 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapturing Legal Reasoning Paths from Facts to Law in Court Judgments using Knowledge Graphs
Aug 24, 2025Court judgments reveal how legal rules have been interpreted and applied to facts, providing a foundation for understanding structured legal reasoning. However, existing automated approaches for capturing legal reasoning, including large language models, often fail to identify the relevant legal context, do not accurately trace how facts relate to legal norms, and may misrepresent the layered structure of judicial reasoning. These limitations hinder the ability to capture how courts apply the law to facts in practice. In this paper, we address these challenges by constructing a legal knowledge graph from 648 Japanese administrative court decisions. Our method extracts components of legal reasoning using prompt-based large language models, normalizes references to legal provisions, and links facts, norms, and legal applications through an ontology of legal inference. The resulting graph captures the full structure of legal reasoning as it appears in real court decisions, making implicit reasoning explicit and machine-readable. We evaluate our system using expert annotated data, and find that it achieves more accurate retrieval of relevant legal provisions from facts than large language model baselines and retrieval-augmented methods.
Hierarchical Narrative Analysis: Unraveling Perceptions of Generative AI
Sep 17, 2024



Written texts reflect an author's perspective, making the thorough analysis of literature a key research method in fields such as the humanities and social sciences. However, conventional text mining techniques like sentiment analysis and topic modeling are limited in their ability to capture the hierarchical narrative structures that reveal deeper argumentative patterns. To address this gap, we propose a method that leverages large language models (LLMs) to extract and organize these structures into a hierarchical framework. We validate this approach by analyzing public opinions on generative AI collected by Japan's Agency for Cultural Affairs, comparing the narratives of supporters and critics. Our analysis provides clearer visualization of the factors influencing divergent opinions on generative AI, offering deeper insights into the structures of agreement and disagreement.
Gaussian Hierarchical Latent Dirichlet Allocation: Bringing Polysemy Back
Feb 25, 2020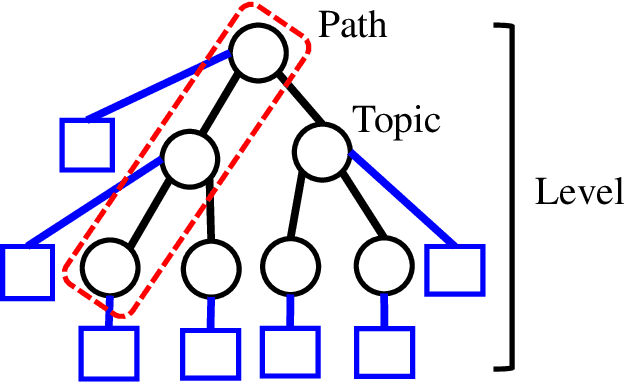
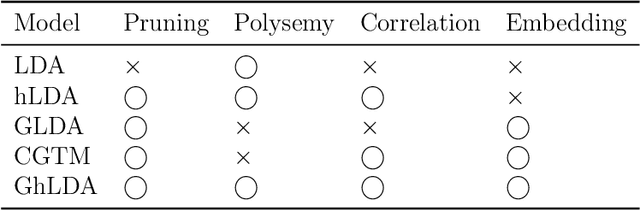
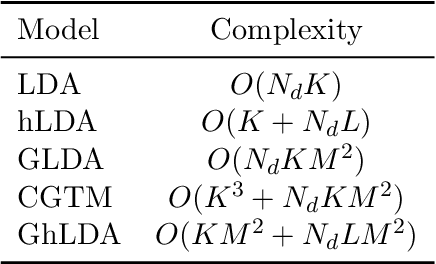
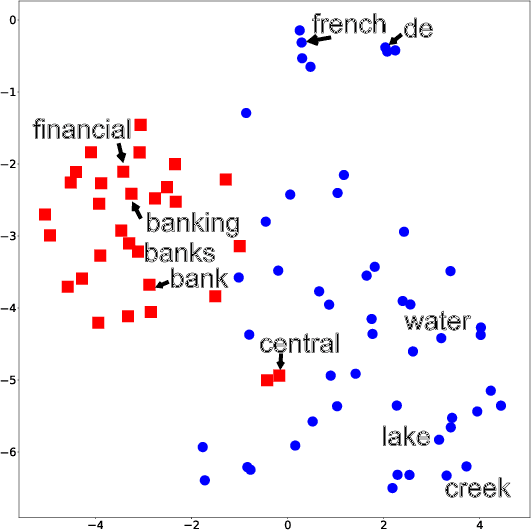
Topic models are widely used to discover the latent representation of a set of documents. The two canonical models are latent Dirichlet allocation, and Gaussian latent Dirichlet allocation, where the former uses multinomial distributions over words, and the latter uses multivariate Gaussian distributions over pre-trained word embedding vectors as the latent topic representations, respectively. Compared with latent Dirichlet allocation, Gaussian latent Dirichlet allocation is limited in the sense that it does not capture the polysemy of a word such as ``bank.'' In this paper, we show that Gaussian latent Dirichlet allocation could recover the ability to capture polysemy by introducing a hierarchical structure in the set of topics that the model can use to represent a given document. Our Gaussian hierarchical latent Dirichlet allocation significantly improves polysemy detection compared with Gaussian-based models and provides more parsimonious topic representations compared with hierarchical latent Dirichlet allocation. Our extensive quantitative experiments show that our model also achieves better topic coherence and held-out document predictive accuracy over a wide range of corpus and word embedding vectors.