 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Concept-based approach to Voice Disorder Detection
Jul 23, 2025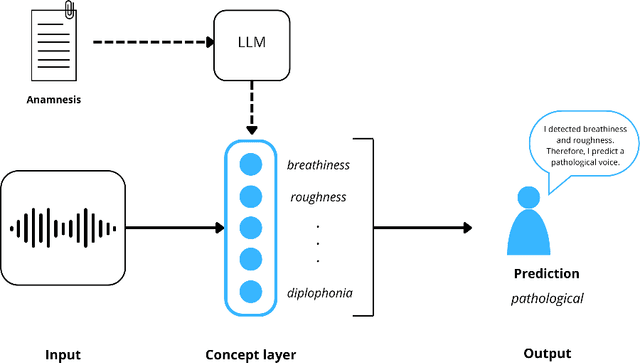
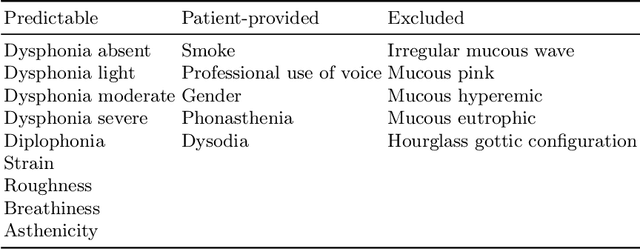


Voice disorders affect a significant portion of the population, and the ability to diagnose them using automated, non-invasive techniques would represent a substantial advancement in healthcare, improving the quality of life of patients. Recent studies have demonstrated that artificial intelligence models, particularly Deep Neural Networks (DNNs), can effectively address this task. However, due to their complexity, the decision-making process of such models often remain opaque, limiting their trustworthiness in clinical contexts. This paper investigates an alternative approach based on Explainable AI (XAI), a field that aims to improve the interpretability of DNNs by providing different forms of explanations. Specifically, this works focuses on concept-based models such as Concept Bottleneck Model (CBM) and Concept Embedding Model (CEM) and how they can achieve performance comparable to traditional deep learning methods, while offering a more transparent and interpretable decision framework.
MVP: Multi-source Voice Pathology detection
May 26, 2025Voice disorders significantly impact patient quality of life, yet non-invasive automated diagnosis remains under-explored due to both the scarcity of pathological voice data, and the variability in recording sources. This work introduces MVP (Multi-source Voice Pathology detection), a novel approach that leverages transformers operating directly on raw voice signals. We explore three fusion strategies to combine sentence reading and sustained vowel recordings: waveform concatenation, intermediate feature fusion, and decision-level combination. Empirical validation across the German, Portuguese, and Italian languages shows that intermediate feature fusion using transformers best captures the complementary characteristics of both recording types. Our approach achieves up to +13% AUC improvement over single-source methods.
Voice Disorder Analysis: a Transformer-based Approach
Jun 20, 2024



Voice disorders are pathologies significantly affecting patient quality of life. However, non-invasive automated diagnosis of these pathologies is still under-explored, due to both a shortage of pathological voice data, and diversity of the recording types used for the diagnosis. This paper proposes a novel solution that adopts transformers directly working on raw voice signals and addresses data shortage through synthetic data generation and data augmentation. Further, we consider many recording types at the same time, such as sentence reading and sustained vowel emission, by employing a Mixture of Expert ensemble to align the predictions on different data types. The experimental results, obtained on both public and private datasets, show the effectiveness of our solution in the disorder detection and classification tasks and largely improve over existing approaches.