 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLamby: Datasets and Benchmarks for Cross-Silo Federated Learning in Realistic Healthcare Settings
Oct 10, 2022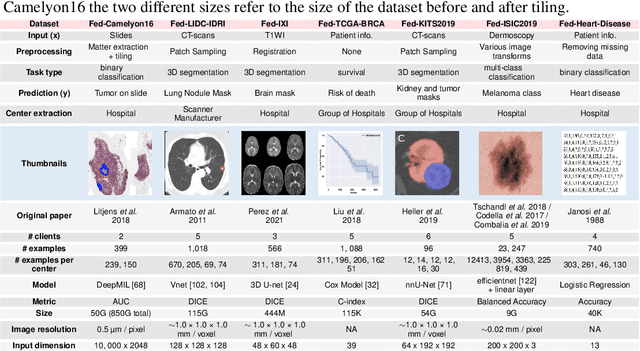
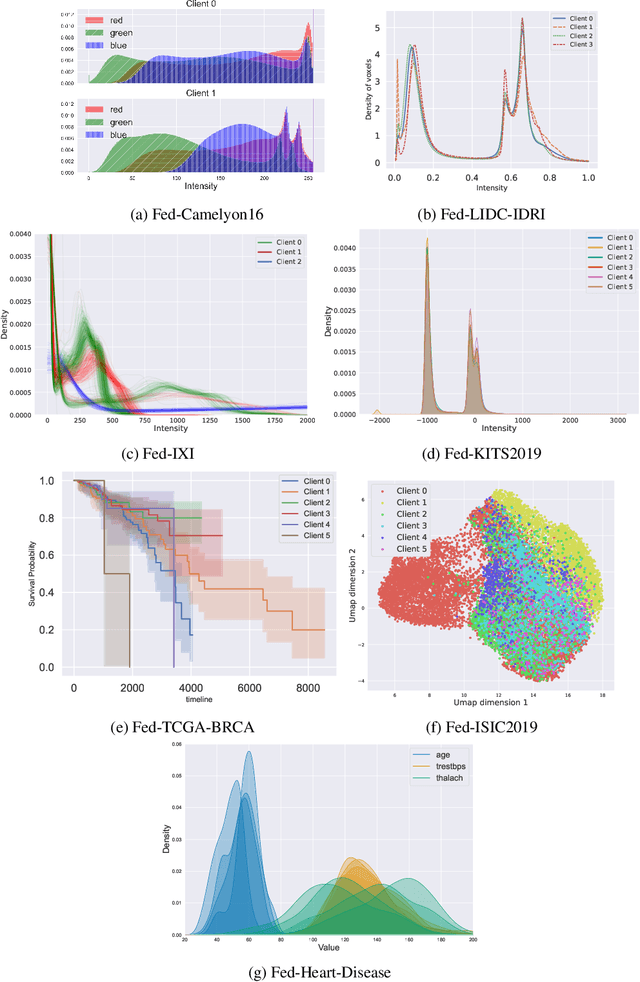
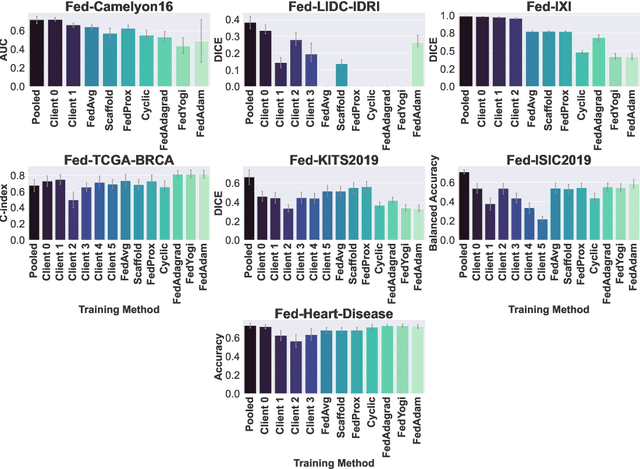

Federated Learning (FL) is a novel approach enabling several clients holding sensitive data to collaboratively train machine learning models, without centralizing data. The cross-silo FL setting corresponds to the case of few ($2$--$50$) reliable clients, each holding medium to large datasets, and is typically found in applications such as healthcare, finance, or industry. While previous works have proposed representative datasets for cross-device FL, few realistic healthcare cross-silo FL datasets exist, thereby slowing algorithmic research in this critical application. In this work, we propose a novel cross-silo dataset suite focused on healthcare, FLamby (Federated Learning AMple Benchmark of Your cross-silo strategies), to bridge the gap between theory and practice of cross-silo FL. FLamby encompasses 7 healthcare datasets with natural splits, covering multiple tasks, modalities, and data volumes, each accompanied with baseline training code. As an illustration, we additionally benchmark standard FL algorithms on all datasets. Our flexible and modular suite allows researchers to easily download datasets, reproduce results and re-use the different components for their research. FLamby is available at~\url{www.github.com/owkin/flamby}.
TCT: Convexifying Federated Learning using Bootstrapped Neural Tangent Kernels
Jul 13, 2022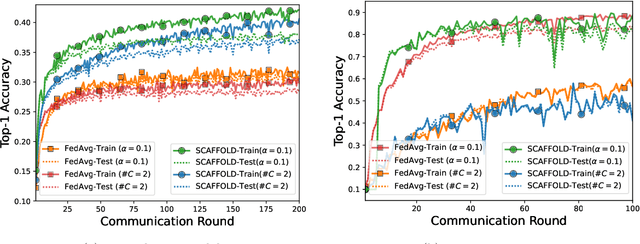
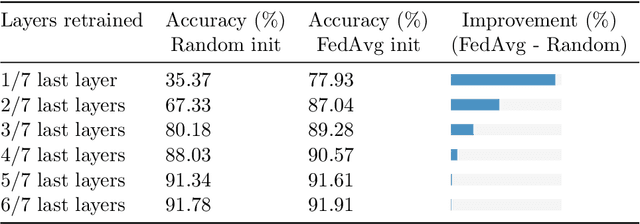

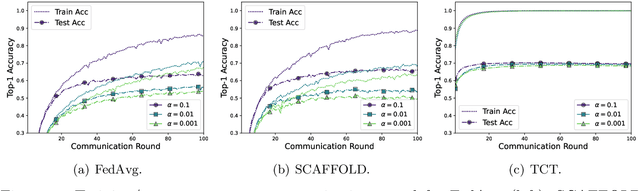
State-of-the-art federated learning methods can perform far worse than their centralized counterparts when clients have dissimilar data distributions. For neural networks, even when centralized SGD easily finds a solution that is simultaneously performant for all clients, current federated optimization methods fail to converge to a comparable solution. We show that this performance disparity can largely be attributed to optimization challenges presented by nonconvexity. Specifically, we find that the early layers of the network do learn useful features, but the final layers fail to make use of them. That is, federated optimization applied to this non-convex problem distorts the learning of the final layers. Leveraging this observation, we propose a Train-Convexify-Train (TCT) procedure to sidestep this issue: first, learn features using off-the-shelf methods (e.g., FedAvg); then, optimize a convexified problem obtained from the network's empirical neural tangent kernel approximation. Our technique yields accuracy improvements of up to +36% on FMNIST and +37% on CIFAR10 when clients have dissimilar data.
Mechanisms that Incentivize Data Sharing in Federated Learning
Jul 10, 2022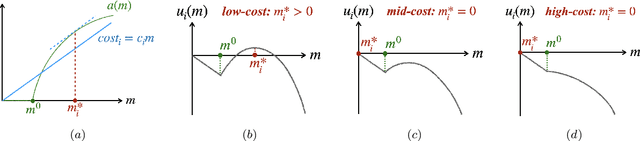
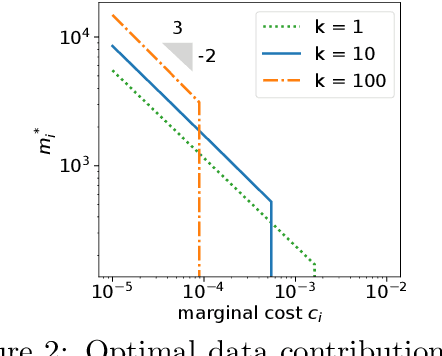
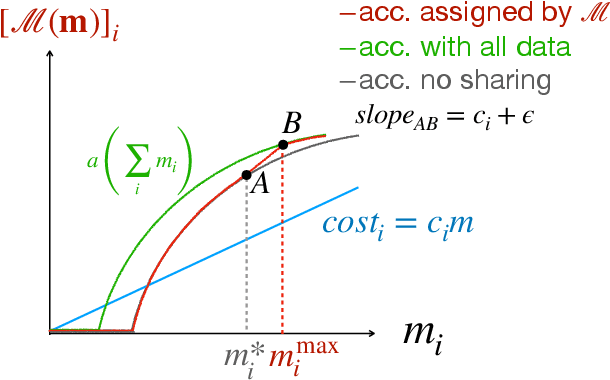
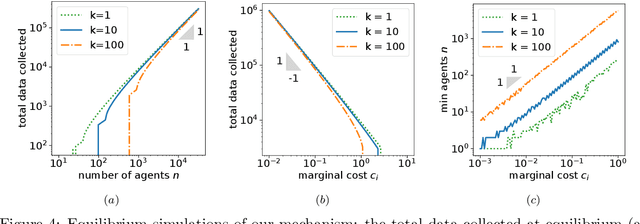
Federated learning is typically considered a beneficial technology which allows multiple agents to collaborate with each other, improve the accuracy of their models, and solve problems which are otherwise too data-intensive / expensive to be solved individually. However, under the expectation that other agents will share their data, rational agents may be tempted to engage in detrimental behavior such as free-riding where they contribute no data but still enjoy an improved model. In this work, we propose a framework to analyze the behavior of such rational data generators. We first show how a naive scheme leads to catastrophic levels of free-riding where the benefits of data sharing are completely eroded. Then, using ideas from contract theory, we introduce accuracy shaping based mechanisms to maximize the amount of data generated by each agent. These provably prevent free-riding without needing any payment mechanism.
Optimization with access to auxiliary information
Jun 01, 2022
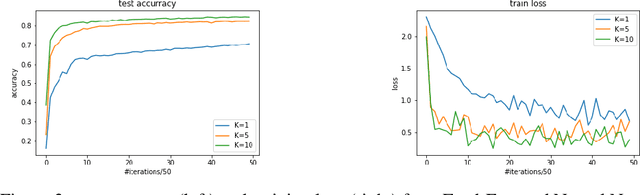
We investigate the fundamental optimization question of minimizing a target function $f(x)$ whose gradients are expensive to compute or have limited availability, given access to some auxiliary side function $h(x)$ whose gradients are cheap or more available. This formulation captures many settings of practical relevance such as i) re-using batches in SGD, ii) transfer learning, iii) federated learning, iv) training with compressed models/dropout, etc. We propose two generic new algorithms which are applicable in all these settings and prove using only an assumption on the Hessian similarity between the target and side information that we can benefit from this framework.
Agree to Disagree: Diversity through Disagreement for Better Transferability
Feb 09, 2022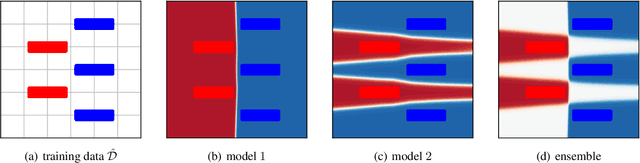

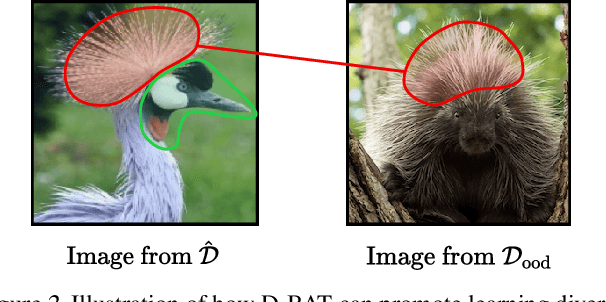

Gradient-based learning algorithms have an implicit simplicity bias which in effect can limit the diversity of predictors being sampled by the learning procedure. This behavior can hinder the transferability of trained models by (i) favoring the learning of simpler but spurious features -- present in the training data but absent from the test data -- and (ii) by only leveraging a small subset of predictive features. Such an effect is especially magnified when the test distribution does not exactly match the train distribution -- referred to as the Out of Distribution (OOD) generalization problem. However, given only the training data, it is not always possible to apriori assess if a given feature is spurious or transferable. Instead, we advocate for learning an ensemble of models which capture a diverse set of predictive features. Towards this, we propose a new algorithm D-BAT (Diversity-By-disAgreement Training), which enforces agreement among the models on the training data, but disagreement on the OOD data. We show how D-BAT naturally emerges from the notion of generalized discrepancy, as well as demonstrate in multiple experiments how the proposed method can mitigate shortcut-learning, enhance uncertainty and OOD detection, as well as improve transferability.
Byzantine-Robust Decentralized Learning via Self-Centered Clipping
Feb 03, 2022



In this paper, we study the challenging task of Byzantine-robust decentralized training on arbitrary communication graphs. Unlike federated learning where workers communicate through a server, workers in the decentralized environment can only talk to their neighbors, making it harder to reach consensus. We identify a novel dissensus attack in which few malicious nodes can take advantage of information bottlenecks in the topology to poison the collaboration. To address these issues, we propose a Self-Centered Clipping (SCClip) algorithm for Byzantine-robust consensus and optimization, which is the first to provably converge to a $O(\delta_{\max}\zeta^2/\gamma^2)$ neighborhood of the stationary point for non-convex objectives under standard assumptions. Finally, we demonstrate the encouraging empirical performance of SCClip under a large number of attacks.
Linear Speedup in Personalized Collaborative Learning
Nov 10, 2021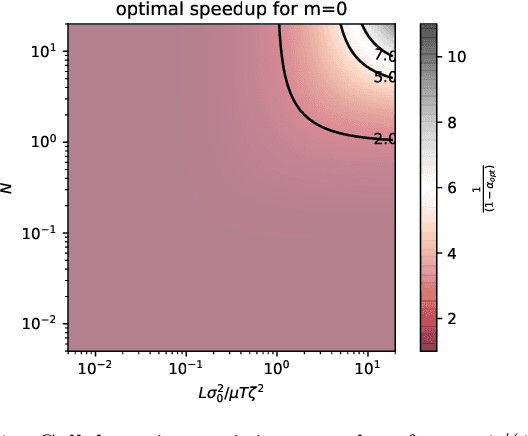
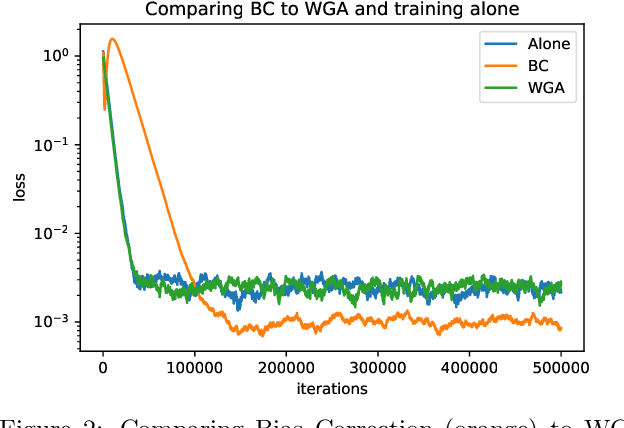
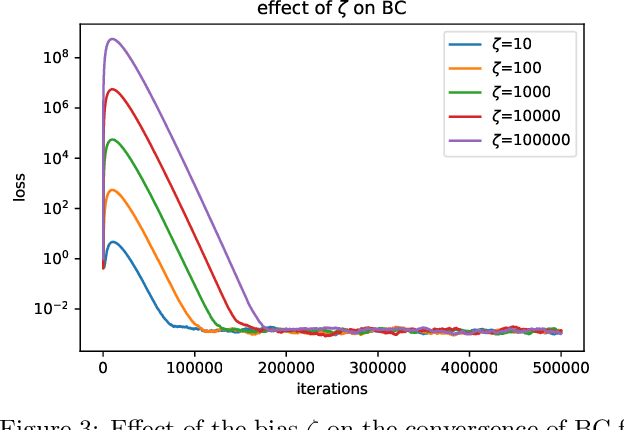
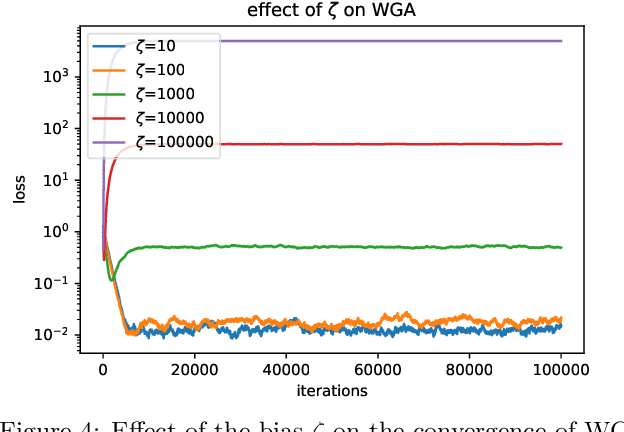
Personalization in federated learning can improve the accuracy of a model for a user by trading off the model's bias (introduced by using data from other users who are potentially different) against its variance (due to the limited amount of data on any single user). In order to develop training algorithms that optimally balance this trade-off, it is necessary to extend our theoretical foundations. In this work, we formalize the personalized collaborative learning problem as stochastic optimization of a user's objective $f_0(x)$ while given access to $N$ related but different objectives of other users $\{f_1(x), \dots, f_N(x)\}$. We give convergence guarantees for two algorithms in this setting -- a popular personalization method known as \emph{weighted gradient averaging}, and a novel \emph{bias correction} method -- and explore conditions under which we can optimally trade-off their bias for a reduction in variance and achieve linear speedup w.r.t.\ the number of users $N$. Further, we also empirically study their performance confirming our theoretical insights.
Towards Model Agnostic Federated Learning Using Knowledge Distillation
Oct 28, 2021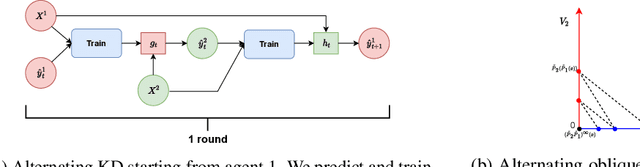
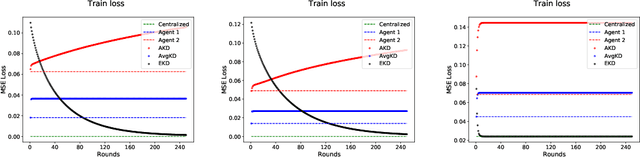
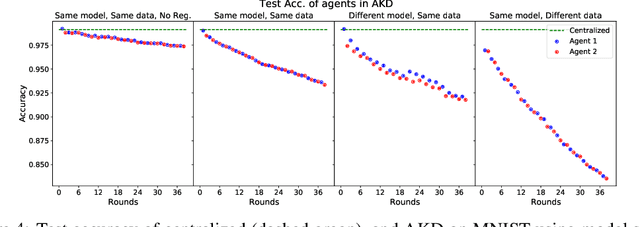
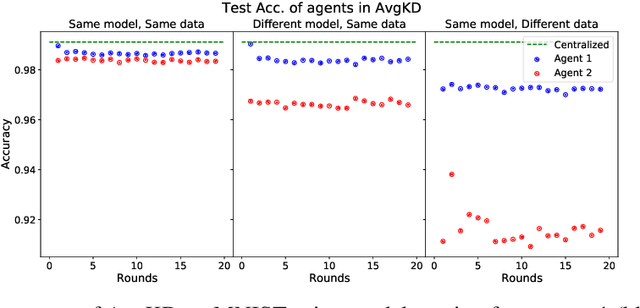
An often unquestioned assumption underlying most current federated learning algorithms is that all the participants use identical model architectures. In this work, we initiate a theoretical study of model agnostic communication protocols which would allow data holders (agents) using different models to collaborate with each other and perform federated learning. We focus on the setting where the two agents are attempting to perform kernel regression using different kernels (and hence have different models). Our study yields a surprising result -- the most natural algorithm of using alternating knowledge distillation (AKD) imposes overly strong regularization and may lead to severe under-fitting. Our theory also shows an interesting connection between AKD and the alternating projection algorithm for finding intersection of sets. Leveraging this connection, we propose a new algorithms which improve upon AKD. Our theoretical predictions also closely match real world experiments using neural networks. Thus, our work proposes a rich yet tractable framework for analyzing and developing new practical model agnostic federated learning algorithms.
RelaySum for Decentralized Deep Learning on Heterogeneous Data
Oct 08, 2021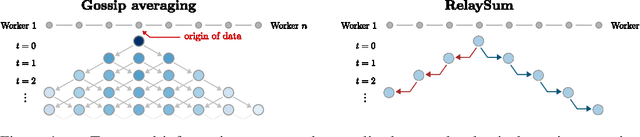
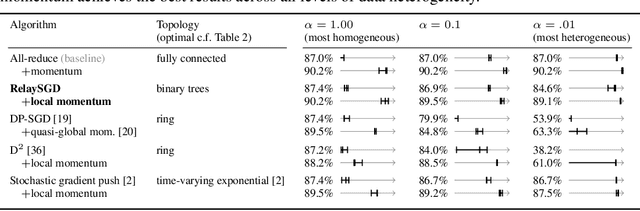
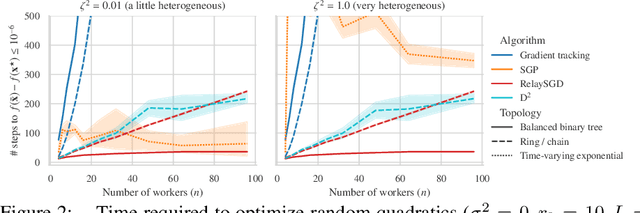

In decentralized machine learning, workers compute model updates on their local data. Because the workers only communicate with few neighbors without central coordination, these updates propagate progressively over the network. This paradigm enables distributed training on networks without all-to-all connectivity, helping to protect data privacy as well as to reduce the communication cost of distributed training in data centers. A key challenge, primarily in decentralized deep learning, remains the handling of differences between the workers' local data distributions. To tackle this challenge, we introduce the RelaySum mechanism for information propagation in decentralized learning. RelaySum uses spanning trees to distribute information exactly uniformly across all workers with finite delays depending on the distance between nodes. In contrast, the typical gossip averaging mechanism only distributes data uniformly asymptotically while using the same communication volume per step as RelaySum. We prove that RelaySGD, based on this mechanism, is independent of data heterogeneity and scales to many workers, enabling highly accurate decentralized deep learning on heterogeneous data. Our code is available at http://github.com/epfml/relaysgd.
A Field Guide to Federated Optimization
Jul 14, 2021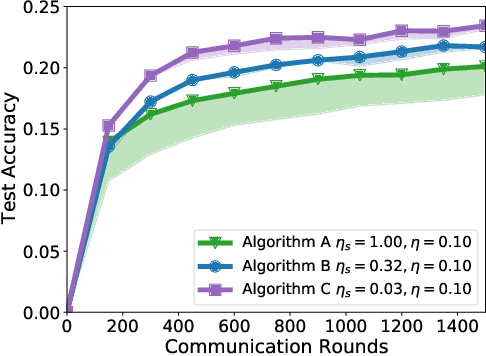


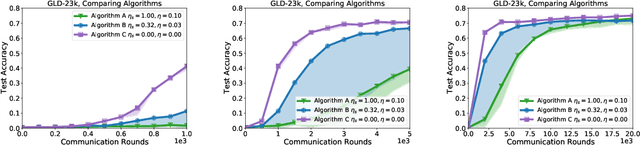
Federated learning and analytics are a distributed approach for collaboratively learning models (or statistics) from decentralized data, motivated by and designed for privacy protection. The distributed learning process can be formulated as solving federated optimization problems, which emphasize communication efficiency, data heterogeneity, compatibility with privacy and system requirements, and other constraints that are not primary considerations in other problem settings. This paper provides recommendations and guidelines on formulating, designing, evaluating and analyzing federated optimization algorithms through concrete examples and practical implementation, with a focus on conducting effective simulations to infer real-world performance. The goal of this work is not to survey the current literature, but to inspire researchers and practitioners to design federated learning algorithms that can be used in various practical applications.