 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharpness-Aware Parameter Selection for Machine Unlearning
Apr 08, 2025It often happens that some sensitive personal information, such as credit card numbers or passwords, are mistakenly incorporated in the training of machine learning models and need to be removed afterwards. The removal of such information from a trained model is a complex task that needs to partially reverse the training process. There have been various machine unlearning techniques proposed in the literature to address this problem. Most of the proposed methods revolve around removing individual data samples from a trained model. Another less explored direction is when features/labels of a group of data samples need to be reverted. While the existing methods for these tasks do the unlearning task by updating the whole set of model parameters or only the last layer of the model, we show that there are a subset of model parameters that have the largest contribution in the unlearning target features. More precisely, the model parameters with the largest corresponding diagonal value in the Hessian matrix (computed at the learned model parameter) have the most contribution in the unlearning task. By selecting these parameters and updating them during the unlearning stage, we can have the most progress in unlearning. We provide theoretical justifications for the proposed strategy by connecting it to sharpness-aware minimization and robust unlearning. We empirically show the effectiveness of the proposed strategy in improving the efficacy of unlearning with a low computational cost.
On the Implicit Relation Between Low-Rank Adaptation and Differential Privacy
Sep 26, 2024
A significant approach in natural language processing involves large-scale pre-training on general domain data followed by adaptation to specific tasks or domains. As models grow in size, full fine-tuning all parameters becomes increasingly impractical. To address this, some methods for low-rank task adaptation of language models have been proposed, e.g. LoRA and FLoRA. These methods keep the pre-trained model weights fixed and incorporate trainable low-rank decomposition matrices into some layers of the transformer architecture, called adapters. This approach significantly reduces the number of trainable parameters required for downstream tasks compared to full fine-tuning all parameters. In this work, we look at low-rank adaptation from the lens of data privacy. We show theoretically that the low-rank adaptation used in LoRA and FLoRA is equivalent to injecting some random noise into the batch gradients w.r.t the adapter parameters coming from their full fine-tuning, and we quantify the variance of the injected noise. By establishing a Berry-Esseen type bound on the total variation distance between the noise distribution and a Gaussian distribution with the same variance, we show that the dynamics of LoRA and FLoRA are very close to differentially private full fine-tuning the adapters, which suggests that low-rank adaptation implicitly provides privacy w.r.t the fine-tuning data. Finally, using Johnson-Lindenstrauss lemma, we show that when augmented with gradient clipping, low-rank adaptation is almost equivalent to differentially private full fine-tuning adapters with a fixed noise scale.
Semi-Variance Reduction for Fair Federated Learning
Jun 23, 2024



Ensuring fairness in a Federated Learning (FL) system, i.e., a satisfactory performance for all of the participating diverse clients, is an important and challenging problem. There are multiple fair FL algorithms in the literature, which have been relatively successful in providing fairness. However, these algorithms mostly emphasize on the loss functions of worst-off clients to improve their performance, which often results in the suppression of well-performing ones. As a consequence, they usually sacrifice the system's overall average performance for achieving fairness. Motivated by this and inspired by two well-known risk modeling methods in Finance, Mean-Variance and Mean-Semi-Variance, we propose and study two new fair FL algorithms, Variance Reduction (VRed) and Semi-Variance Reduction (SemiVRed). VRed encourages equality between clients' loss functions by penalizing their variance. In contrast, SemiVRed penalizes the discrepancy of only the worst-off clients' loss functions from the average loss. Through extensive experiments on multiple vision and language datasets, we show that, SemiVRed achieves SoTA performance in scenarios with heterogeneous data distributions and improves both fairness and system overall average performance.
Noise-Aware Algorithm for Heterogeneous Differentially Private Federated Learning
Jun 05, 2024High utility and rigorous data privacy are of the main goals of a federated learning (FL) system, which learns a model from the data distributed among some clients. The latter has been tried to achieve by using differential privacy in FL (DPFL). There is often heterogeneity in clients privacy requirements, and existing DPFL works either assume uniform privacy requirements for clients or are not applicable when server is not fully trusted (our setting). Furthermore, there is often heterogeneity in batch and/or dataset size of clients, which as shown, results in extra variation in the DP noise level across clients model updates. With these sources of heterogeneity, straightforward aggregation strategies, e.g., assigning clients aggregation weights proportional to their privacy parameters will lead to lower utility. We propose Robust-HDP, which efficiently estimates the true noise level in clients model updates and reduces the noise-level in the aggregated model updates considerably. Robust-HDP improves utility and convergence speed, while being safe to the clients that may maliciously send falsified privacy parameter to server. Extensive experimental results on multiple datasets and our theoretical analysis confirm the effectiveness of Robust-HDP. Our code can be found here.
Mitigating Disparate Impact of Differential Privacy in Federated Learning through Robust Clustering
May 29, 2024Federated Learning (FL) is a decentralized machine learning (ML) approach that keeps data localized and often incorporates Differential Privacy (DP) to enhance privacy guarantees. Similar to previous work on DP in ML, we observed that differentially private federated learning (DPFL) introduces performance disparities, particularly affecting minority groups. Recent work has attempted to address performance fairness in vanilla FL through clustering, but this method remains sensitive and prone to errors, which are further exacerbated by the DP noise in DPFL. To fill this gap, in this paper, we propose a novel clustered DPFL algorithm designed to effectively identify clients' clusters in highly heterogeneous settings while maintaining high accuracy with DP guarantees. To this end, we propose to cluster clients based on both their model updates and training loss values. Our proposed approach also addresses the server's uncertainties in clustering clients' model updates by employing larger batch sizes along with Gaussian Mixture Model (GMM) to alleviate the impact of noise and potential clustering errors, especially in privacy-sensitive scenarios. We provide theoretical analysis of the effectiveness of our proposed approach. We also extensively evaluate our approach across diverse data distributions and privacy budgets and show its effectiveness in mitigating the disparate impact of DP in FL settings with a small computational cost.
Equality Is Not Equity: Proportional Fairness in Federated Learning
Feb 03, 2022

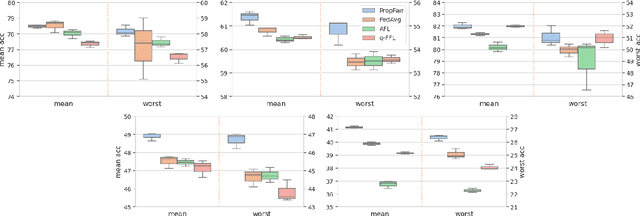
Ensuring fairness of machine learning (ML) algorithms is becoming an increasingly important mission for ML service providers. This is even more critical and challenging in the federated learning (FL) scenario, given a large number of diverse participating clients. Simply mandating equality across clients could lead to many undesirable consequences, potentially discouraging high-performing clients and resulting in sub-optimal overall performance. In order to achieve better equity rather than equality, in this work, we introduce and study proportional fairness (PF) in FL, which has a deep connection with game theory. By viewing FL from a cooperative game perspective, where the players (clients) collaboratively learn a good model, we formulate PF as Nash bargaining solutions. Based on this concept, we propose PropFair, a novel and easy-to-implement algorithm for effectively finding PF solutions, and we prove its convergence properties. We illustrate through experiments that PropFair consistently improves the worst-case and the overall performances simultaneously over state-of-the-art fair FL algorithms for a wide array of vision and language datasets, thus achieving better equity.
An Operator Splitting View of Federated Learning
Aug 12, 2021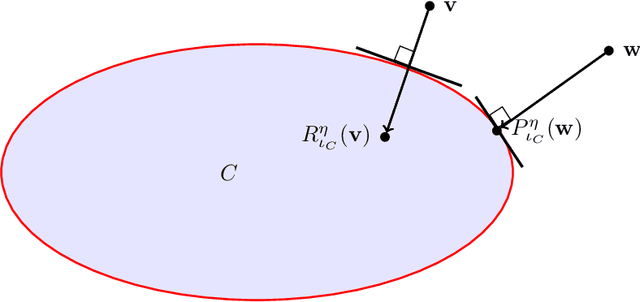
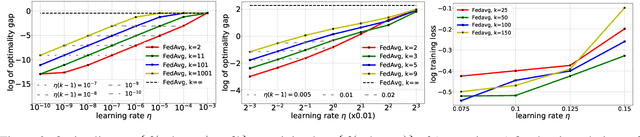
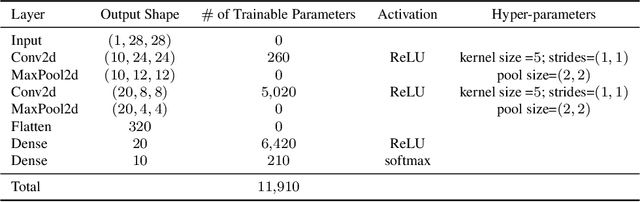

Over the past few years, the federated learning ($\texttt{FL}$) community has witnessed a proliferation of new $\texttt{FL}$ algorithms. However, our understating of the theory of $\texttt{FL}$ is still fragmented, and a thorough, formal comparison of these algorithms remains elusive. Motivated by this gap, we show that many of the existing $\texttt{FL}$ algorithms can be understood from an operator splitting point of view. This unification allows us to compare different algorithms with ease, to refine previous convergence results and to uncover new algorithmic variants. In particular, our analysis reveals the vital role played by the step size in $\texttt{FL}$ algorithms. The unification also leads to a streamlined and economic way to accelerate $\texttt{FL}$ algorithms, without incurring any communication overhead. We perform numerical experiments on both convex and nonconvex models to validate our findings.
PePScenes: A Novel Dataset and Baseline for Pedestrian Action Prediction in 3D
Dec 14, 2020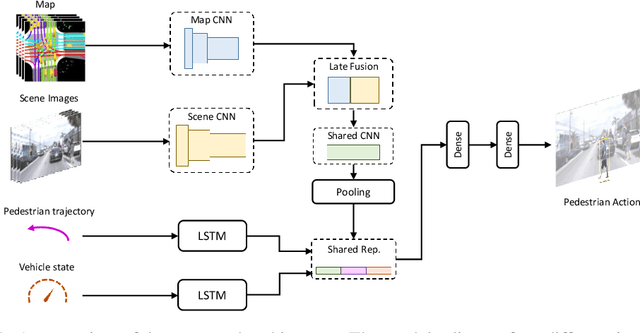
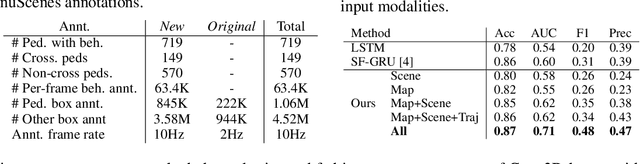
Predicting the behavior of road users, particularly pedestrians, is vital for safe motion planning in the context of autonomous driving systems. Traditionally, pedestrian behavior prediction has been realized in terms of forecasting future trajectories. However, recent evidence suggests that predicting higher-level actions, such as crossing the road, can help improve trajectory forecasting and planning tasks accordingly. There are a number of existing datasets that cater to the development of pedestrian action prediction algorithms, however, they lack certain characteristics, such as bird's eye view semantic map information, 3D locations of objects in the scene, etc., which are crucial in the autonomous driving context. To this end, we propose a new pedestrian action prediction dataset created by adding per-frame 2D/3D bounding box and behavioral annotations to the popular autonomous driving dataset, nuScenes. In addition, we propose a hybrid neural network architecture that incorporates various data modalities for predicting pedestrian crossing action. By evaluating our model on the newly proposed dataset, the contribution of different data modalities to the prediction task is revealed. The dataset is available at https://github.com/huawei-noah/PePScenes.
Graph-SIM: A Graph-based Spatiotemporal Interaction Modelling for Pedestrian Action Prediction
Dec 03, 2020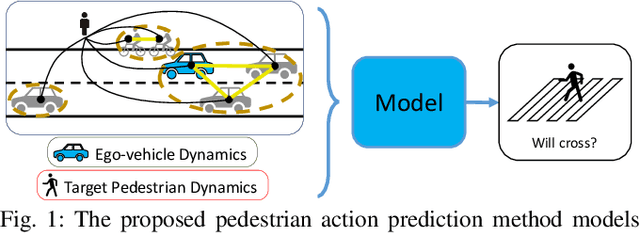
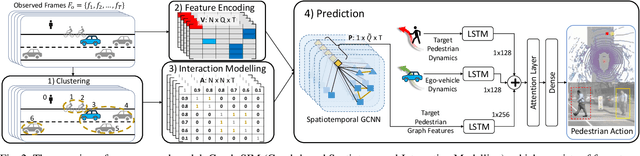
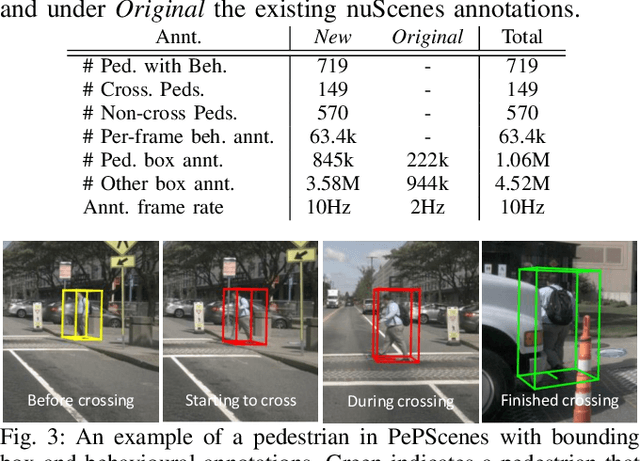
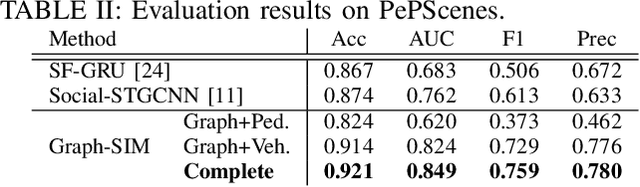
One of the most crucial yet challenging tasks for autonomous vehicles in urban environments is predicting the future behaviour of nearby pedestrians, especially at points of crossing. Predicting behaviour depends on many social and environmental factors, particularly interactions between road users. Capturing such interactions requires a global view of the scene and dynamics of the road users in three-dimensional space. This information, however, is missing from the current pedestrian behaviour benchmark datasets. Motivated by these challenges, we propose 1) a novel graph-based model for predicting pedestrian crossing action. Our method models pedestrians' interactions with nearby road users through clustering and relative importance weighting of interactions using features obtained from the bird's-eye-view. 2) We introduce a new dataset that provides 3D bounding box and pedestrian behavioural annotations for the existing nuScenes dataset. On the new data, our approach achieves state-of-the-art performance by improving on various metrics by more than 10% in comparison to existing methods. Upon publishing of this paper, our dataset will be made publicly available.
Non-Parametric Graph Learning for Bayesian Graph Neural Networks
Jun 23, 2020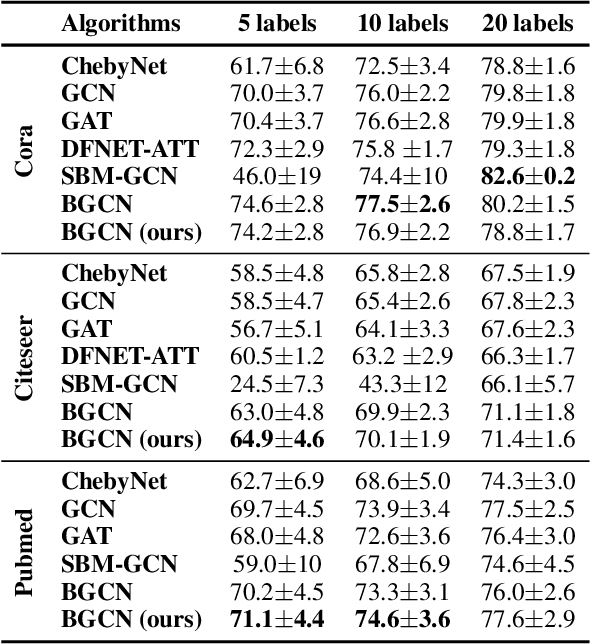
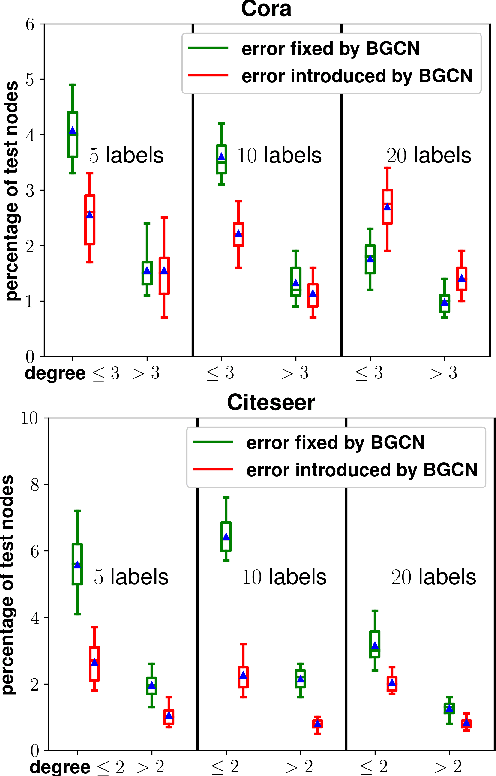
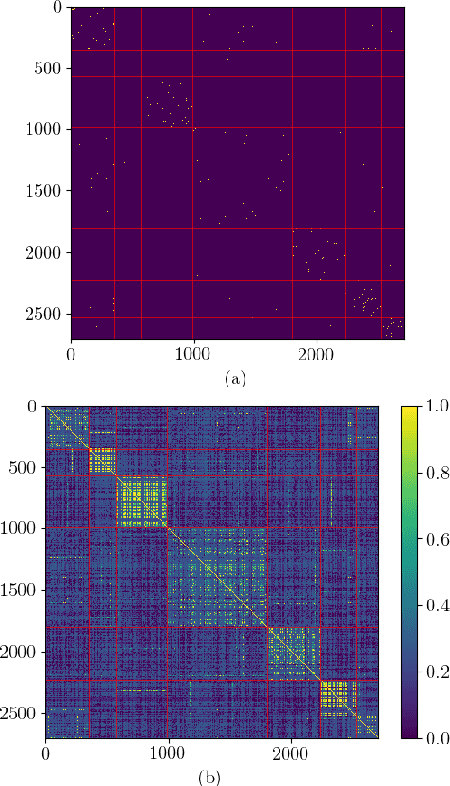
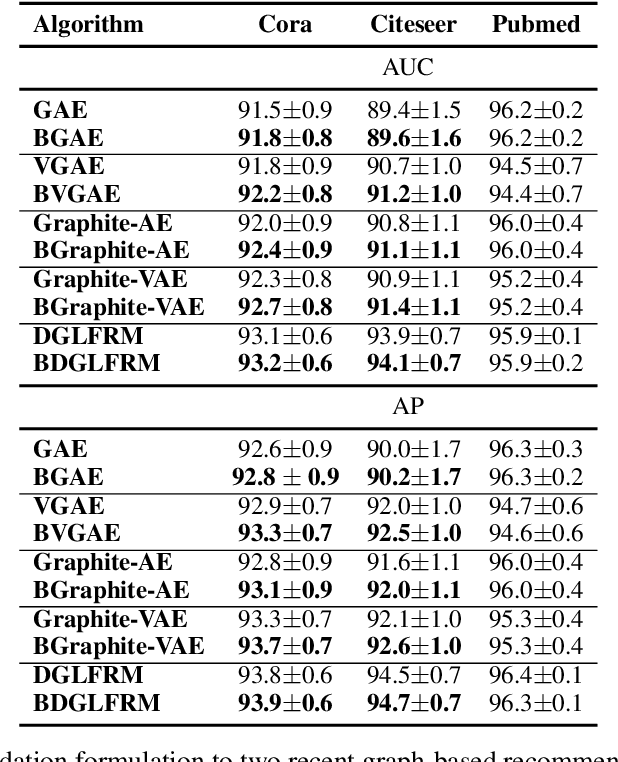
Graphs are ubiquitous in modelling relational structures. Recent endeavours in machine learning for graph-structured data have led to many architectures and learning algorithms. However, the graph used by these algorithms is often constructed based on inaccurate modelling assumptions and/or noisy data. As a result, it fails to represent the true relationships between nodes. A Bayesian framework which targets posterior inference of the graph by considering it as a random quantity can be beneficial. In this paper, we propose a novel non-parametric graph model for constructing the posterior distribution of graph adjacency matrices. The proposed model is flexible in the sense that it can effectively take into account the output of graph-based learning algorithms that target specific tasks. In addition, model inference scales well to large graphs. We demonstrate the advantages of this model in three different problem settings: node classification, link prediction and recommendation.