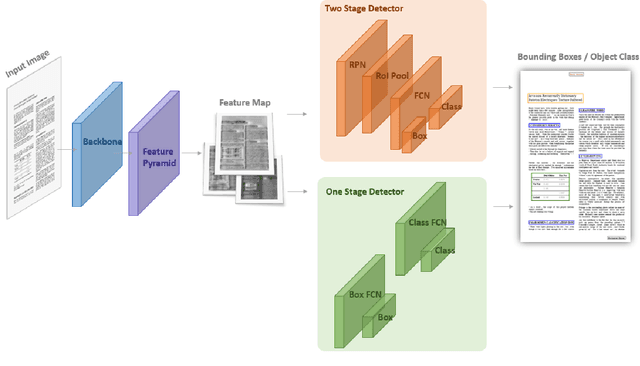
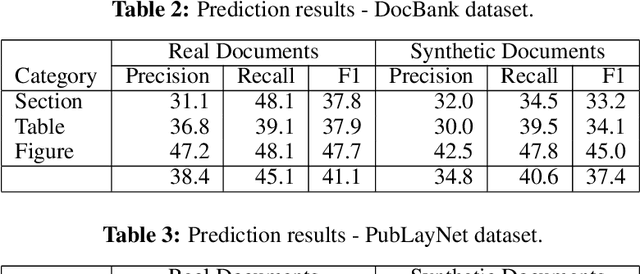
Analyzing the layout of a document to identify headers, sections, tables, figures etc. is critical to understanding its content. Deep learning based approaches for detecting the layout structure of document images have been promising. However, these methods require a large number of annotated examples during training, which are both expensive and time consuming to obtain. We describe here a synthetic document generator that automatically produces realistic documents with labels for spatial positions, extents and categories of the layout elements. The proposed generative process treats every physical component of a document as a random variable and models their intrinsic dependencies using a Bayesian Network graph. Our hierarchical formulation using stochastic templates allow parameter sharing between documents for retaining broad themes and yet the distributional characteristics produces visually unique samples, thereby capturing complex and diverse layouts. We empirically illustrate that a deep layout detection model trained purely on the synthetic documents can match the performance of a model that uses real documents.
Parameterized Explanations for Investor / Company Matching
Oct 27, 2021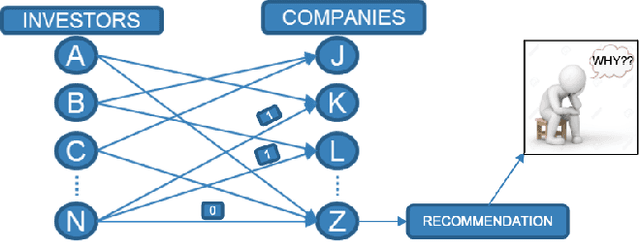
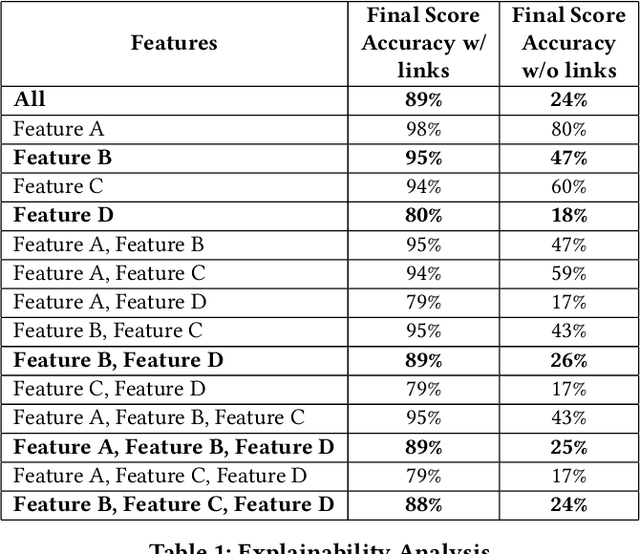
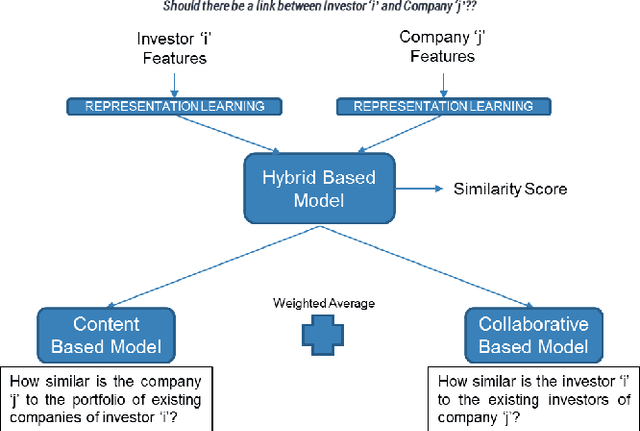
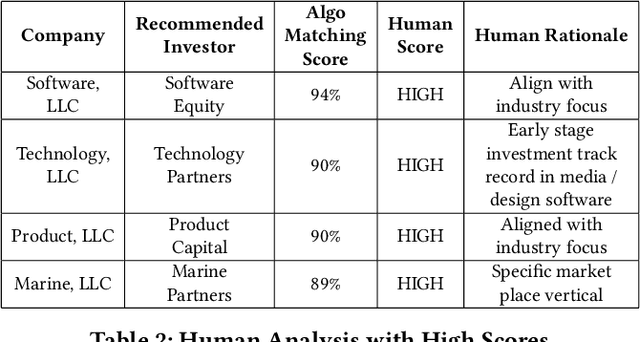
Matching companies and investors is usually considered a highly specialized decision making process. Building an AI agent that can automate such recommendation process can significantly help reduce costs, and eliminate human biases and errors. However, limited sample size of financial data-sets and the need for not only good recommendations, but also explaining why a particular recommendation is being made, makes this a challenging problem. In this work we propose a representation learning based recommendation engine that works extremely well with small datasets and demonstrate how it can be coupled with a parameterized explanation generation engine to build an explainable recommendation system for investor-company matching. We compare the performance of our system with human generated recommendations and demonstrate the ability of our algorithm to perform extremely well on this task. We also highlight how explainability helps with real-life adoption of our system.