 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNondiagonal Mixture of Dirichlet Network Distributions for Analyzing a Stock Ownership Network
Sep 08, 2020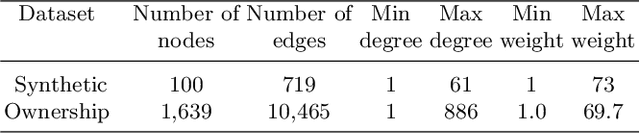
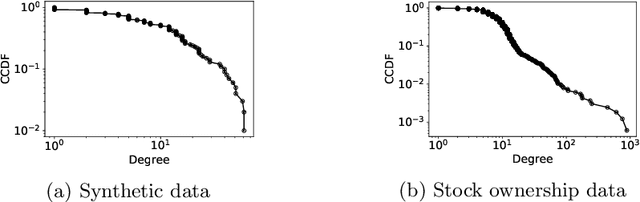
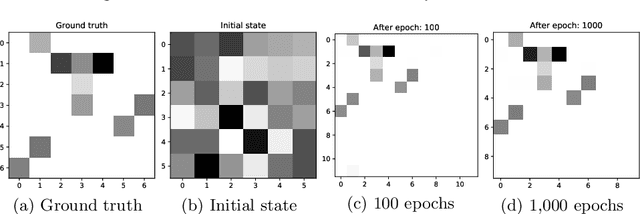
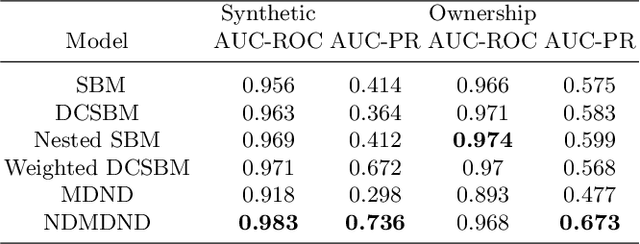
Block modeling is widely used in studies on complex networks. The cornerstone model is the stochastic block model (SBM), widely used over the past decades. However, the SBM is limited in analyzing complex networks as the model is, in essence, a random graph model that cannot reproduce the basic properties of many complex networks, such as sparsity and heavy-tailed degree distribution. In this paper, we provide an edge exchangeable block model that incorporates such basic features and simultaneously infers the latent block structure of a given complex network. Our model is a Bayesian nonparametric model that flexibly estimates the number of blocks and takes into account the possibility of unseen nodes. Using one synthetic dataset and one real-world stock ownership dataset, we show that our model outperforms state-of-the-art SBMs for held-out link prediction tasks.
Gaussian Hierarchical Latent Dirichlet Allocation: Bringing Polysemy Back
Feb 25, 2020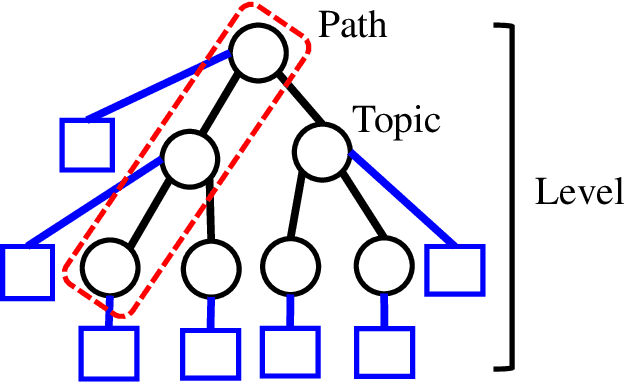
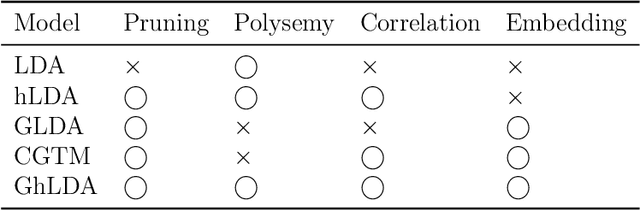
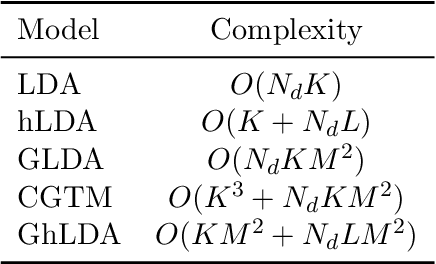
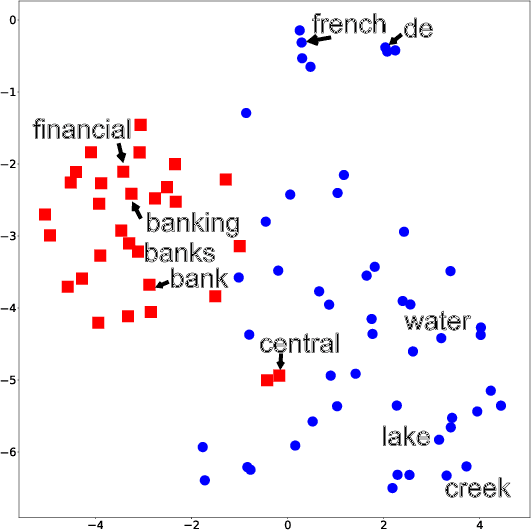
Topic models are widely used to discover the latent representation of a set of documents. The two canonical models are latent Dirichlet allocation, and Gaussian latent Dirichlet allocation, where the former uses multinomial distributions over words, and the latter uses multivariate Gaussian distributions over pre-trained word embedding vectors as the latent topic representations, respectively. Compared with latent Dirichlet allocation, Gaussian latent Dirichlet allocation is limited in the sense that it does not capture the polysemy of a word such as ``bank.'' In this paper, we show that Gaussian latent Dirichlet allocation could recover the ability to capture polysemy by introducing a hierarchical structure in the set of topics that the model can use to represent a given document. Our Gaussian hierarchical latent Dirichlet allocation significantly improves polysemy detection compared with Gaussian-based models and provides more parsimonious topic representations compared with hierarchical latent Dirichlet allocation. Our extensive quantitative experiments show that our model also achieves better topic coherence and held-out document predictive accuracy over a wide range of corpus and word embedding vectors.
High quality topic extraction from business news explains abnormal financial market volatility
Mar 23, 2013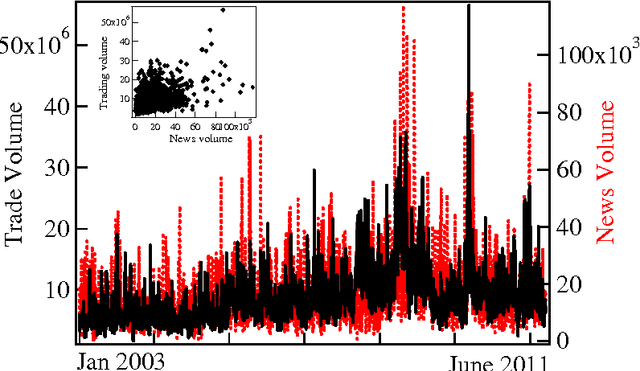
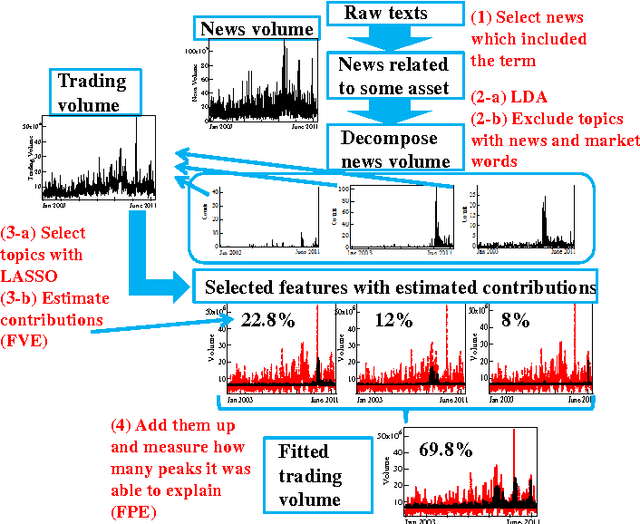
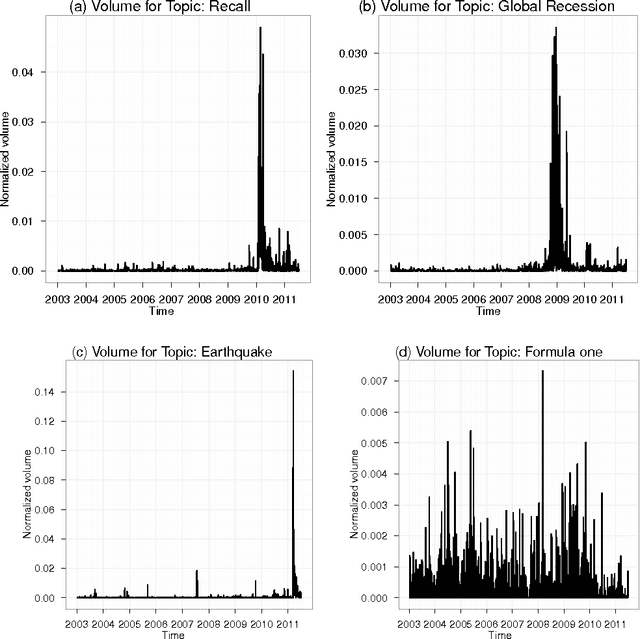
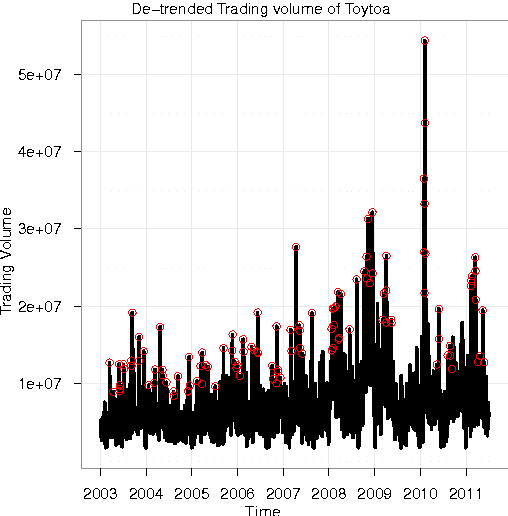
Understanding the mutual relationships between information flows and social activity in society today is one of the cornerstones of the social sciences. In financial economics, the key issue in this regard is understanding and quantifying how news of all possible types (geopolitical, environmental, social, financial, economic, etc.) affect trading and the pricing of firms in organized stock markets. In this article, we seek to address this issue by performing an analysis of more than 24 million news records provided by Thompson Reuters and of their relationship with trading activity for 206 major stocks in the S&P US stock index. We show that the whole landscape of news that affect stock price movements can be automatically summarized via simple regularized regressions between trading activity and news information pieces decomposed, with the help of simple topic modeling techniques, into their "thematic" features. Using these methods, we are able to estimate and quantify the impacts of news on trading. We introduce network-based visualization techniques to represent the whole landscape of news information associated with a basket of stocks. The examination of the words that are representative of the topic distributions confirms that our method is able to extract the significant pieces of information influencing the stock market. Our results show that one of the most puzzling stylized fact in financial economies, namely that at certain times trading volumes appear to be "abnormally large," can be partially explained by the flow of news. In this sense, our results prove that there is no "excess trading," when restricting to times when news are genuinely novel and provide relevant financial information.