 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Knowledge-Driven Approach to Music Segmentation, Music Source Separation and Cinematic Audio Source Separation
Feb 25, 2026We propose a knowledge-driven, model-based approach to segmenting audio into single-category and mixed-category chunks with applications to source separation. "Knowledge" here denotes information associated with the data, such as music scores. "Model" here refers to tool that can be used for audio segmentation and recognition, such as hidden Markov models. In contrast to conventional learning that often relies on annotated data with given segment categories and their corresponding boundaries to guide the learning process, the proposed framework does not depend on any pre-segmented training data and learns directly from the input audio and its related knowledge sources to build all necessary models autonomously. Evaluation on simulation data shows that score-guided learning achieves very good music segmentation and separation results. Tested on movie track data for cinematic audio source separation also shows that utilizing sound category knowledge achieves better separation results than those obtained with data-driven techniques without using such information.
MDM-ASR: Bridging Accuracy and Efficiency in ASR with Diffusion-Based Non-Autoregressive Decoding
Feb 24, 2026In sequence-to-sequence Transformer ASR, autoregressive (AR) models achieve strong accuracy but suffer from slow decoding, while non-autoregressive (NAR) models enable parallel decoding at the cost of degraded performance. We propose a principled NAR ASR framework based on Masked Diffusion Models to reduce this gap. A pre-trained speech encoder is coupled with a Transformer diffusion decoder conditioned on acoustic features and partially masked transcripts for parallel token prediction. To mitigate the training-inference mismatch, we introduce Iterative Self-Correction Training that exposes the model to its own intermediate predictions. We also design a Position-Biased Entropy-Bounded Confidence-based sampler with positional bias to further boost results. Experiments across multiple benchmarks demonstrate consistent gains over prior NAR models and competitive performance with strong AR baselines, while retaining parallel decoding efficiency.
A Bottom-up Framework with Language-universal Speech Attribute Modeling for Syllable-based ASR
Sep 09, 2025We propose a bottom-up framework for automatic speech recognition (ASR) in syllable-based languages by unifying language-universal articulatory attribute modeling with syllable-level prediction. The system first recognizes sequences or lattices of articulatory attributes that serve as a language-universal, interpretable representation of pronunciation, and then transforms them into syllables through a structured knowledge integration process. We introduce two evaluation metrics, namely Pronunciation Error Rate (PrER) and Syllable Homonym Error Rate (SHER), to evaluate the model's ability to capture pronunciation and handle syllable ambiguities. Experimental results on the AISHELL-1 Mandarin corpus demonstrate that the proposed bottom-up framework achieves competitive performance and exhibits better robustness under low-resource conditions compared to the direct syllable prediction model. Furthermore, we investigate the zero-shot cross-lingual transferability on Japanese and demonstrate significant improvements over character- and phoneme-based baselines by 40% error rate reduction.
An Investigation on Combining Geometry and Consistency Constraints into Phase Estimation for Speech Enhancement
Jul 02, 2025



We propose a novel iterative phase estimation framework, termed multi-source Griffin-Lim algorithm (MSGLA), for speech enhancement (SE) under additive noise conditions. The core idea is to leverage the ad-hoc consistency constraint of complex-valued short-time Fourier transform (STFT) spectrograms to address the sign ambiguity challenge commonly encountered in geometry-based phase estimation. Furthermore, we introduce a variant of the geometric constraint framework based on the law of sines and cosines, formulating a new phase reconstruction algorithm using noise phase estimates. We first validate the proposed technique through a series of oracle experiments, demonstrating its effectiveness under ideal conditions. We then evaluate its performance on the VB-DMD and WSJ0-CHiME3 data sets, and show that the proposed MSGLA variants match well or slightly outperform existing algorithms, including direct phase estimation and DNN-based sign prediction, especially in terms of background noise suppression.
Towards Robust Assessment of Pathological Voices via Combined Low-Level Descriptors and Foundation Model Representations
May 30, 2025



Perceptual voice quality assessment is essential for diagnosing and monitoring voice disorders by providing standardized evaluations of vocal function. Traditionally, expert raters use standard scales such as the Consensus Auditory-Perceptual Evaluation of Voice (CAPE-V) and Grade, Roughness, Breathiness, Asthenia, and Strain (GRBAS). However, these metrics are subjective and prone to inter-rater variability, motivating the need for automated, objective assessment methods. This study proposes Voice Quality Assessment Network (VOQANet), a deep learning-based framework with an attention mechanism that leverages a Speech Foundation Model (SFM) to extract high-level acoustic and prosodic information from raw speech. To enhance robustness and interpretability, we also introduce VOQANet+, which integrates low-level speech descriptors such as jitter, shimmer, and harmonics-to-noise ratio (HNR) with SFM embeddings into a hybrid representation. Unlike prior studies focused only on vowel-based phonation (PVQD-A subset) of the Perceptual Voice Quality Dataset (PVQD), we evaluate our models on both vowel-based and sentence-level speech (PVQD-S subset) to improve generalizability. Results show that sentence-based input outperforms vowel-based input, especially at the patient level, underscoring the value of longer utterances for capturing perceptual voice attributes. VOQANet consistently surpasses baseline methods in root mean squared error (RMSE) and Pearson correlation coefficient (PCC) across CAPE-V and GRBAS dimensions, with VOQANet+ achieving even better performance. Additional experiments under noisy conditions show that VOQANet+ maintains high prediction accuracy and robustness, supporting its potential for real-world and telehealth deployment.
Towards Robust Automated Perceptual Voice Quality Assessment with Speech Foundation Models
May 28, 2025Perceptual voice quality assessment is essential for diagnosing and monitoring voice disorders. Traditionally, expert raters use scales such as the CAPE-V and GRBAS. However, these are subjective and prone to inter-rater variability, motivating the need for automated, objective assessment methods. This study proposes VOQANet, a deep learning framework with an attention mechanism that leverages a Speech Foundation Model (SFM) to extract high-level acoustic and prosodic information from raw speech. To improve robustness and interpretability, we introduce VOQANet+, which integrates handcrafted acoustic features such as jitter, shimmer, and harmonics-to-noise ratio (HNR) with SFM embeddings into a hybrid representation. Unlike prior work focusing only on vowel-based phonation (PVQD-A subset) from the Perceptual Voice Quality Dataset (PVQD), we evaluate our models on both vowel-based and sentence-level speech (PVQD-S subset) for better generalizability. Results show that sentence-based input outperforms vowel-based input, particularly at the patient level, highlighting the benefit of longer utterances for capturing voice attributes. VOQANet consistently surpasses baseline methods in root mean squared error and Pearson correlation across CAPE-V and GRBAS dimensions, with VOQANet+ achieving further improvements. Additional tests under noisy conditions show that VOQANet+ maintains high prediction accuracy, supporting its use in real-world and telehealth settings. These findings demonstrate the value of combining SFM embeddings with domain-informed acoustic features for interpretable and robust voice quality assessment.
MVP: Multi-source Voice Pathology detection
May 26, 2025Voice disorders significantly impact patient quality of life, yet non-invasive automated diagnosis remains under-explored due to both the scarcity of pathological voice data, and the variability in recording sources. This work introduces MVP (Multi-source Voice Pathology detection), a novel approach that leverages transformers operating directly on raw voice signals. We explore three fusion strategies to combine sentence reading and sustained vowel recordings: waveform concatenation, intermediate feature fusion, and decision-level combination. Empirical validation across the German, Portuguese, and Italian languages shows that intermediate feature fusion using transformers best captures the complementary characteristics of both recording types. Our approach achieves up to +13% AUC improvement over single-source methods.
Exploring Generative Error Correction for Dysarthric Speech Recognition
May 26, 2025Despite the remarkable progress in end-to-end Automatic Speech Recognition (ASR) engines, accurately transcribing dysarthric speech remains a major challenge. In this work, we proposed a two-stage framework for the Speech Accessibility Project Challenge at INTERSPEECH 2025, which combines cutting-edge speech recognition models with LLM-based generative error correction (GER). We assess different configurations of model scales and training strategies, incorporating specific hypothesis selection to improve transcription accuracy. Experiments on the Speech Accessibility Project dataset demonstrate the strength of our approach on structured and spontaneous speech, while highlighting challenges in single-word recognition. Through comprehensive analysis, we provide insights into the complementary roles of acoustic and linguistic modeling in dysarthric speech recognition
"KAN you hear me?" Exploring Kolmogorov-Arnold Networks for Spoken Language Understanding
May 26, 2025



Kolmogorov-Arnold Networks (KANs) have recently emerged as a promising alternative to traditional neural architectures, yet their application to speech processing remains under explored. This work presents the first investigation of KANs for Spoken Language Understanding (SLU) tasks. We experiment with 2D-CNN models on two datasets, integrating KAN layers in five different configurations within the dense block. The best-performing setup, which places a KAN layer between two linear layers, is directly applied to transformer-based models and evaluated on five SLU datasets with increasing complexity. Our results show that KAN layers can effectively replace the linear layers, achieving comparable or superior performance in most cases. Finally, we provide insights into how KAN and linear layers on top of transformers differently attend to input regions of the raw waveforms.
Variational Bayesian Adaptive Learning of Deep Latent Variables for Acoustic Knowledge Transfer
Jan 26, 2025
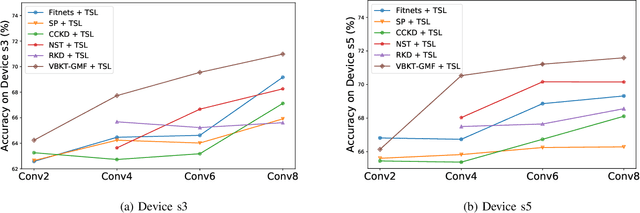

In this work, we propose a novel variational Bayesian adaptive learning approach for cross-domain knowledge transfer to address acoustic mismatches between training and testing conditions, such as recording devices and environmental noise. Different from the traditional Bayesian approaches that impose uncertainties on model parameters risking the curse of dimensionality due to the huge number of parameters, we focus on estimating a manageable number of latent variables in deep neural models. Knowledge learned from a source domain is thus encoded in prior distributions of deep latent variables and optimally combined, in a Bayesian sense, with a small set of adaptation data from a target domain to approximate the corresponding posterior distributions. Two different strategies are proposed and investigated to estimate the posterior distributions: Gaussian mean-field variational inference, and empirical Bayes. These strategies address the presence or absence of parallel data in the source and target domains. Furthermore, structural relationship modeling is investigated to enhance the approximation. We evaluated our proposed approaches on two acoustic adaptation tasks: 1) device adaptation for acoustic scene classification, and 2) noise adaptation for spoken command recognition. Experimental results show that the proposed variational Bayesian adaptive learning approach can obtain good improvements on target domain data, and consistently outperforms state-of-the-art knowledge transfer methods.